📝 Paper Summary
GUI Navigation Agents
Visual Language Models (VLMs)
Process Supervision
GuidNav improves VLM agents in GUI tasks by training a lightweight process reward model to verify and select the best action at every step during inference.
Core Problem
Current VLM agents for GUI navigation often fail because they rely on outcome-based feedback (delayed) or heavy reinforcement learning (unstable/costly), missing the opportunity to correct individual wrong steps before the trajectory fails.
Why it matters:
- State-of-the-art commercial VLMs (e.g., GPT-4V) are black boxes that cannot be fine-tuned easily.
- Trajectory-level evaluation provides delayed feedback, making it hard to pinpoint exactly where an agent went wrong in a long sequence of GUI interactions.
- Existing RL methods for dynamic environments are computationally expensive and unstable due to sparse rewards.
Concrete Example:
In a task like 'Get to the nearest Walmart,' a standard agent might click a wrong search bar early on. Outcome supervision only signals failure at the very end (after many steps), whereas GuidNav's process reward model detects the error immediately at that specific step, prompting the agent to choose a better action.
Key Novelty
GuidNav (Process Reward Guidance for GUI Agents)
- Trains a specific 'Process Reward Model' (PRM) using human demonstrations and synthetic VLM self-play data to score potential actions at every single step.
- During inference, instead of just taking the VLM's first predicted action, the system generates multiple candidates and uses the PRM to select the one with the highest predicted success probability.
- Integrates this step-level guidance with trajectory-level reflection/retry mechanisms for a two-layered optimization approach.
Architecture
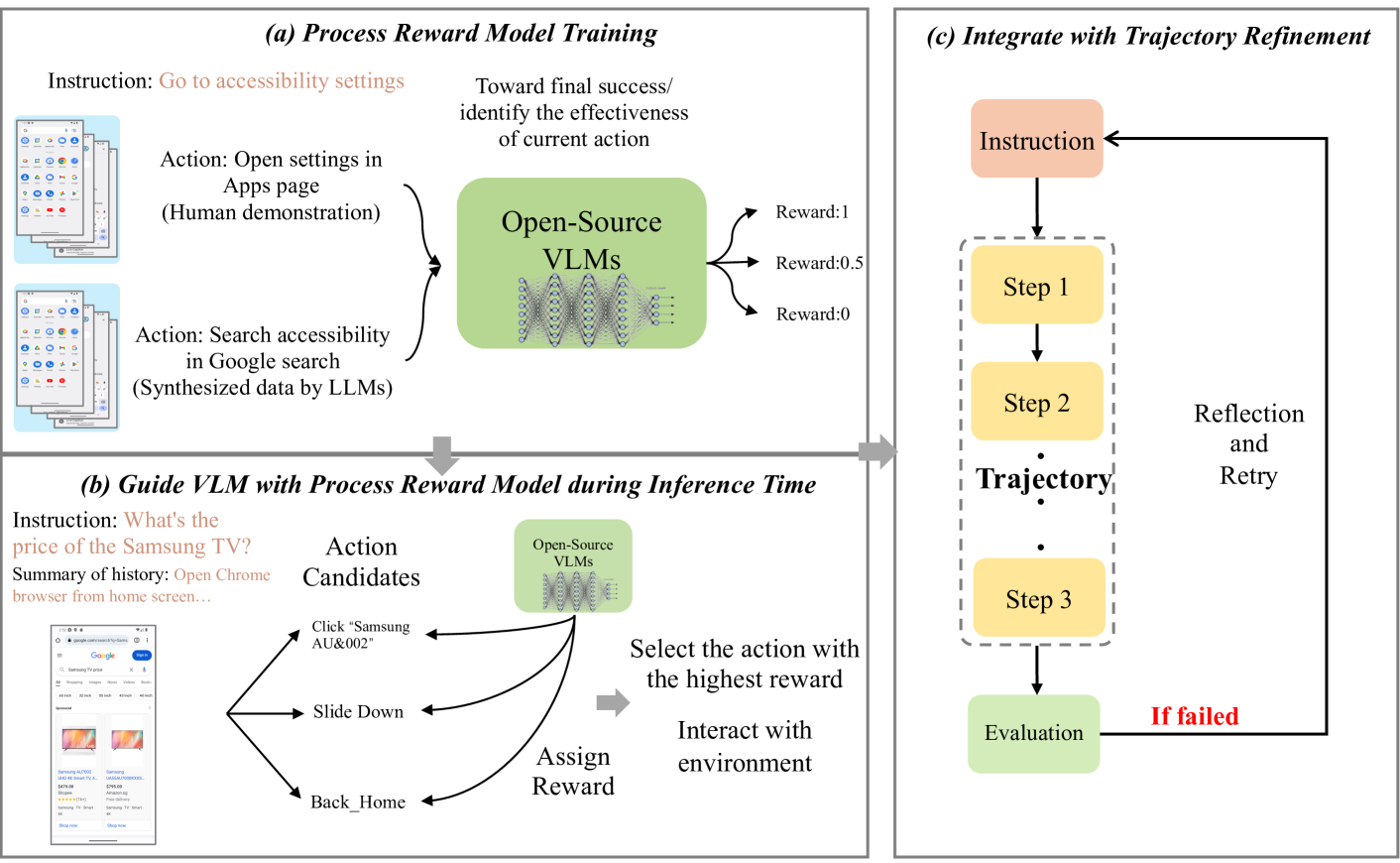
Overview of the GuidNav framework, including Reward Model Training, Action Guidance during inference, and Integration with Reflection.
Evaluation Highlights
- +33% improvement in task success rate for GPT-4o on dynamic environments in the Android-in-the-Wild (AitW) benchmark compared to standard prompting.
- +3.4% improvement in single-step action accuracy for static environments in AitW.
- Achieves 71.6% success rate on AitW dynamic tasks when combined with trajectory reflection and retry mechanisms.
Breakthrough Assessment
7/10
Strong empirical gains (+33% success rate) in dynamic GUI tasks using a method that is less computationally expensive than full RL training. Effectively applies the 'Process Reward' concept (popular in math reasoning) to visual GUI agents.