📝 Paper Summary
3D Representation Learning
Self-Supervised Learning
Multi-Modal Learning (2D-3D)
MM-Point enhances self-supervised 3D point cloud learning by maximizing mutual information between 3D objects and multiple 2D views simultaneously, using multi-level feature projection and incremental augmentation strategies.
Core Problem
Existing self-supervised 3D methods often rely solely on intra-modal data or simple 2D-3D alignment, failing to fully exploit the rich semantic information available across multiple diverse 2D views of the same object.
Why it matters:
- 3D data annotation is expensive and scarce, making self-supervised learning critical for real-world applications like autonomous driving and robotics.
- Single-view 2D rendering provides limited information; leveraging multi-view consistency can provide superior supervision signals for 3D understanding.
- Simple alignment between 3D and 2D modalities can lead to negative transfer due to their distinct nature; sophisticated interaction strategies are needed.
Concrete Example:
A simple contrastive method might align a 3D chair with a single frontal 2D image. If the 2D view is occluded or ambiguous, the 3D representation degrades. MM-Point aligns the 3D chair with multiple views (front, side, top) simultaneously, ensuring the 3D feature captures the complete object geometry regardless of single-view ambiguity.
Key Novelty
Simultaneous Multi-View 2D-3D Contrastive Learning
- Treats each rendered 2D view as a unique pattern containing partial information about the 3D object, enforcing consistency across all views simultaneously rather than pairwise.
- Uses a 'Multi-MLP' strategy to project features into multiple distinct spaces, allowing the model to capture different levels of semantic information for each view.
- Employment of an incremental 'Multi-level Augmentation' strategy where different 2D views receive progressively stronger data augmentations to encourage learning of robust invariant features.
Architecture
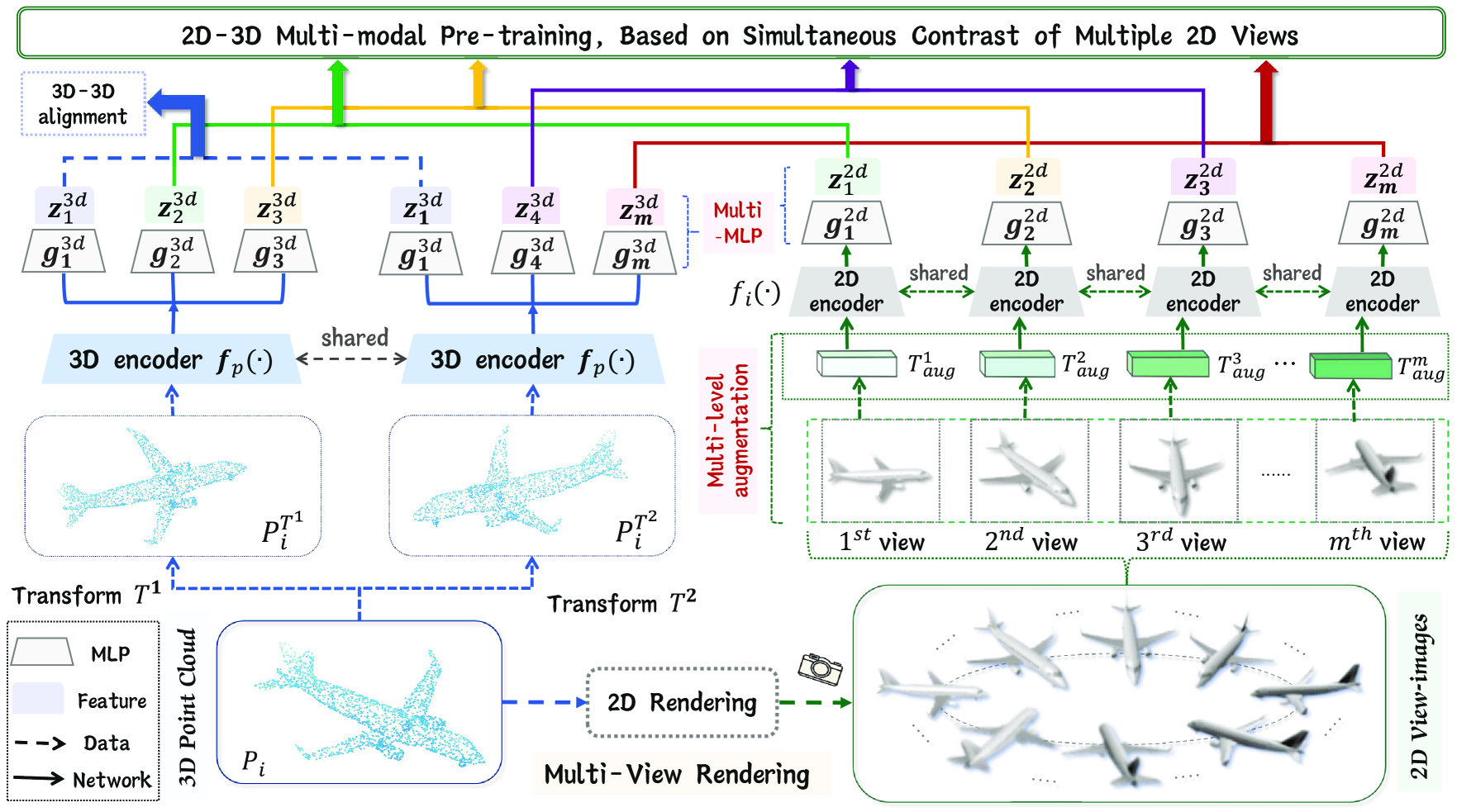
The overall MM-Point architecture, illustrating the parallel Intra-modal (3D-3D) and Inter-modal (2D-3D) contrastive learning pathways.
Evaluation Highlights
- Achieves 92.4% accuracy on ModelNet40 (synthetic 3D object classification), setting a new state-of-the-art for self-supervised methods.
- Achieves 87.8% accuracy on ScanObjectNN (real-world 3D object classification), surpassing previous self-supervised baselines and comparable to fully supervised methods.
- Demonstrates effective transfer learning capability in 3D part segmentation and semantic segmentation tasks.
Breakthrough Assessment
8/10
Strong performance on standard benchmarks (ModelNet40, ScanObjectNN) surpassing existing self-supervised methods. The approach of simultaneous multi-view contrast with multi-level augmentation is a logical and effective extension of prior cross-modal work.