📊 Experiments & Results
Evaluation Setup
Zero-shot cross-modal retrieval on public RS benchmarks.
Benchmarks:
- RSICD (Image-Text Retrieval)
- RSIVL (Image-Text Retrieval)
- MLRSNet (Image-Text Retrieval)
Metrics:
- Recall@1 (R@1)
- Recall@5 (R@5)
- Recall@10 (R@10)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Zero-shot retrieval performance on RSICD dataset. | ||||
| RSICD | Recall@1 | 11.1 | 18.8 | +7.7 |
| RSICD | Recall@5 | 24.6 | 39.8 | +15.2 |
| Zero-shot retrieval performance on RSIVL dataset. | ||||
| RSIVL | Recall@1 | 11.3 | 19.6 | +8.3 |
| Zero-shot retrieval performance on MLRSNet dataset. | ||||
| MLRSNet | Recall@1 | 13.6 | 26.3 | +12.7 |
| Ablation study showing the impact of specific datasets on MLRSNet Recall@1. | ||||
| MLRSNet | Recall@1 | 18.1 | 26.3 | +8.2 |
| MLRSNet | Recall@1 | 25.2 | 26.3 | +1.1 |
Experiment Figures
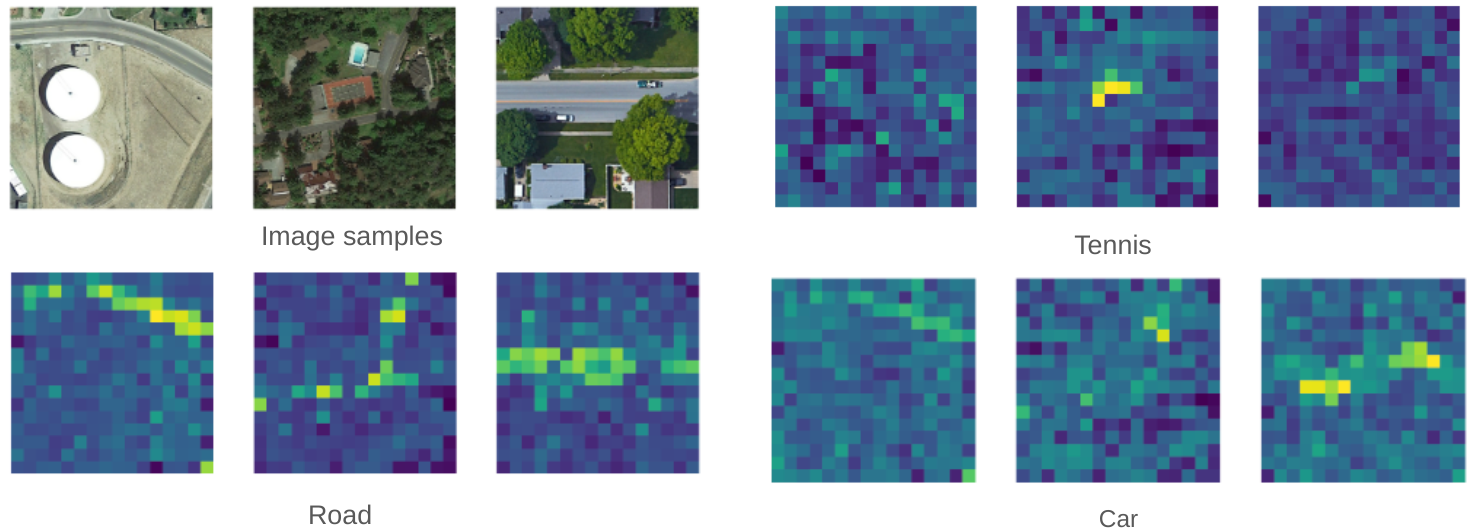
Visualizations of similarity-based attention maps for zero-shot localization.
Main Takeaways
- The combined training on RS-WebLI and RS-Landmarks (MT-RSWebli-RSLandmarks) consistently outperforms general baselines and single-dataset variants.
- The curriculum training strategy (WebLI → RS-WebLI → RS-Landmarks → Mix) is effective for adapting the VLM to the remote sensing domain.
- Zero-shot generalization is strong even on unseen categories (proven via the RS-Landmarks-89-holdout experiment), showing the model learns general features rather than just memorizing landmarks.