📝 Paper Summary
Mobile GUI Agents
Vision-Language Models (VLMs)
Reinforcement Learning
GUI-Shift enhances GUI agents by training VLMs to predict the action connecting two screenshots (inverse dynamics) via self-supervised reinforcement learning, eliminating the need for expensive human-annotated instructions.
Core Problem
Training effective GUI agents typically relies on large-scale datasets of GUI trajectories paired with human-annotated instructions, which are labor-intensive to collect and often error-prone.
Why it matters:
- High annotation costs limit the scalability of supervised fine-tuning (SFT); for example, the AndroidControl dataset required one year of paid effort for only ~15k demonstrations
- SFT enforces a single 'correct' reference action, penalizing valid alternative actions (e.g., clicking a different pixel within the same button) and hindering robustness
- Existing VLMs struggle with complex multi-step tasks and temporal reasoning required for GUI automation
Concrete Example:
In a supervised setting, if a user clicks pixel (10, 10) on a button, SFT penalizes a model that predicts (12, 12) even though it is functionally identical. Additionally, collecting the text instruction 'Open Settings' for that click requires manual human effort.
Key Novelty
K-step GUI Transition (Self-Supervised Inverse Dynamics)
- Replaces text instructions with 'visual goals': the model is given a starting screenshot and a future screenshot (K steps later) and must predict the first action to bridge them
- Leverages Group Relative Policy Optimization (GRPO) to sample multiple action candidates and score them based on functional correctness (e.g., is the click inside the box?) rather than exact coordinate matching
- Omits reasoning traces (chain-of-thought) during training to significantly reduce computational cost while maintaining performance
Architecture
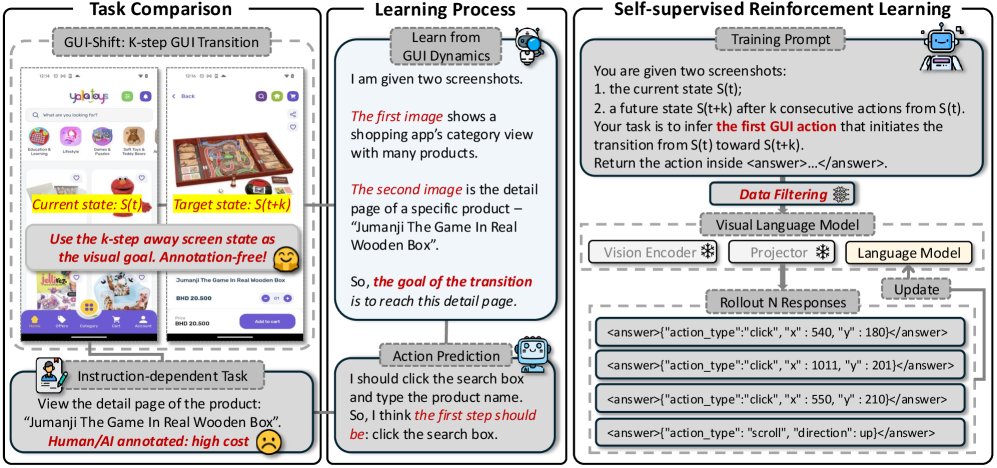
Overview of the GUI-Shift framework, illustrating the K-step GUI Transition task and the GRPO training process.
Evaluation Highlights
- Achieves 70.4% Exact Match (EM) accuracy on AndroidControl-High using Qwen2.5-VL-7B, an 11.2% improvement over the base model
- Improves GUI grounding performance by 2.5% on ScreenSpot-v2 without specific grounding fine-tuning
- Reduces training time by nearly 50% (17 hours to 9 hours) by eliminating reasoning trace generation during RL
Breakthrough Assessment
8/10
Proposes a scalable, self-supervised alternative to costly instruction-following datasets for GUI agents. The use of inverse dynamics with GRPO is a clever application that addresses data scarcity and action multiplicity simultaneously.