📝 Paper Summary
Multimodal Evaluation Benchmark
Multimodal Content Comprehension
MM-BigBench evaluates Multimodal Large Language Models (MLLMs) on tasks requiring deep comprehension of text-image relationships (like sarcasm and sentiment), moving beyond simple visual recognition questions.
Core Problem
Existing MLLM benchmarks (e.g., MME, MM-Vet) focus on visual-centric tasks like recognition or spatial reasoning where text is merely a query, neglecting 'multimodal content comprehension' where understanding the text content itself is crucial.
Why it matters:
- Real-world applications like social media analysis require detecting nuanced relationships between text and images (e.g., sarcasm, hate speech) which current benchmarks miss
- Prior evaluations often assess models or instructions in isolation, ignoring the specific adaptability between model architectures and instruction formats
- There is a lack of understanding regarding how MLLMs perform on tasks that require semantic fusion of both modalities rather than just visual grounding
Concrete Example:
In Multimodal Sarcasm Recognition, a tweet text might say 'Summer fun day' while the image depicts a gloomy storm. A model trained only on standard VQA might identify 'storm' but fail to detect the sarcasm because it doesn't deeply comprehend the semantic conflict between the text and image content.
Key Novelty
MM-BigBench Evaluation Framework
- Shifts evaluation focus from visual-dominant tasks (VQA) to multimodal content comprehension tasks (MSA, Sarcasm, Hate Speech) where text and image carry equal semantic weight
- Introduces a multi-dimensional metric suite assessing not just accuracy but also Stability (consistency across instructions) and Adaptability (how well a model pairs with specific prompt styles)
- Benchmarks 20 models (including 14 MLLMs) using 10 diverse manually designed instructions per task to analyze sensitivity to prompt engineering
Architecture
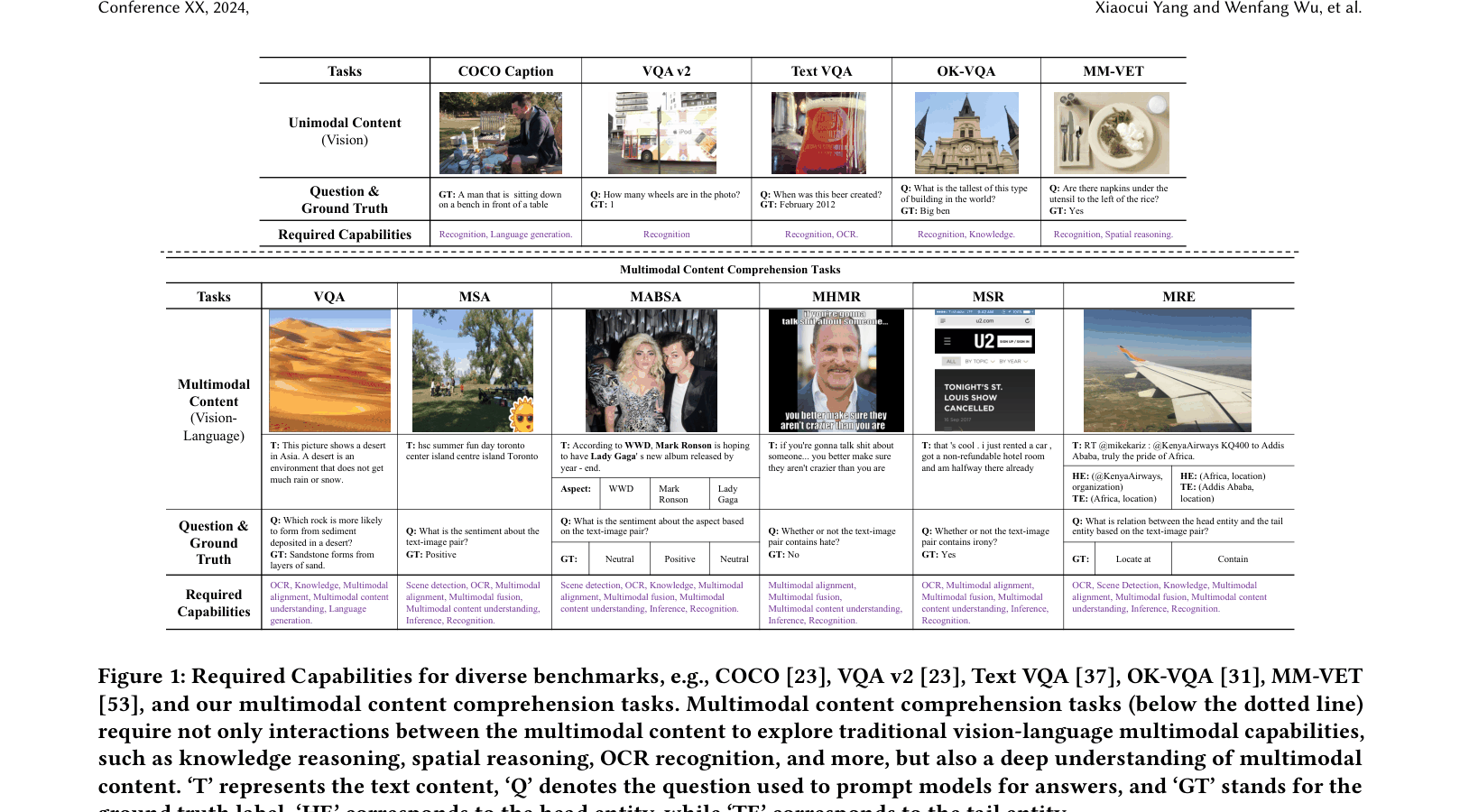
A conceptual comparison between traditional Vision-Language tasks (above dotted line) and Multimodal Content Comprehension tasks (below dotted line)
Evaluation Highlights
- InstructBLIP achieves the highest total accuracy score (736.72) across all datasets, outperforming the next best model (BLIP-2 at 637.21) significantly
- Encoder-Decoder models (like Flan-T5-XXL) generally outperform Decoder-only models (like LLaMA series) on these comprehension tasks, with Flan-T5-XXL scoring 618.23 total vs. LLaMA-2-13B's 549.50
- Instruction #2 (Question-Answer format) shows the highest adaptability, achieving Top-K performance 340 times across models, compared to just 80 times for Instruction #7
Breakthrough Assessment
7/10
Provides a necessary shift in evaluation focus towards deeper semantic alignment tasks. While it doesn't propose a new model architecture, the comprehensive benchmarking of instruction sensitivity is valuable.
