📝 Paper Summary
Document Understanding
Vision-Language Models (VLMs)
Efficient Multimodal Learning
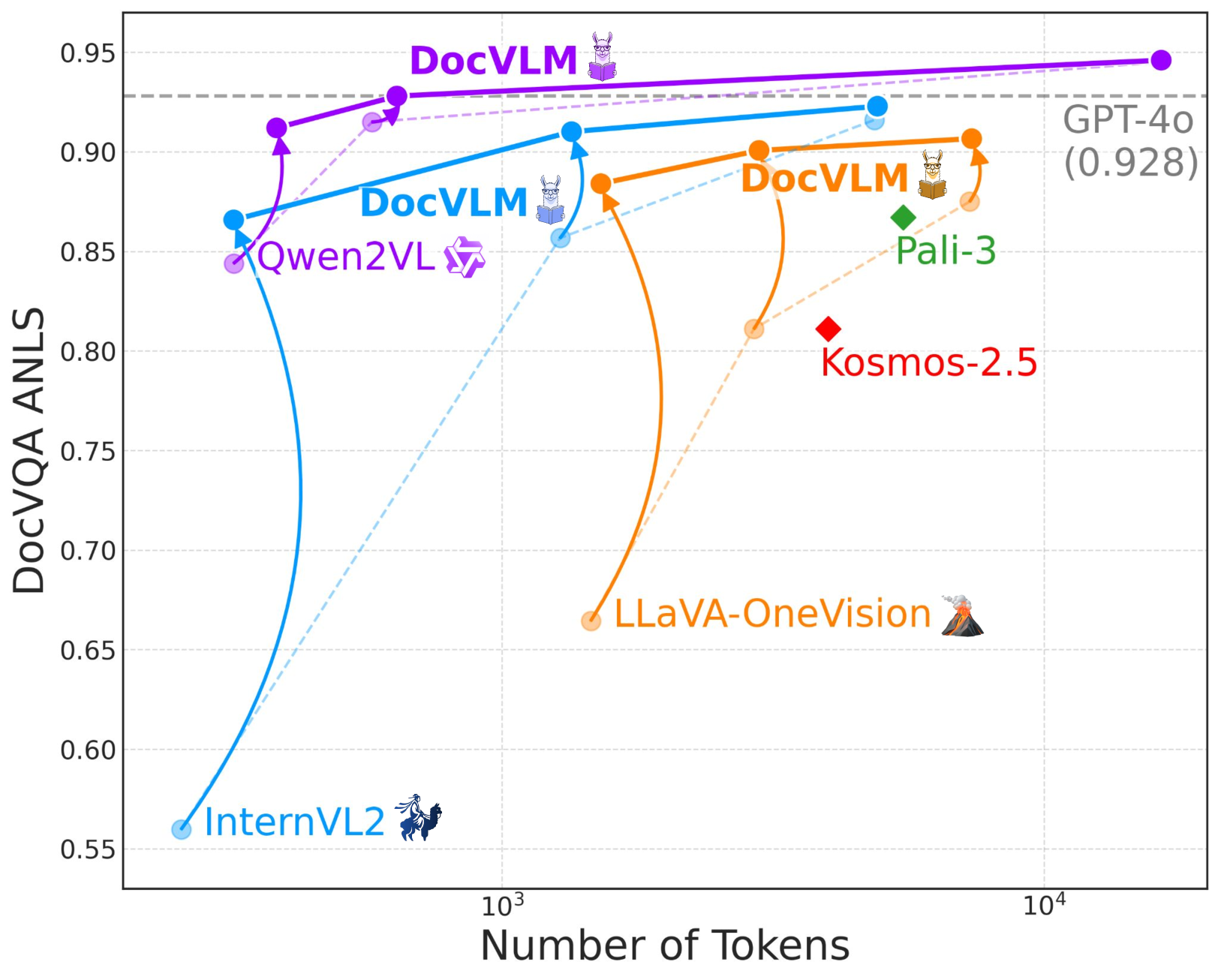
DocVLM integrates a compressed OCR modality into Vision-Language Models to achieve high-performance document understanding with significantly fewer visual tokens, enabling efficient processing of high-resolution and multi-page documents.
Core Problem
Standard Vision-Language Models struggle with document understanding because high-resolution images require excessive computational tokens, while low-resolution inputs lose critical text details.
Why it matters:
- Document analysis requires processing high-resolution inputs to read dense text, which is computationally expensive (quadratic cost for transformers).
- Existing methods that reduce image resolution or token counts (like downsampling) suffer significant performance drops in text-heavy tasks.
- Feeding raw OCR text directly into the prompt loses spatial layout context and creates prohibitively long sequences for multi-page documents.
Concrete Example:
When processing a document with InternVL2 limited to a single 448x448 tile (256 visual tokens), performance on DocVQA drops to 56.0% because the text becomes illegible. DocVLM restores this to 86.6% using the same visual budget by injecting compressed OCR queries.
Key Novelty
Instruction-Aware OCR Compression
- Uses a separate OCR encoder to process text and bounding box data, then compresses this variable-length sequence into a fixed set of learnable queries (typically 64) via cross-attention.
- These compressed queries are injected into the VLM alongside visual tokens, providing high-fidelity text/layout information without the computational cost of high-resolution image tokens.
Architecture
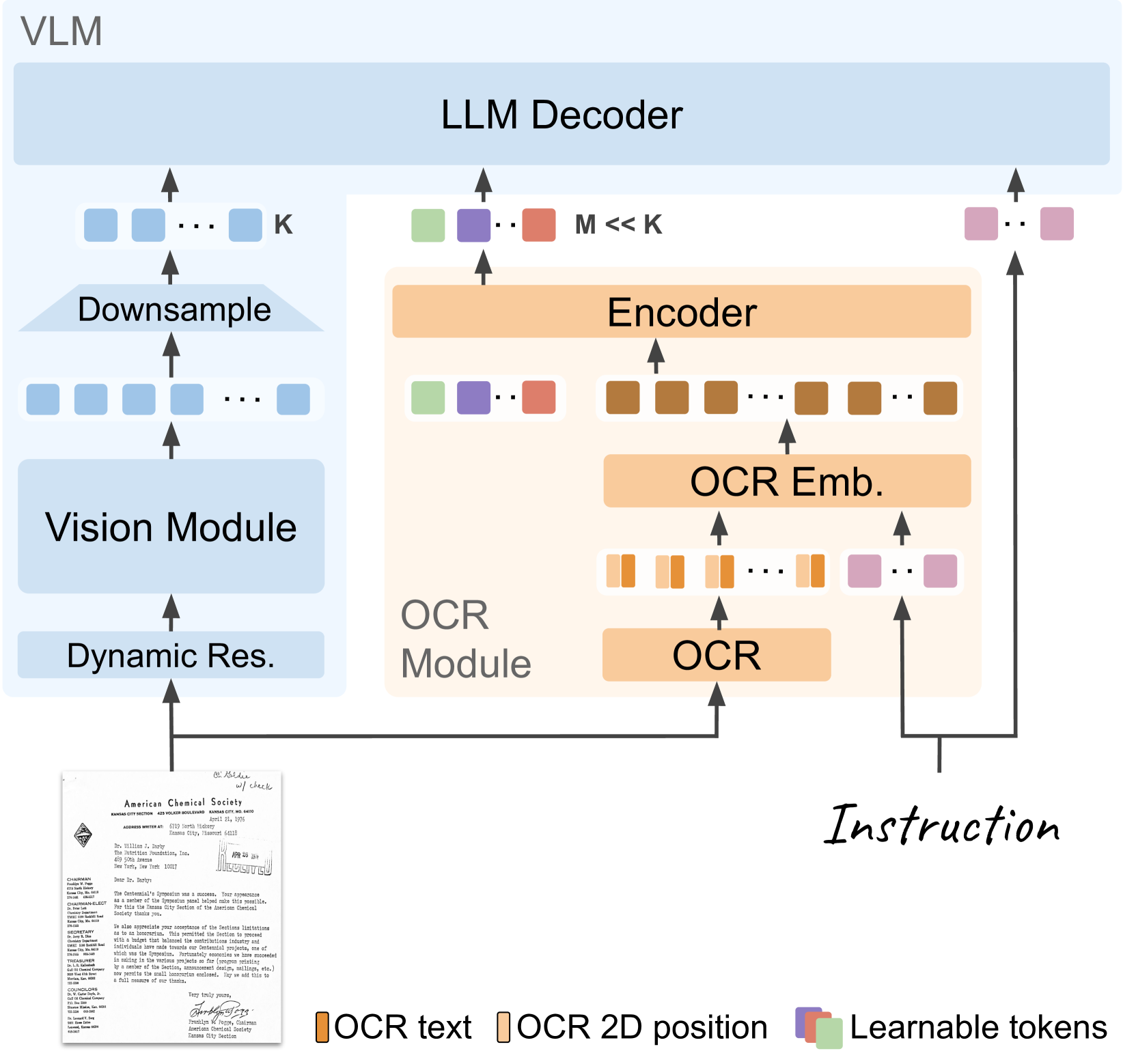
The DocVLM inference pipeline integrating OCR compression with a standard VLM.
Evaluation Highlights
- +30.6% accuracy on DocVQA (56.0% → 86.6%) when integrated with InternVL2 under a strict 256 visual token limit.
- Achieves state-of-the-art 86.3% on MP-DocVQA (multi-page) using 80% fewer tokens than standard high-resolution approaches.
- Outperforms Qwen2-VL baseline on TextVQA (82.8% vs 79.4%) while using significantly restricted visual inputs (576 tokens).
Breakthrough Assessment
8/10
Highly practical solution for the resolution-efficiency trade-off in VLMs. The ability to compress OCR data into just 64 tokens while beating full-resolution baselines is a significant efficiency breakthrough for document tasks.