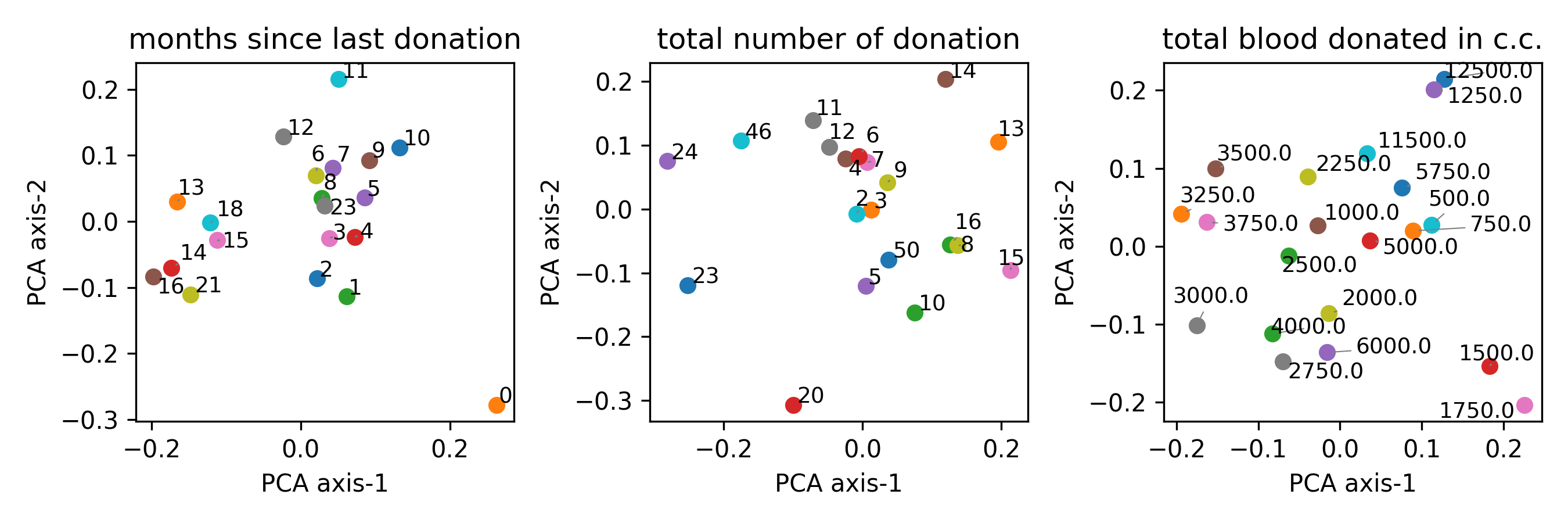
📝 Paper Summary
Tabular Deep Learning
Feature Representation Learning
This paper proposes transforming tabular data into natural language sentences and using frozen Large Language Model embeddings to improve feature representations for downstream deep learning models.
Core Problem
Existing tabular deep learning methods require separate, type-specific encoding for numerical and categorical features, which limits cross-table transfer and fails to capture semantic interactions between features and values.
Why it matters:
- Training embeddings from scratch is restrictive for domains with scarce data
- Disentangling feature names from values restricts the model's ability to learn meaningful context and interactions
- Current methods struggle to leverage pre-trained knowledge from large-scale models
Concrete Example:
In a medical dataset, a standard model encodes 'age' (numerical) and 'blood_pressure' (numerical) separately from 'diagnosis' (categorical). It misses the semantic context that 'Age is 75' implies different risks than just the number 75. The proposed method serializes this as 'This age is 75', allowing an LLM to capture the semantic nuance.
Key Novelty
Training-free LLM-based Tabular Feature Encoding
- Serializes each feature-value pair into a sentence (e.g., 'This {col} is {value}') to unify numerical and categorical inputs into a single text modality
- Utilizes off-the-shelf, frozen Large Language Models (LLMs) to generate embeddings for these sentences, replacing traditional lookup tables or linear embeddings
- Projects these high-dimensional LLM embeddings into a trainable deep learning model using a simple shallow network adaptation layer
Architecture

The workflow of the proposed LLM-based embedding method for tabular data.
Evaluation Highlights
- Improves FT-Transformer accuracy by an average of 3.05% across 7 datasets when using BGE embeddings compared to base embeddings
- Outperforms base ResNet and MLP models on datasets with rich categorical features like 'credit-g' and 'student-performance'
- Demonstrates that smaller, efficient models like BGE can perform competitively with or better than larger models like Llama-3 for tabular embedding tasks
Breakthrough Assessment
6/10
A practical, plug-and-play improvement for tabular DL. While it boosts neural performance, it still struggles to consistently beat XGBoost, limiting its transformative impact.