📝 Paper Summary
Spatial reasoning in Vision Language Models (VLMs)
Perspective taking and mental rotation
SpinBench is a diagnostic benchmark that evaluates VLMs' spatial reasoning by decomposing perspective taking into progressively harder tasks like rotation, identity matching, and relative pose estimation.
Core Problem
Current VLMs demonstrate apparent spatial skills in end-to-end tasks, but it is unclear if they possess genuine geometric understanding or rely on shallow pattern matching and dataset biases.
Why it matters:
- Failures in basic spatial primitives (like rotation or viewpoint change) undermine reliability in embodied applications like robotics, navigation, and physical commonsense reasoning
- Existing benchmarks often entangle spatial reasoning with high-level planning or language, masking specific deficits in mental simulation or frame-of-reference handling
- Prior work lacks controlled variation to distinguish between visual perception errors and linguistic reasoning failures
Concrete Example:
In a dynamic rotation task, when a person turns left (from their own perspective), models often incorrectly predict 'right' because they default to the viewer's perspective, failing to switch frames of reference even when explicitly prompted.
Key Novelty
Cognitively Grounded Diagnostic Benchmark for Spatial Reasoning
- Decomposes complex perspective-taking into seven atomic diagnostic categories (e.g., identity matching, mental rotation, dynamic translation) to pinpoint specific failure modes
- Systematically controls for frame-of-reference (viewer-centric vs. object-centric) and applies logical augmentations (symmetry, syntax) to test reasoning consistency
- Designed with a progressive structure where success on simpler single-object tasks is a prerequisite for complex multi-object scene reasoning
Architecture
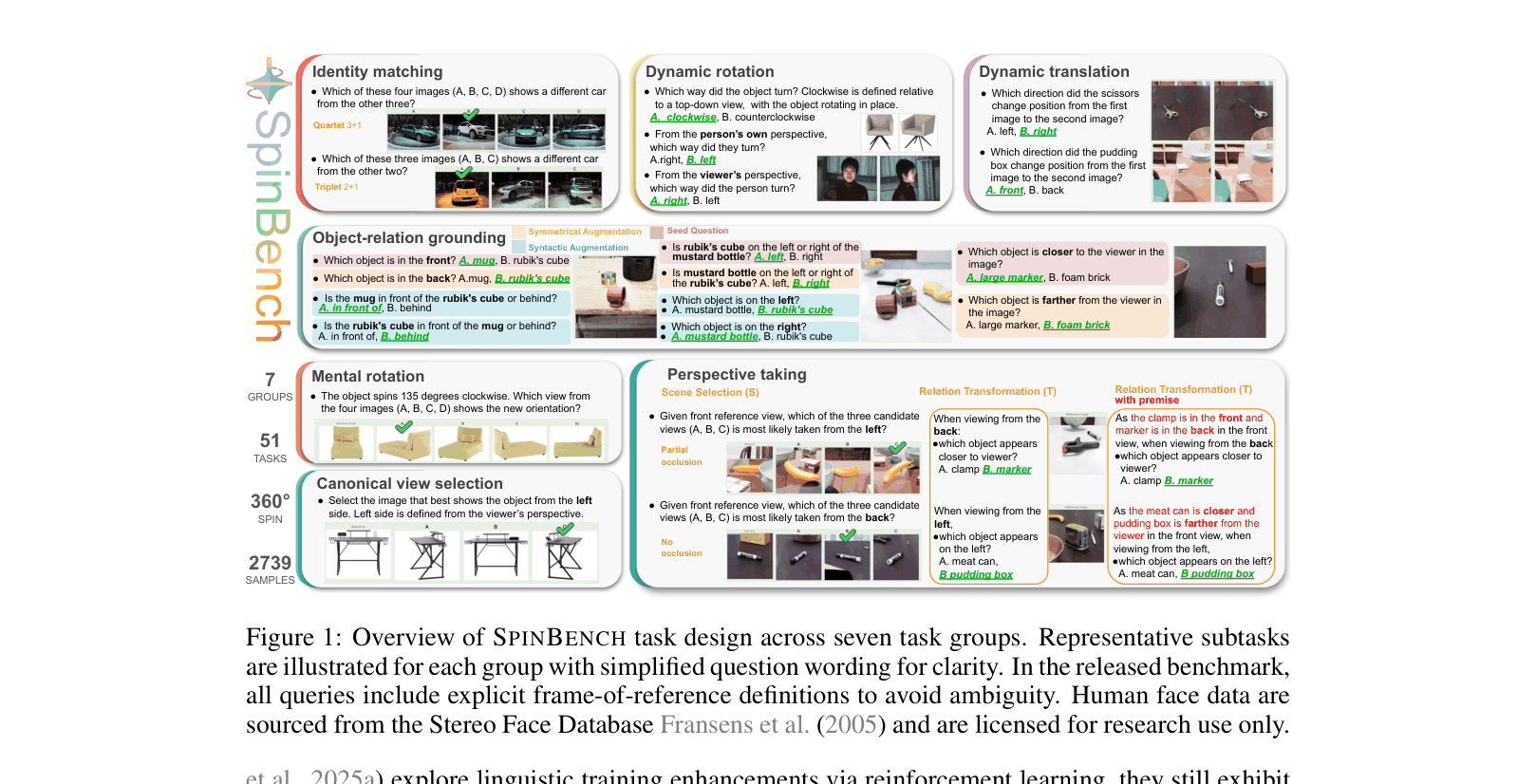
Overview of SpinBench task design, illustrating the 7 diagnostic categories and examples of visual inputs for each.
Evaluation Highlights
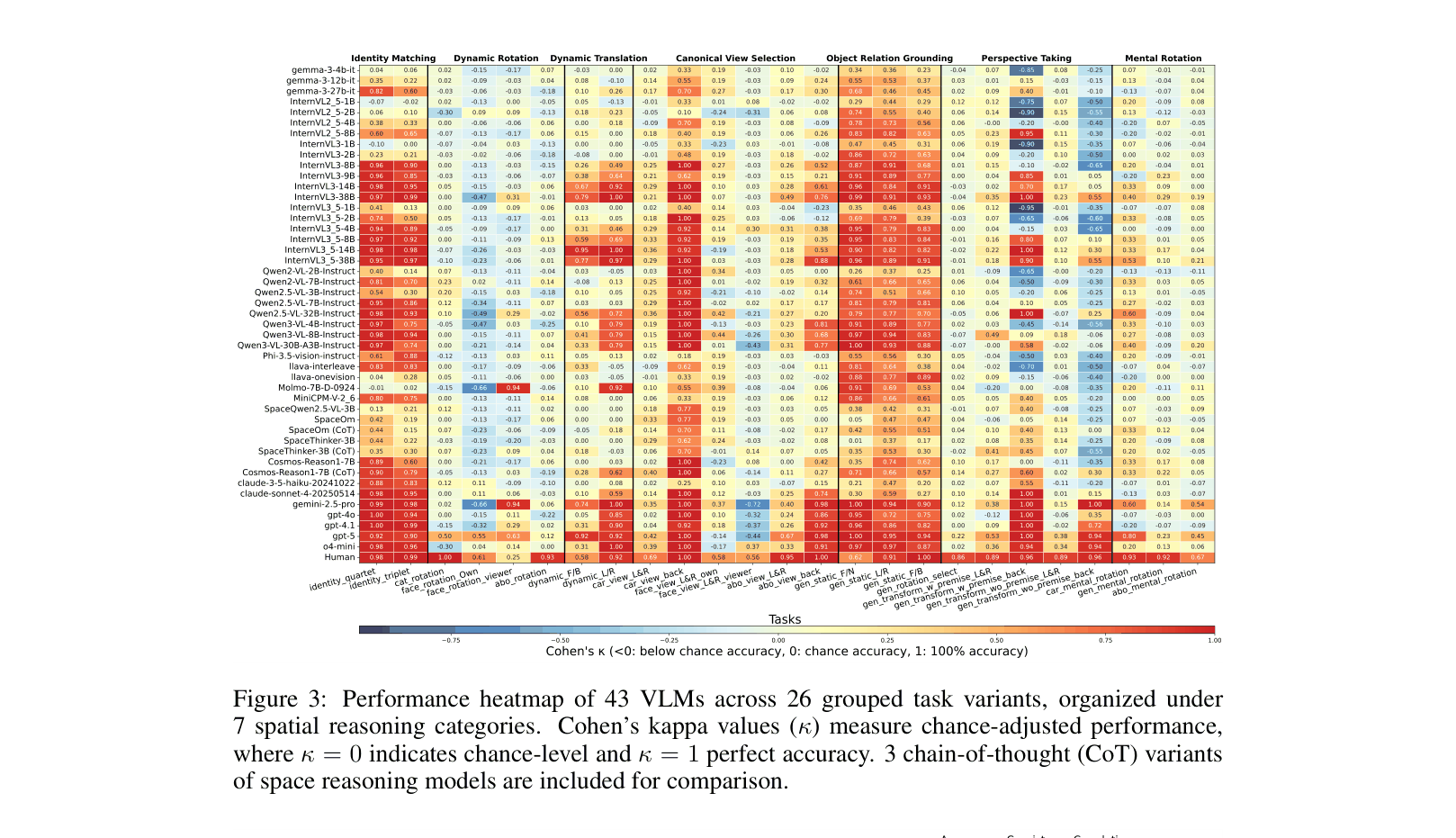
- Proprietary models like GPT-5 achieve high consistency (97.1%) and accuracy, but most open-source models perform near chance on mental rotation and perspective taking
- Strong egocentric bias detected: models excel at viewer-centric rotation (e.g., 0.94 kappa for Gemini 2.5 Pro) but fail dramatically on allocentric variants (-0.66 kappa)
- Human response time correlates strongly with VLM accuracy (r = -0.54), validating that the benchmark captures genuine spatial difficulty shared by humans and models
Breakthrough Assessment
9/10
A rigorously designed diagnostic tool that exposes fundamental gaps in spatial intelligence. By isolating specific cognitive primitives like rotation and perspective taking, it moves beyond aggregate metrics to explain *why* models fail.