📝 Paper Summary
Telecom-specific LLMs
Multimodal Benchmarking
MM-Telco provides a comprehensive multimodal benchmark covering 3GPP Release 17 specifications and a fine-tuned model for generating and correcting telecom-specific diagrams.
Core Problem
General-purpose LLMs lack fine-grained domain knowledge for telecom standards (e.g., distinguishing 3GPP releases) and struggle with multimodal tasks like interpreting network diagrams or troubleshooting via packet logs.
Why it matters:
- Telecom standards evolve rapidly; mixing knowledge across versions (e.g., Release 15 vs 17) leads to hallucinations and inconsistent responses
- Practical telecom tasks require reasoning over diverse data formats (text, diagrams, signal visualizations) which current models handle poorly
- Privacy concerns and limited customization of proprietary models hinder their deployment in sensitive telecom network operations
Concrete Example:
When answering questions about network configurations, general models often mix 3GPP Release versions, leading to incorrect protocol implementations. Additionally, they cannot accurately correct incomplete Mermaid.js code for network topology diagrams.
Key Novelty
MM-Telco Benchmark & Llama-VL-Telco Model
- Constructs the first open multimodal benchmark covering all sections of 3GPP Release 17, enabling evaluation of text, image, and cross-modal reasoning
- Develops a fine-tuned VLM (Llama-VL-Telco) capable of generating and updating telecom network diagrams from textual prompts or incomplete visual inputs
Architecture
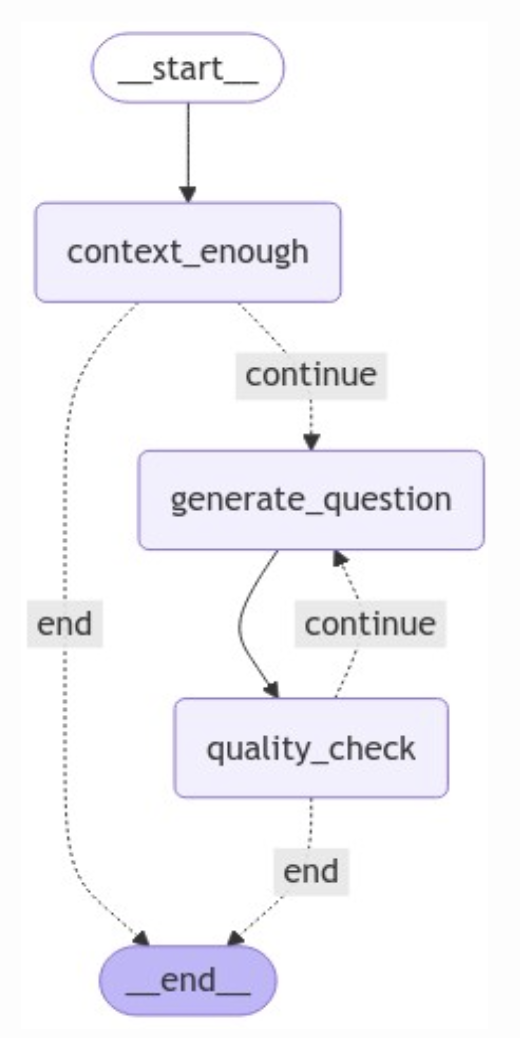
The agentic pipeline used for generating Multiple Choice Questions (MCQs) from 3GPP documents.
Evaluation Highlights
- Generated 2,000 multihop MCQs that require reasoning across multiple global 3GPP Technical Specification documents
- Created 500 scenario-based PCAP (Packet Capture) analysis tasks to evaluate model performance on network troubleshooting and Wireshark filter selection
- Compiled a dataset of 3,766 telecom images and 2,000 image-based MCQs to assess multimodal understanding of system architectures and flows
Breakthrough Assessment
8/10
Addresses a critical gap in telecom AI by providing a large-scale, structured, multimodal benchmark grounded in official 3GPP standards, which is essential for advancing domain-specific LLMs.