📊 Experiments & Results
Evaluation Setup
Evaluation of 27 state-of-the-art VLMs (Qwen, InternVL, proprietary models) across 9 capabilities.
Benchmarks:
- AI2D (Diagram Understanding)
- VQA-v2 (General VQA)
- MME-RealWorld (Autonomous Driving / Spatial)
- DatBench (Composite Benchmark) [New]
Metrics:
- Accuracy (Generative exact match or LLM-judge match)
- MCQ Accuracy
- Speedup factor
- Statistical methodology: Point-biserial correlation for item selection. No explicit significance tests reported for model comparisons.
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Format analysis reveals massive score inflation in standard MCQ benchmarks compared to generative evaluation. | ||||
| AI2D | Average Accuracy | 77.56 | 40.53 | -37.03 |
| Data quality analysis shows high rates of invalid or blind-solvable questions in popular benchmarks. | ||||
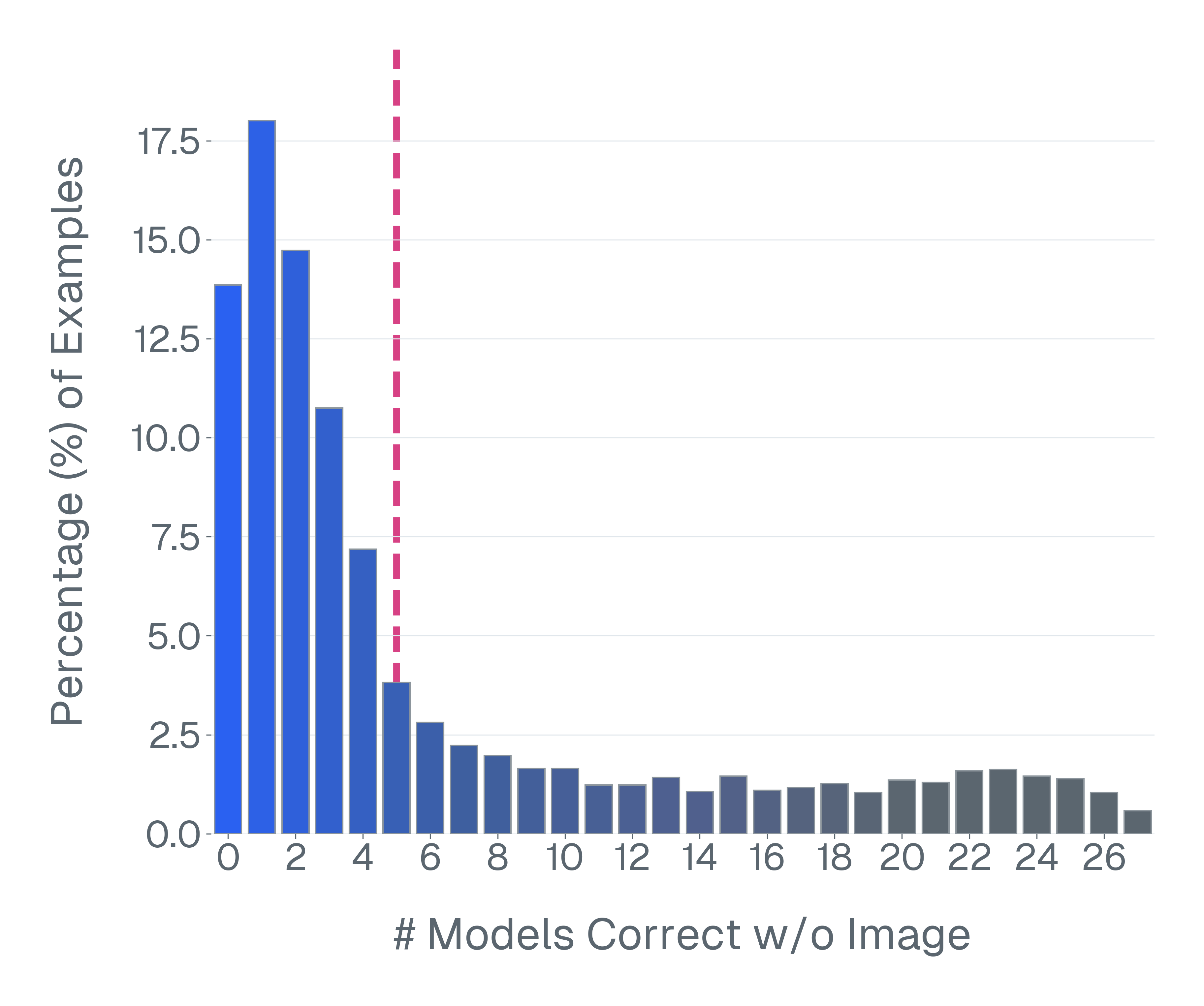
| VQA-v2 | Blind-Solvable Rate | 0 | 70 | +70 |
| MME-RealWorld (Spatial) | Discard Rate | 0 | 42.07 | +42.07 |
| Efficiency results demonstrate that the curated DatBench subset allows much faster evaluation. | ||||
| DatBench Suite | Inference Speedup | 1.0 | 13.0 | +12.0 |
Experiment Figures
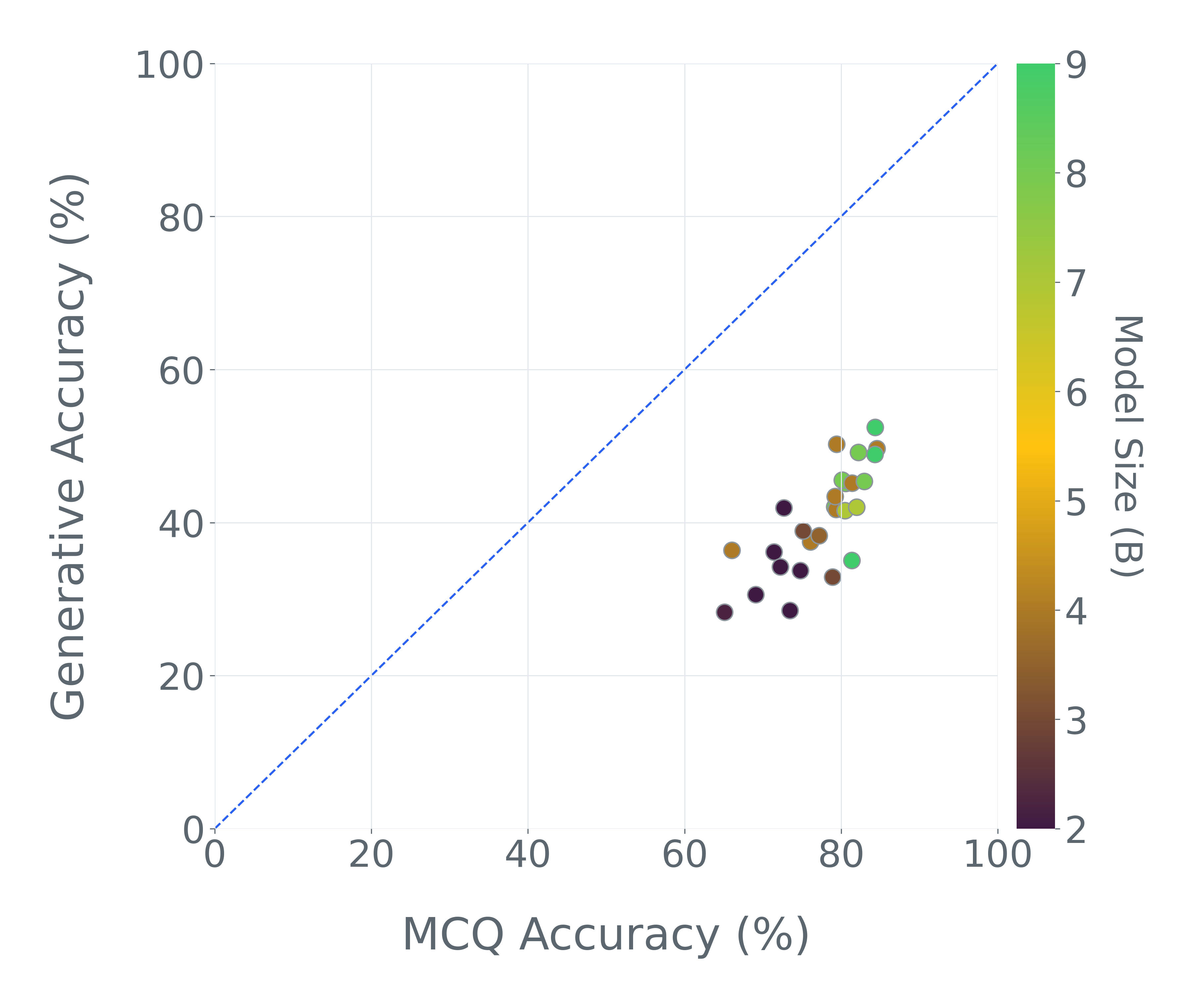
Scatter plots comparing MCQ accuracy vs. Generative accuracy (3a) and vs. Circular Evaluation (3b) across 27 models.
Curves showing Total Discriminative Power (7a) and Rank Correlation (7b) as a function of dataset size for Random vs. Discriminative sampling.
Main Takeaways
- Current MCQ benchmarks inflate VLM capabilities by rewarding guessing and shortcuts; generative evaluation reveals true performance is much lower.
- A massive portion of 'visual' benchmarks (up to 70% in VQA-v2) tests only language priors, not visual reasoning.
- Selecting evaluation samples based on discriminative power (point-biserial correlation) is far more efficient than random sampling or simple rank preservation.
- Inference-time scaling (thinking models) can degrade perceptual performance ('overthinking penalty'), a trend visible only after filtering noisy data.