📝 Paper Summary
Aerial Object Navigation
Vision-Language Navigation (VLN)
Robotic Exploration
AirHunt enables drones to continuously search for open-set objects by decoupling slow VLM reasoning from fast flight planning using an asynchronous shared 3D value map.
Core Problem
Existing VLM-based drone navigation suffers from a severe frequency mismatch between slow VLM inference and real-time flight control, forcing 'stop-and-infer' behaviors that disrupt efficiency.
Why it matters:
- Current 'stop-and-infer' paradigms waste limited drone battery life by forcing hovers during slow inference
- VLMs lack native 3D understanding, leading to inconsistent decisions across viewpoints and redundant revisits of searched areas
- Greedy or simplistic planning fails to balance semantic cues (where the object might be) with geometric costs (how far to fly), leading to inefficient paths
Concrete Example:
When searching for 'a lost red backpack,' standard methods force the drone to hover for ~2 seconds every few meters to process images. Because the VLM works on 2D images, it might mistakenly guide the drone back to a previously visited red object, forgetting the global context.
Key Novelty
Dual-Pathway Asynchronous Architecture with Dense Semantic Priors
- Repurposes the VLM from a step-by-step action commander to a 'semantic sensor' that asynchronously updates a 3D value map with target probabilities
- Decouples reasoning and acting: The planner runs at high frequency using the current state of the 3D map, while the VLM slowly refines that map in the background without blocking flight
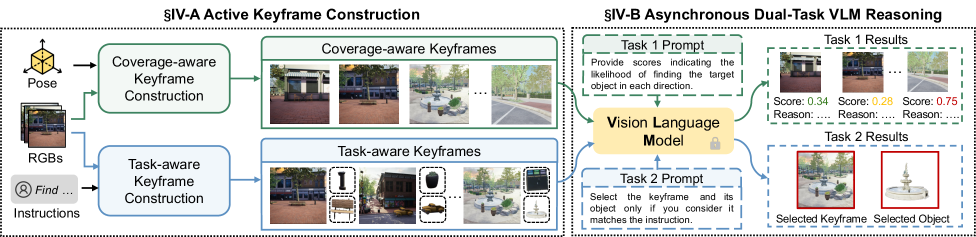
- Uses 'Active Dual-Task Reasoning' to only query the VLM on keyframes that offer new geometric coverage or relevant objects, reducing computational load
Architecture
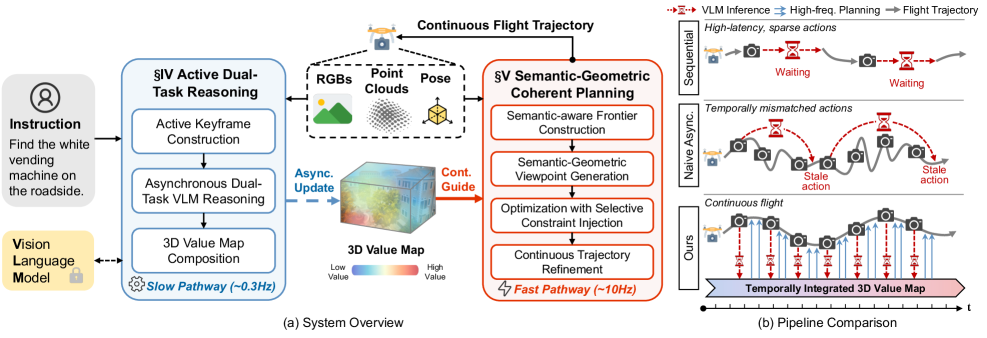
The Dual-Pathway Asynchronous Architecture of AirHunt compared to traditional synchronous methods.
Evaluation Highlights
- Outperforms baselines by 49.1% in success rate across diverse simulation environments
- Reduces navigation error by 80.3% (average error 11.6m) compared to state-of-the-art
- Reduces total flight time by 59.2% by eliminating stop-and-infer pauses and optimizing trajectories
Breakthrough Assessment
8/10
Significant engineering breakthrough in bridging the timescale gap between foundational models (slow) and robotic control (fast). The asynchronous architecture offers a practical template for real-time embodied AI.