📝 Paper Summary
Remote Sensing Vision-Language Models
Domain Adaptation
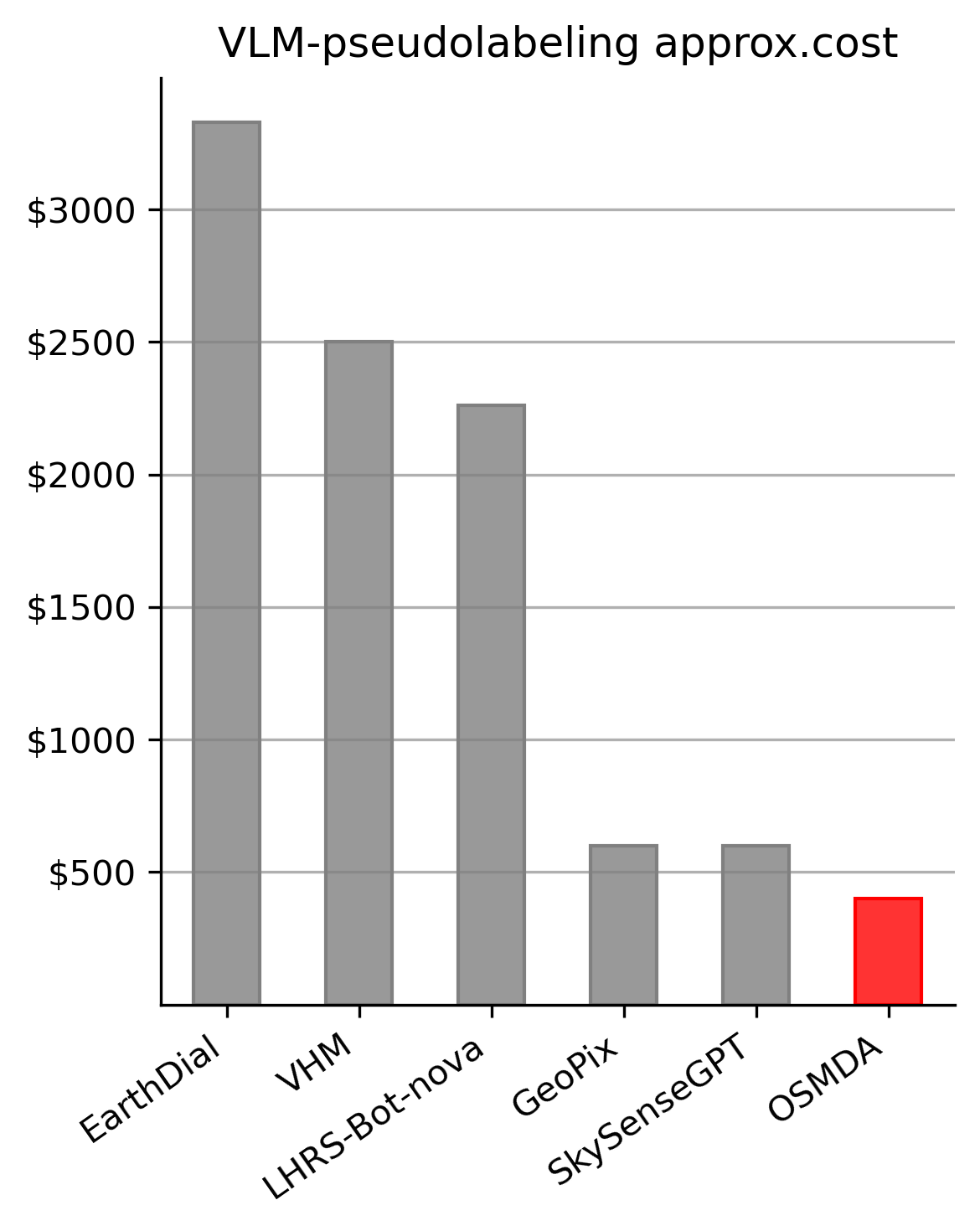
OSMDA enables VLMs to self-generate remote sensing captions by reading co-registered OpenStreetMap tiles as visual ground truth, eliminating the need for expensive external teacher models like GPT-4V.
Core Problem
Adapting VLMs to remote sensing relies on expensive distillation from proprietary teachers (e.g., GPT-4V) or text-only OSM tags that discard geometric topology.
Why it matters:
- Distilling from stronger teachers imposes a hard performance ceiling (student cannot surpass teacher)
- Proprietary APIs are costly at the scale required for remote sensing datasets (millions of images)
- Existing OSM approaches parse data into text tags, losing critical spatial layout and adjacency information available in visual maps
Concrete Example:
A text-based pipeline might list 'tags: road, building', losing the information that the road curves *around* the building. OSMDA renders this as a map image, allowing the VLM to visually 'read' the curve and spatial relationship, generating a caption like 'a curved road encircling a residential structure'.
Key Novelty
Visual Map-Based Self-Annotation
- Treats OpenStreetMap not as a database of text tags, but as a visual modality to be rendered and 'read' by the VLM's own vision encoder
- Leverages the base VLM's existing OCR and chart comprehension capabilities to extract supervision from rendered maps, making the model its own annotator
Architecture
The OSMDA pipeline: Data Curation → Map Rendering → Caption Generation → VLM Fine-tuning.
Breakthrough Assessment
7/10
Cleverly bypasses the 'teacher bottleneck' by using procedural rendering as a teacher. While the concept of using OSM is not new, treating it as a visual input for VLM self-training is a novel shift from text-tag parsing.