📝 Paper Summary
Efficient Vision-Language Models (VLMs)
Token Pruning
VLM-Pruner is a training-free method that selects visual tokens by starting from key object centers and expanding outward, prioritizing local details over distant background noise to balance efficiency and accuracy.
Core Problem
Existing token pruning methods either keep too many redundant tokens (importance-driven) or select scattered, incomplete tokens that miss object details (redundancy-reduction), degrading model performance.
Why it matters:
- Visual tokens in high-resolution images can outnumber text tokens by thousands, causing quadratic computational costs in LLMs
- Deployment on mobile devices is hindered by the high latency and memory usage of processing full visual sequences
- Current methods fail to balance removing redundancy with preserving the dense local details needed for fine-grained tasks like OCR and grounding
Concrete Example:
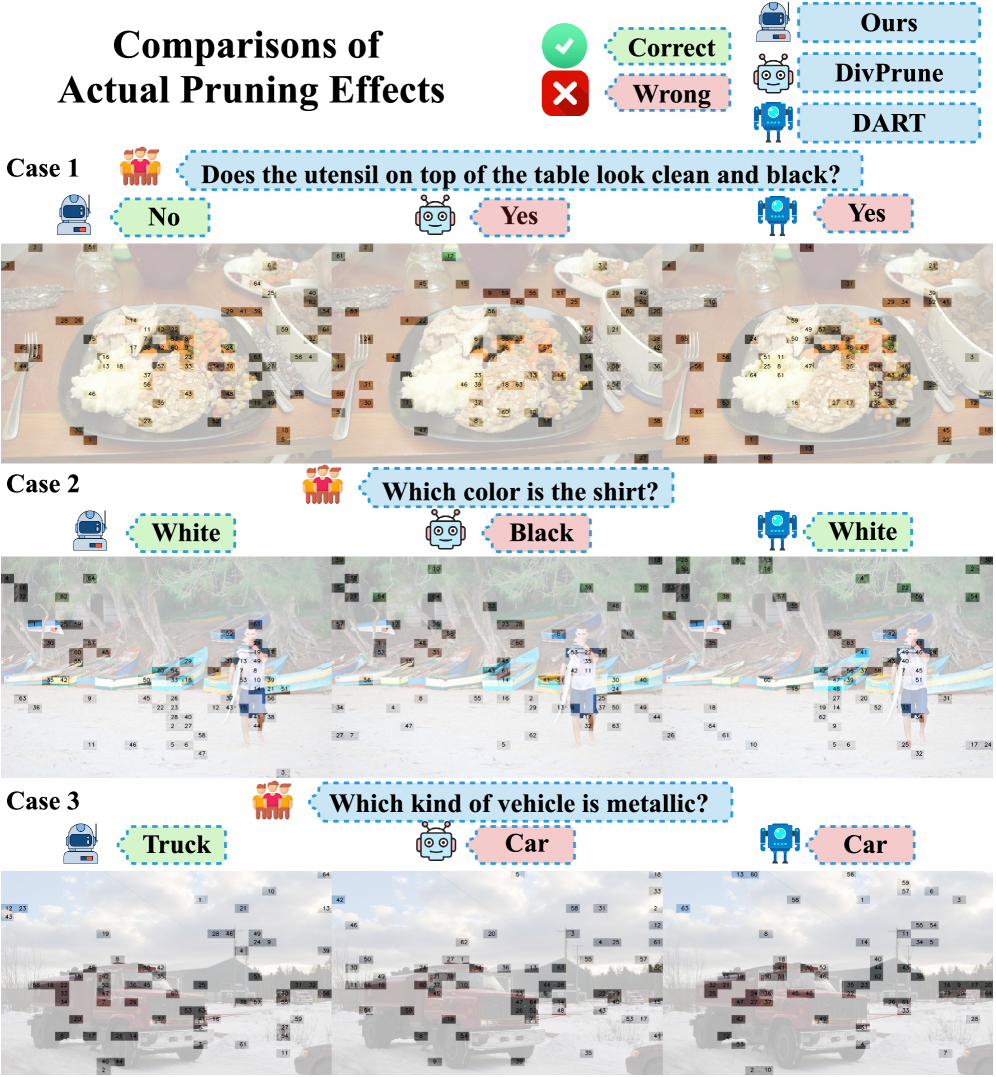
In an image of a truck, redundancy-reduction methods like DivPrune might select scattered background edges and miss the truck's body because the body parts look similar to each other. VLM-Pruner purposefully keeps the similar body tokens to preserve the truck's complete structure.
Key Novelty
Centrifugal Token Pruning with Buffering for Spatial Sparsity (BSS)
- Visualizes selection as a 'centrifugal' process: starts with central pivot tokens and gradually expands outward, rather than randomly picking diverse points
- Uses a 'spatial buffering' rule that makes spatially distant tokens appear more 'redundant' (and thus less likely to be picked early), forcing the model to fill in local object details first
- Re-injects information from discarded tokens back into the selected ones using a weighted average, ensuring no semantic information is completely lost
Architecture
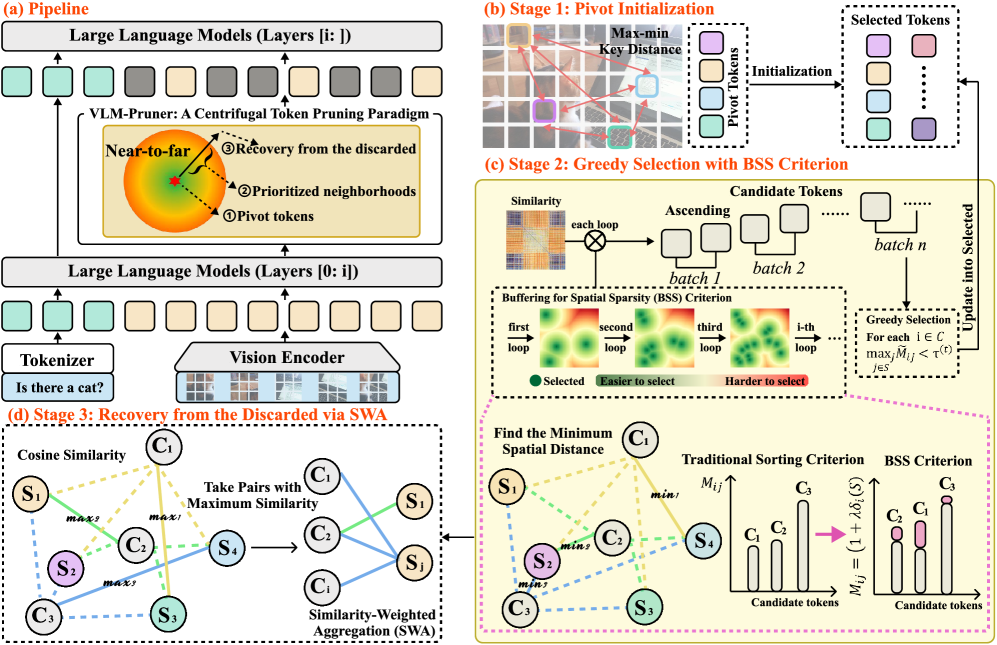
The three-stage pipeline of VLM-Pruner: Pivot Initialization, Centrifugal Expansion, and Recovery
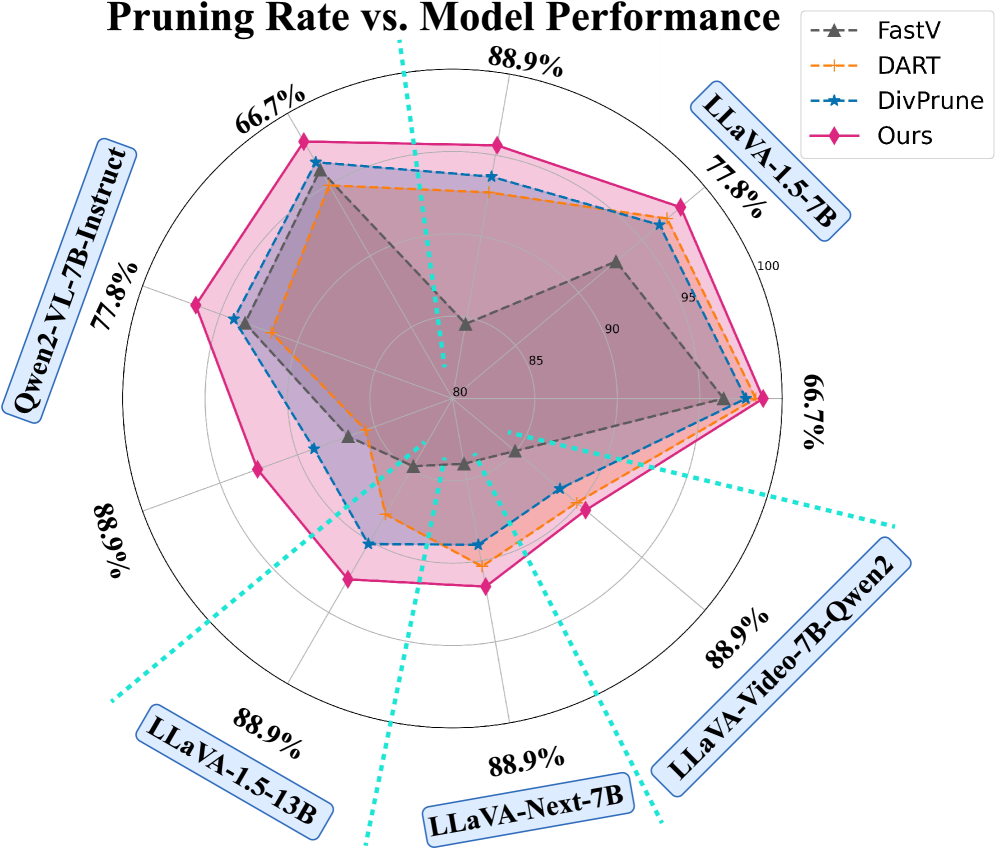
Evaluation Highlights
- Maintains 95.61% of original LLaVA-1.5-7B performance while pruning 88.9% of visual tokens (reducing from 576 to 64 tokens)
- Outperforms redundancy-reduction baseline DivPrune by +2.48% and importance-based FastV by +7.93% on LLaVA-1.5-13B with 64 tokens
- Achieves state-of-the-art results across 13 benchmarks and 5 different VLM architectures (including video models), showing consistent generalization
Breakthrough Assessment
8/10
Offers a smart, training-free heuristic that addresses a specific failure mode of prior pruning (scattered selection). Strong empirical results across many models, though the core innovation is a heuristic modification to greedy selection.