📝 Paper Summary
Vision-Language Models (VLMs)
Chart Understanding
Visual Question Answering (VQA)
ChartPaLI-5B transfers reasoning capabilities from large language models to smaller vision-language models via a chart-to-table pre-training mixture and fine-tuning on synthetic reasoning traces generated by LLMs.
Core Problem
Small Vision-Language Models (VLMs) often lack complex reasoning capabilities required for chart understanding, such as performing arithmetic or implicit information extraction, compared to their larger counterparts.
Why it matters:
- Current models fail to contextually combine image and text representations effectively for complex queries involving multiple reasoning steps.
- Transferring reasoning from large to small models reduces serving costs while maintaining or improving task performance.
- Existing small models like PaLI-3 fall behind larger models (e.g., PaLI-X) on benchmarks like ChartQA due to limited reasoning skills.
Concrete Example:
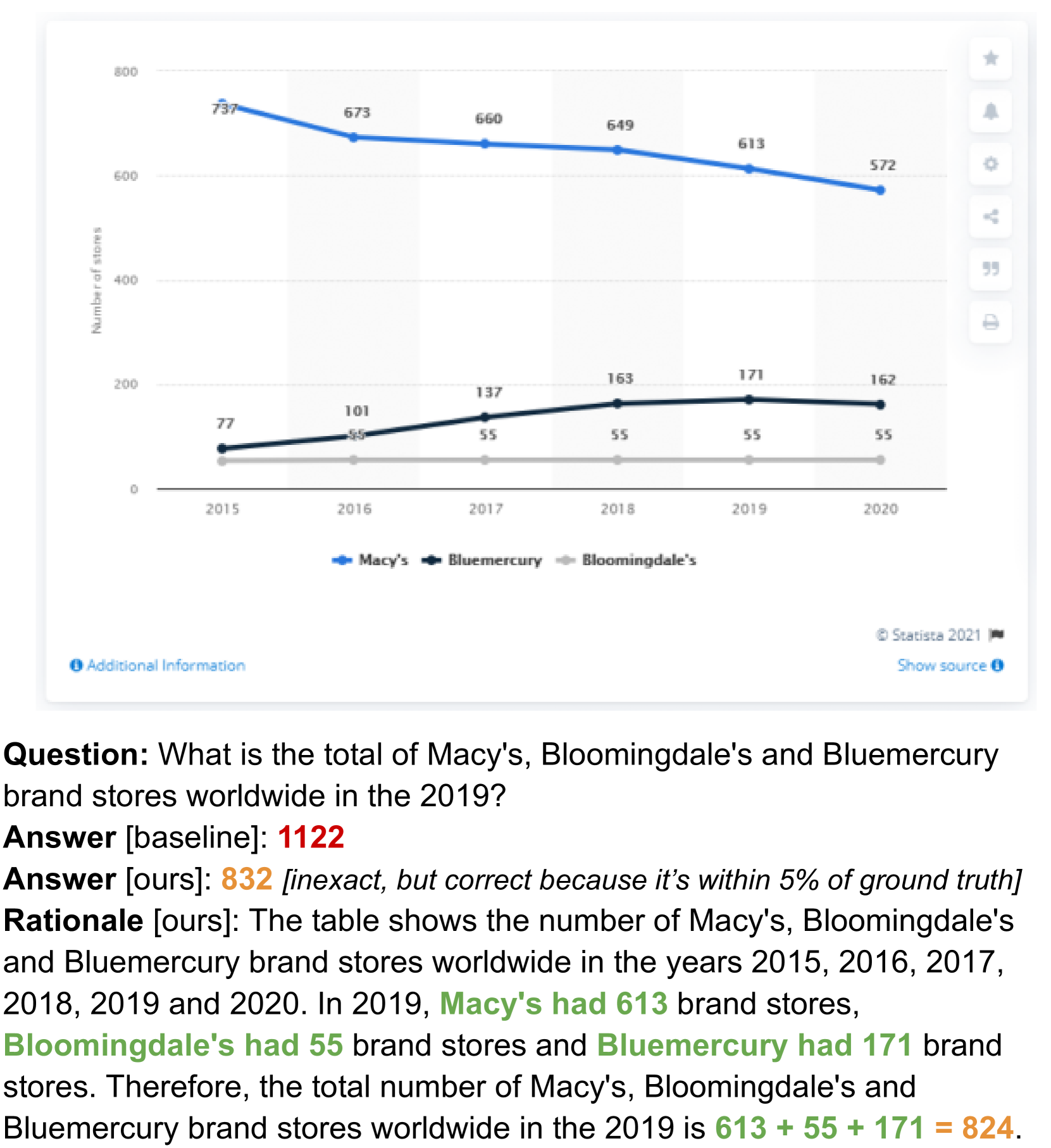
When asked 'What is the sum of values for 2020 and 2021?' on a bar chart, a standard small VLM might just retrieve one value or hallucinate, whereas the proposed method generates a reasoning trace (lookup 2020 value, lookup 2021 value, add them) to derive the correct answer.
Key Novelty
ChartPaLI-5B (Reasoning Transfer Recipe)
- Continues pre-training the vision backbone on a diverse 'chart-to-table' mixture to learn better internal structural representations of charts.
- Augments training data by 20x using an LLM (PaLM 2) to synthesize reasoning traces (rationales) and additional question-answer pairs derived from the tabular representation of charts.
- Fine-tunes using a multi-task loss that treats rationale generation and answer prediction as separate but joint tasks, balancing their importance.
Architecture
The conceptual flow of the pre-training and fine-tuning recipe.
Evaluation Highlights
- Obtains State-of-the-Art (SoTA) on ChartQA among models <10B parameters, outperforming the 55B parameter PaLI-X.
- Achieves 81.3% accuracy on ChartQA, surpassing GPT-4V (78.5%) and Gemini Ultra (80.8%) when using Program-of-Thought (PoT) refinement.
- Outperforms the PaLI-3 baseline by ~10% absolute accuracy on ChartQA through the proposed pre-training and fine-tuning recipe.
Breakthrough Assessment
8/10
Significant efficiency breakthrough: achieves SoTA on a complex reasoning benchmark using a 5B model, outperforming 10x larger models and proprietary giants like GPT-4V, largely due to data quality and multi-task transfer learning.