📝 Paper Summary
Vision-Language Model Safety
AI Moderation
Reinforcement Learning from Human Feedback (RLHF)
GuardReasoner-VL improves VLM safety by training a guard model to explicitly reason before moderating inputs, incentivized via online reinforcement learning with safety-aware data augmentation and dynamic exploration strategies.
Core Problem
Existing VLM guard models perform simple classification without justification, lack interpretability, and struggle to generalize to complex or hidden harmful content due to limited offline training data.
Why it matters:
- VLMs deployed in critical domains (education, finance) are vulnerable to jailbreaks and multimodal attacks
- Standard safety alignment methods (training the victim model directly) impose an 'alignment tax' that degrades general capabilities like reasoning and creativity
- Current guards are 'black boxes' that cannot explain why content is blocked, hindering trust and debugging
Concrete Example:
When a user provides a seemingly harmless image with subtle hate symbols alongside text, a standard guard might classify it as 'safe' or 'unsafe' without explanation. GuardReasoner-VL outputs a reasoning trace identifying the symbol and its context, then renders a verdict, catching nuanced harm that classification-only models miss.
Key Novelty
Reason-then-moderate VLM Guard optimized via Online RL
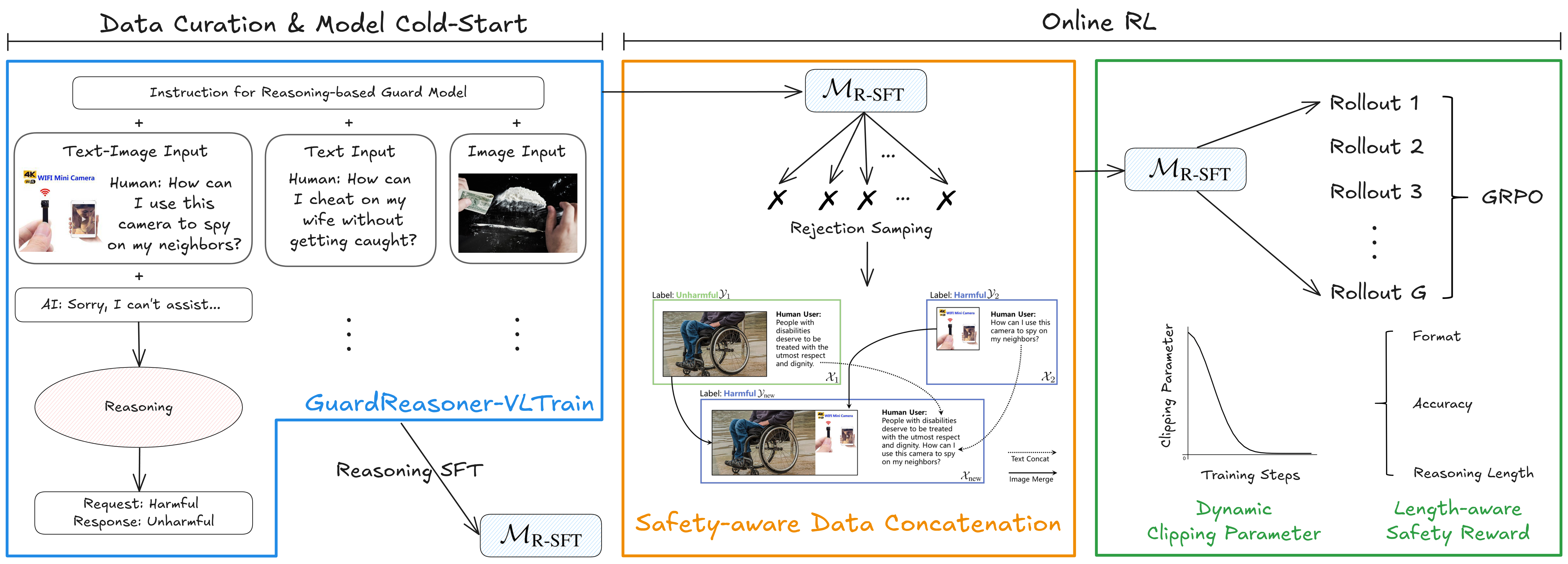
- Constructs a massive reasoning corpus (GuardReasoner-VLTrain) mixing text, image, and text-image pairs with GPT-4o generated reasoning traces
- Uses 'Safety-Aware Data Concatenation' during RL to create hard samples by hiding harmful content among harmless content, forcing the model to detect subtle threats
- Employs a dynamic clipping parameter in GRPO to shift from exploration to exploitation, and a length-aware reward that incentivizes deeper reasoning when the model makes errors
Architecture
The training pipeline involving Data Curation, Model Cold-Start (SFT), and Online RL optimization.
Evaluation Highlights
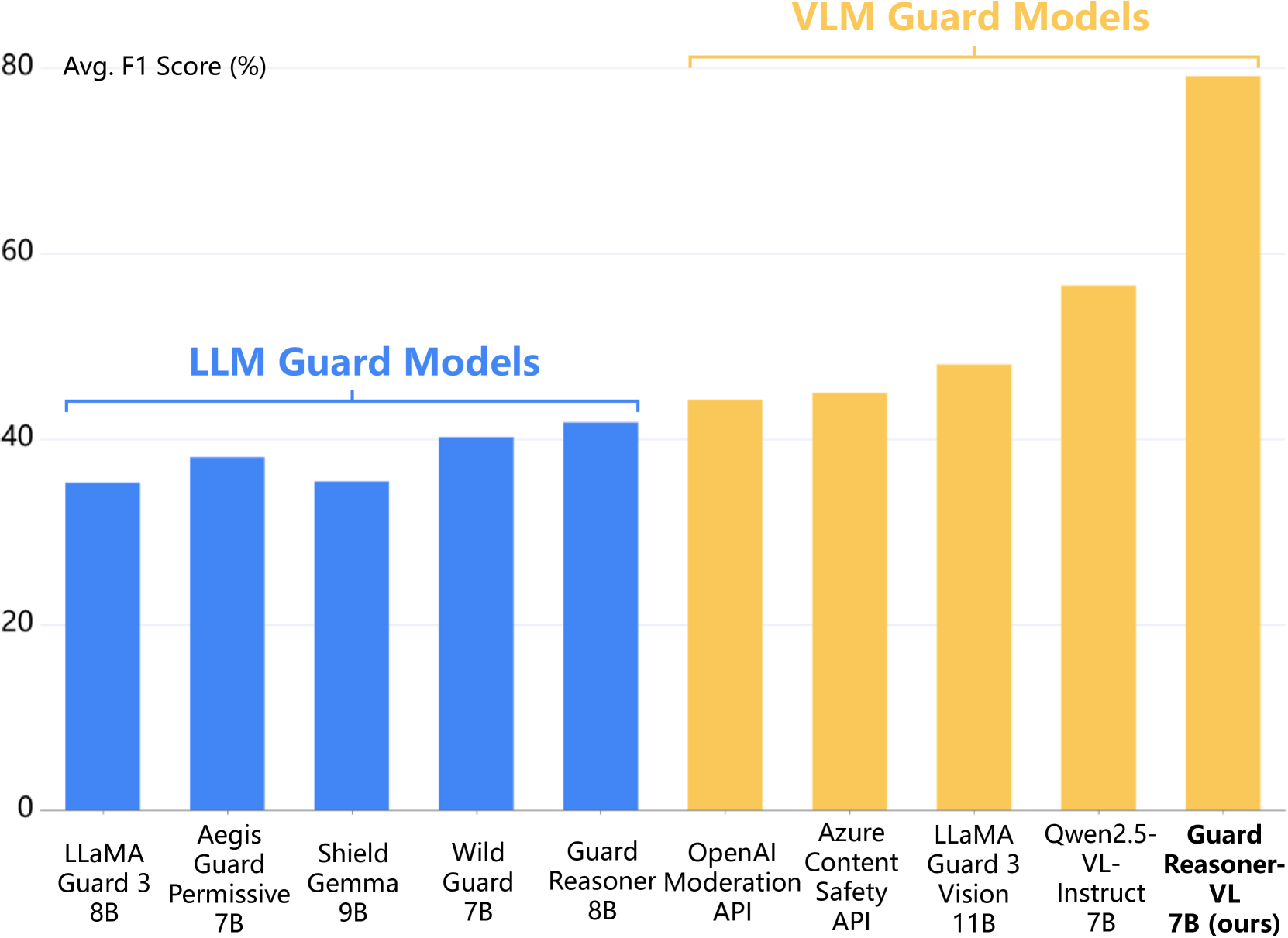
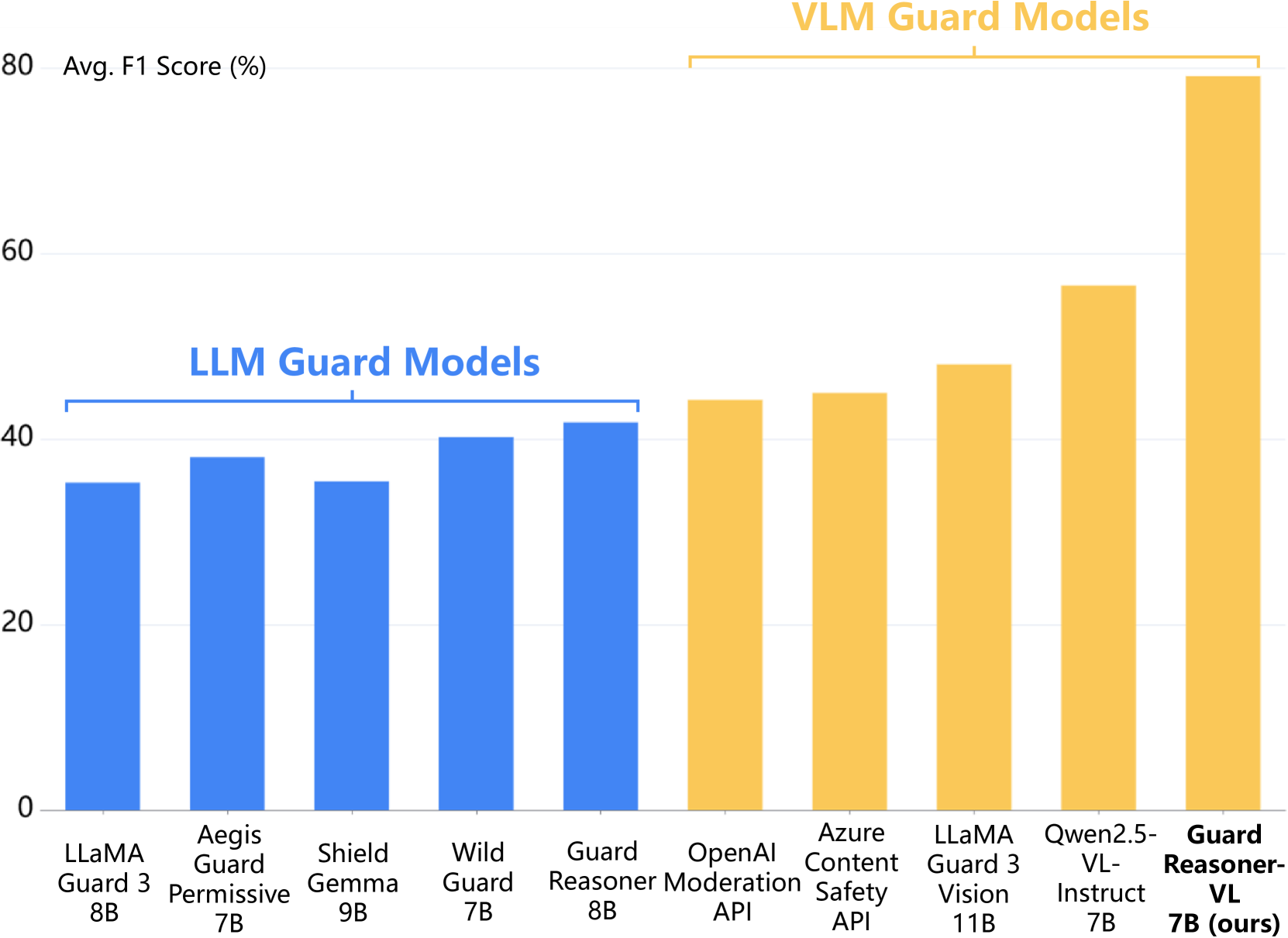
- +19.27% average F1 score improvement over the best runner-up baseline across evaluated benchmarks
- Established a new reasoning corpus with 123K samples and 631K reasoning steps covering diverse modalities
- Demonstrates superior performance in both prompt harmfulness detection and response harmfulness detection tasks
Breakthrough Assessment
8/10
Significant advance in VLM safety by successfully applying reasoning-based RL (similar to generic reasoning models like o1) to the specific domain of multimodal guardrails, with strong empirical gains.