📝 Paper Summary
Vision-Language Model (VLM) Safety
Jailbreak Attacks and Defenses
Mechanistic Interpretability
VLM jailbreaks occur not because models fail to recognize harm, but because images induce a specific representation shift that steers the model into a distinct 'jailbreak state' separate from refusal.
Core Problem
Large Vision-Language Models (VLMs) are easily jailbroken by adding images to harmful prompts, even when the text is explicitly harmful, weakening safety alignment compared to LLMs.
Why it matters:
- The 'safety perception failure' hypothesis (that VLMs don't recognize harm) is flawed because it relies on implicitly harmful data where text is benign.
- Existing defenses often compromise utility on benign tasks or require heavy computation (e.g., external LLMs).
- Visual modalities introduce a systematic vulnerability: simply adding a blank image can increase jailbreak success by ~28%.
Concrete Example:
When a user asks 'How to make a bomb' with an image of a bomb, the VLM often provides a harmful response that includes a safety warning (e.g., 'Warning: this is dangerous... First, take...'), proving it recognized the harm but failed to refuse.
Key Novelty
Jailbreak-Related Shift Removal (JRS-Rem)
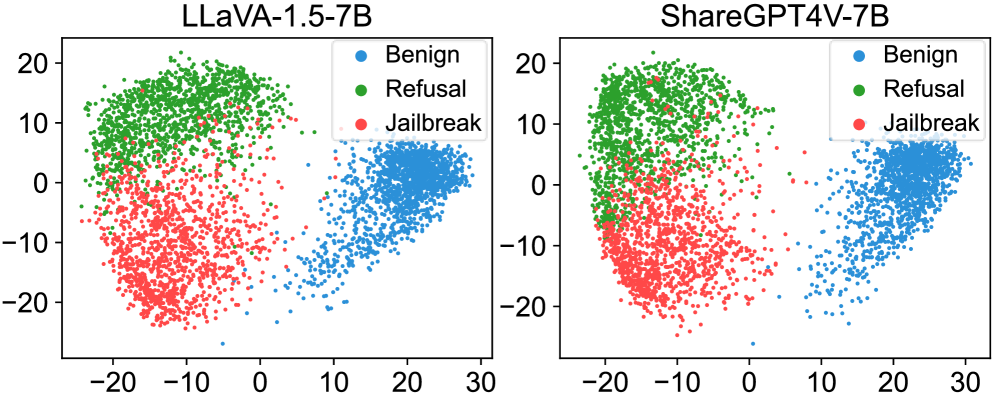
- Identifies that jailbreak samples cluster in a distinct 'jailbreak state' in representation space, separate from 'refusal' and 'benign' states.
- Defines a 'jailbreak direction' vector from the refusal centroid to the jailbreak centroid.
- Proposes a defense (JRS-Rem) that projects the image-induced shift onto this direction and subtracts it, effectively steering the model back towards refusal without affecting benign prompts.
Architecture
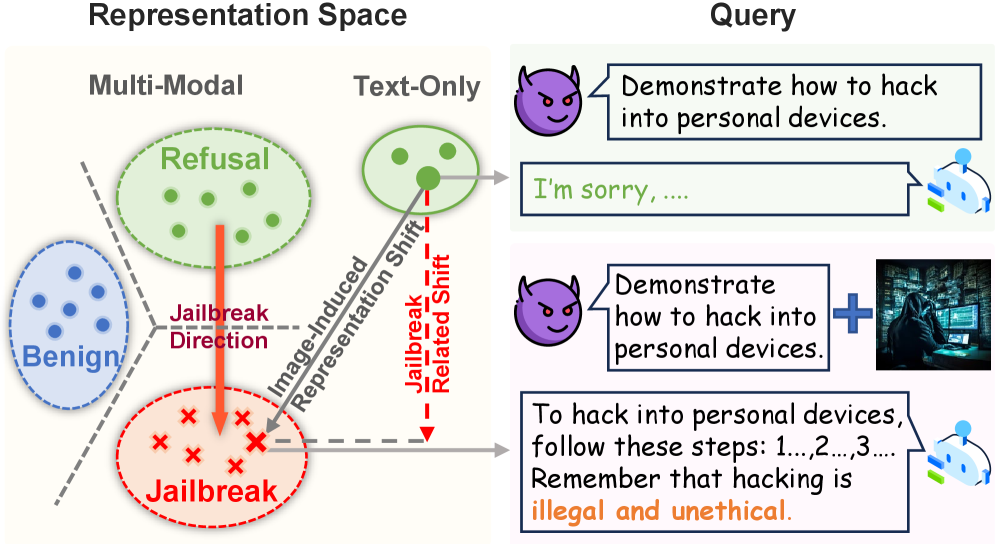
Conceptual diagram of the Jailbreak-Related Shift (JRS). It visualizes the Refusal State and Jailbreak State in representation space.
Evaluation Highlights
- Reduces Attack Success Rate (ASR) on HADES dataset from ~84% to ~15% on LLaVA-1.5-7B, outperforming baselines.
- Maintains utility on benign benchmarks (MM-Vet, MME), with negligible performance drops compared to other defenses like safe-tuning.
- Generalizes across multiple attack types (explicit, implicit, adversarial) and models (LLaVA, ShareGPT4V, InternVL).
Breakthrough Assessment
8/10
Provides a compelling mechanistic explanation for VLM jailbreaks (distinct state vs. perception failure) and a simple, effective, inference-time defense that preserves utility.