📊 Experiments & Results
Evaluation Setup
Visual Question Answering on tables with varying visual quality (clean vs. noisy) and languages
Benchmarks:
- MirageTVQA (Multilingual Visual Table QA) [New]
Metrics:
- Exact Match (EM)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Baseline performance on clean images establishes the capabilities of state-of-the-art models before noise is introduced. | ||||
| MirageTVQA (Clean, English) | Exact Match (EM) | Not reported in the paper | 25.52 | Not reported in the paper |
| Impact of visual noise: Comparing performance on clean vs. noisy versions of the same tables reveals severe brittleness. | ||||
| MirageTVQA (English) | Exact Match (EM) | 25.52 | 16.50 | -9.02 |
| Multilingual performance aggregation shows the overall difficulty of the benchmark across 24 languages. | ||||
| MirageTVQA (All Languages) | Average Exact Match (EM) | Not reported in the paper | 13.57 | Not reported in the paper |
Experiment Figures
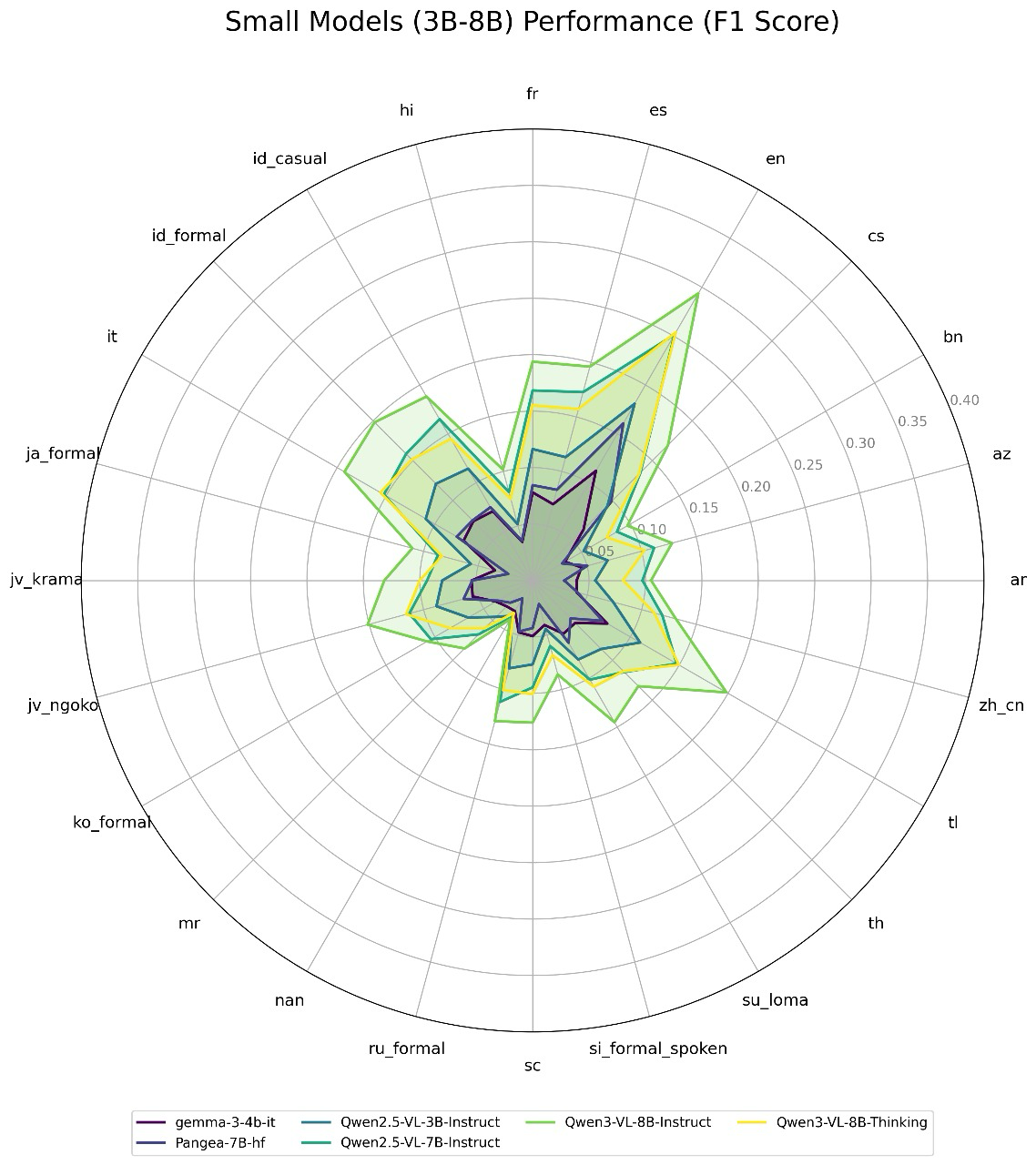
Radar charts (polygons) showing model performance across different languages
Main Takeaways
- Visual noise causes a severe performance drop (>35%) even in state-of-the-art models, proving that performance on clean synthetic data does not transfer to realistic document scenarios.
- Models exhibit a strong English-first bias; reasoning capabilities do not transfer effectively to other languages, even high-resource ones.
- Model scale correlates with reasoning capability on clean data, but even the largest models (72B) are brittle when faced with visual degradation.
- Current VLMs treat visual and linguistic challenges separately; there is a failure to generalize complex, visually grounded reasoning to non-English contexts.