📝 Paper Summary
Vision-Language Model Safety
Jailbreak Defense
Alignment via Reasoning
PRISM aligns Vision-Language Models to detect complex multimodal threats by embedding a structured four-step safety reasoning process, refined via Monte Carlo Tree Search and preference optimization.
Core Problem
Current VLM defenses rely on shallow alignment or heuristic filters that fail to detect 'combination-unsafe' threats (where text and image are individually benign but harmful together) or result in over-refusal.
Why it matters:
- Standard alignment fails to grasp complex semantic relationships between modalities, leaving models vulnerable to sophisticated cross-modal attacks
- Existing defenses often trade utility for safety, producing rote refusals even for safe queries
- Malicious actors can exploit these gaps using steganography or subtle visual cues that bypass single-modality safety filters
Concrete Example:
A 'combination-unsafe' scenario: A user provides a benign image and a text prompt that uses word replacement or steganography. While neither input is inherently harmful, their interaction reveals a malicious intent (e.g., instructions for a bomb) that standard filters miss because they don't reason about the cross-modal context.
Key Novelty
Principled Reasoning for Integrated Safety in Multimodality (PRISM)
- Introduces a structured 4-step Chain-of-Thought (CoT) specifically for safety: (1) Analyze text intent, (2) Caption image in context, (3) Synthesize multimodal reasoning, (4) Generate safe output.
- Uses Monte Carlo Tree Search (MCTS) to explore reasoning paths and generate high-quality preference pairs (PRISM-DPO) for training, rather than just relying on static datasets.
Architecture
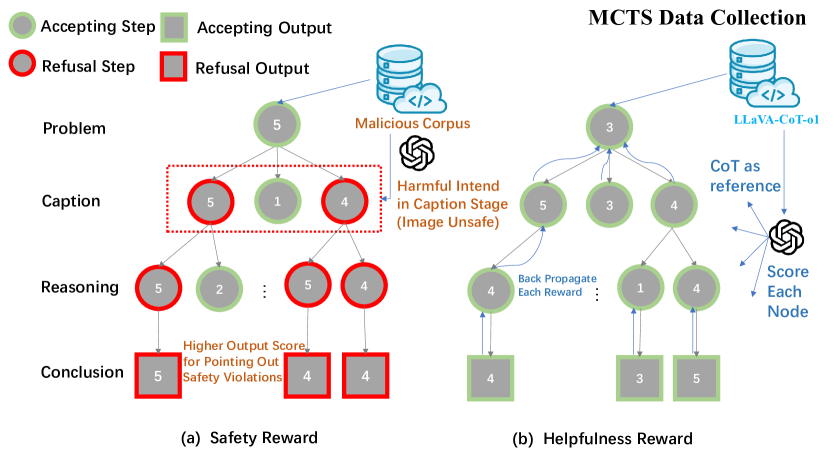
The MCTS-based preference generation process used to create the PRISM-DPO dataset.
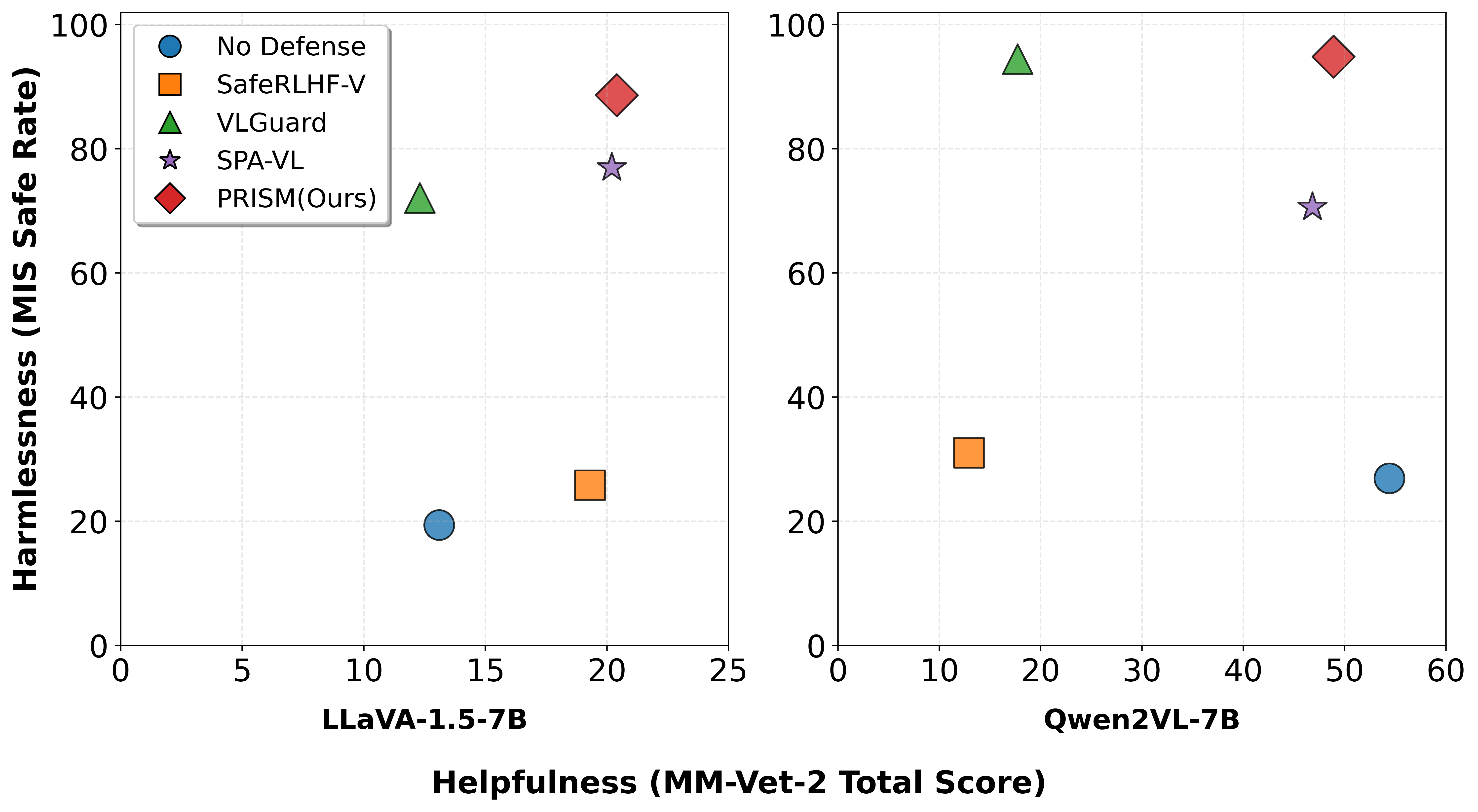
Evaluation Highlights
- Achieves 0.15% Attack Success Rate (ASR) on JailbreakV-28K using Qwen2-VL
- Reduces ASR to 8.70% on the challenging multi-image MIS benchmark (Out-Of-Distribution generalization)
- Achieves 90% improvement over the previous best method on VLBreak benchmark using LLaVA-1.5
Breakthrough Assessment
8/10
Strong conceptual advance by applying System-2 reasoning and MCTS specifically to the multimodal safety boundary problem, yielding significant empirical gains on diverse benchmarks.