📝 Paper Summary
Medical Vision-Language Models (Med-VLMs)
Model Adaptation and Transfer Learning
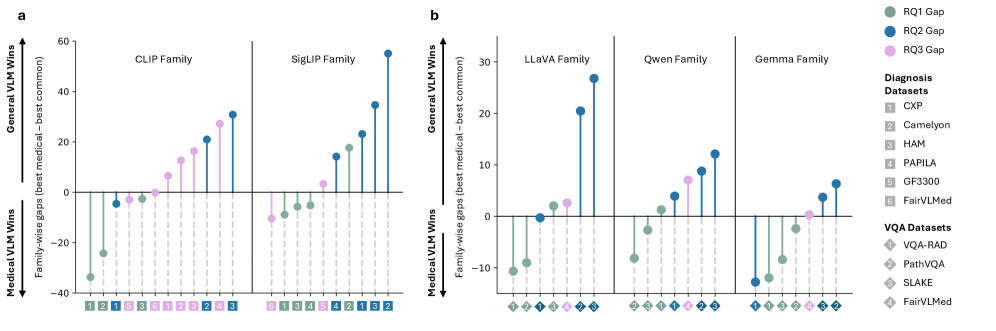
While specialist medical VLMs excel out-of-the-box on in-domain tasks, generalist VLMs adapted via lightweight fine-tuning match this performance and significantly outperform specialists on out-of-distribution modalities.
Core Problem
Specialist medical VLMs require expensive domain-specific pretraining and often lack robustness when applied to unseen medical modalities (out-of-distribution), while the potential of adapting widely available generalist VLMs is under-explored.
Why it matters:
- Developing specialist models for every medical niche is computationally prohibitive and data-hungry.
- Clinical AI needs to handle diverse, unseen modalities (OOD) where specialist models might fail due to overfitting.
- Current benchmarks often overlook the impact of lightweight adaptation, failing to reveal that generalists might be a more cost-effective solution.
Concrete Example:
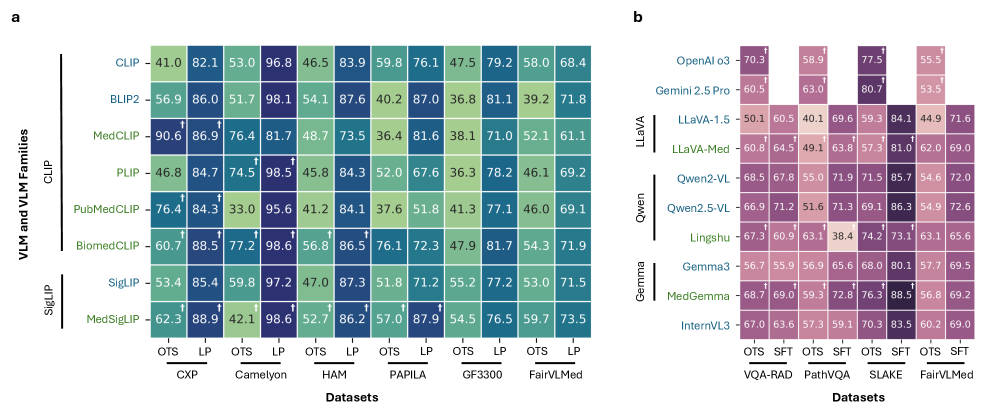
A specialist model like BioMedCLIP achieves high zero-shot accuracy on radiology but performs poorly on dermatology (OOD). Conversely, a generalist like BLIP2, initially poor on radiology, matches or beats the specialist after training a simple linear classifier, while retaining superior ability to learn dermatology tasks.
Key Novelty
MedVLMBench: A Systematic Paired Benchmark
- Systematically pairs generalist VLMs (e.g., CLIP, LLaVA) with their exact specialist counterparts (e.g., BioMedCLIP, LLaVA-Med) to isolate the effect of pretraining vs. adaptation.
- Evaluates not just off-the-shelf performance but also 'adaptability' via lightweight fine-tuning (Linear Probing, LoRA) across both in-distribution and out-of-distribution tasks.
- Challenges the assumption that expensive medical pretraining is strictly necessary by showing generalists often generalize better to new medical domains after tuning.
Architecture
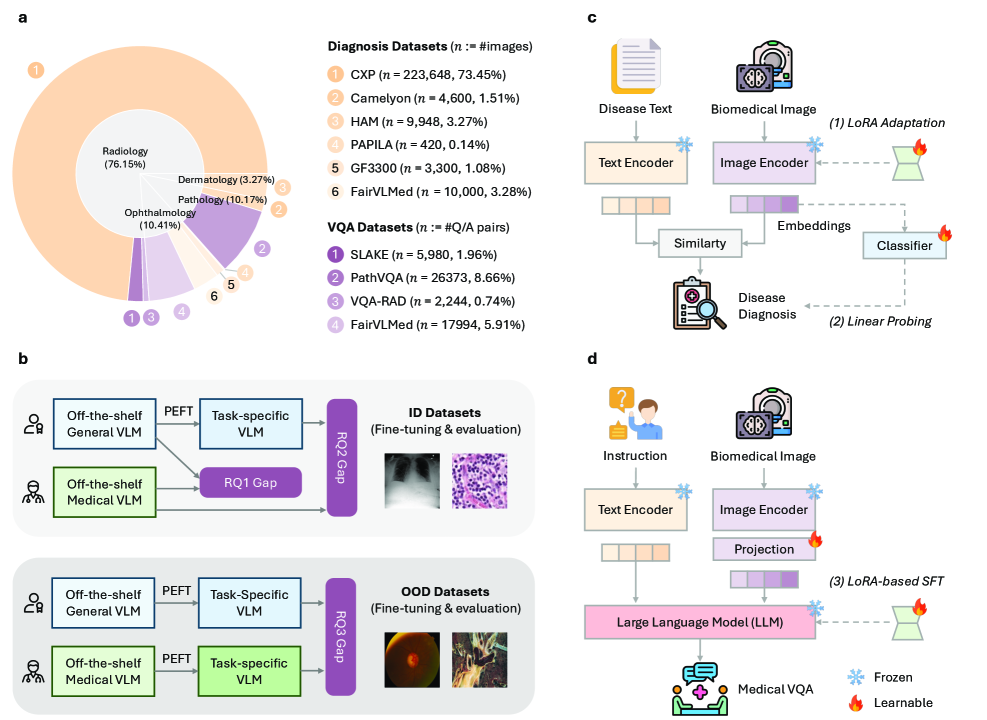
The MedVLMBench pipeline illustrating the comparison protocol between Generalist and Specialist VLMs across Contrastive and Generative families.
Evaluation Highlights
- In radiology diagnosis (CheXpert), specialist MedCLIP achieves 90.60% AUROC off-the-shelf, but generalist BLIP2 jumps from near-random to >98% AUROC after fine-tuning, surpassing the specialist.
- On OOD dermatology tasks (HAM10000), fine-tuned generalists (BLIP2, SigLIP) exceed 87% AUROC, whereas specialist MedCLIP remains below 80%.
- In VQA (SLAKE), the generalist Qwen2.5-VL achieves 86.3% GPT Score after tuning, significantly outperforming tuned specialist counterparts which plateau at 72–74%.
Breakthrough Assessment
8/10
Provides strong empirical evidence challenging the 'specialist is always better' dogma in medical AI, offering a practical blueprint for using generalist models via cheap adaptation.