📝 Paper Summary
Financial Domain Adaptation
Continual Learning
Model Merging
SPEAR-MM preserves general reasoning in financial LLMs by identifying critical parameters via spectral analysis after domain training and selectively restoring them from the base model using spherical interpolation.
Core Problem
Adapting LLMs to the financial domain via continual pretraining (CPT) causes catastrophic forgetting of general reasoning skills (e.g., mathematics, logic), while traditional fixes like rehearsal violate privacy or lack capacity.
Why it matters:
- Financial institutions need models that understand proprietary data but must also retain general reasoning for complex analysis and customer support.
- Existing solutions like EWC require expensive hyperparameter tuning, and rehearsal methods require storing sensitive data, violating strict financial privacy regulations.
- Retraining to find the right balance between specialization and generalization is computationally prohibitive (thousands of GPU hours per configuration).
Concrete Example:
A standard LLaMA-3.1-8B model adapted on financial documents improves at answering regulatory questions but its ability to solve GSM8K math problems drops from ~80% to ~55% (69.5% retention), making it unreliable for quantitative analysis.
Key Novelty
Post-Hoc Selective Parameter Restoration via Spectral Analysis
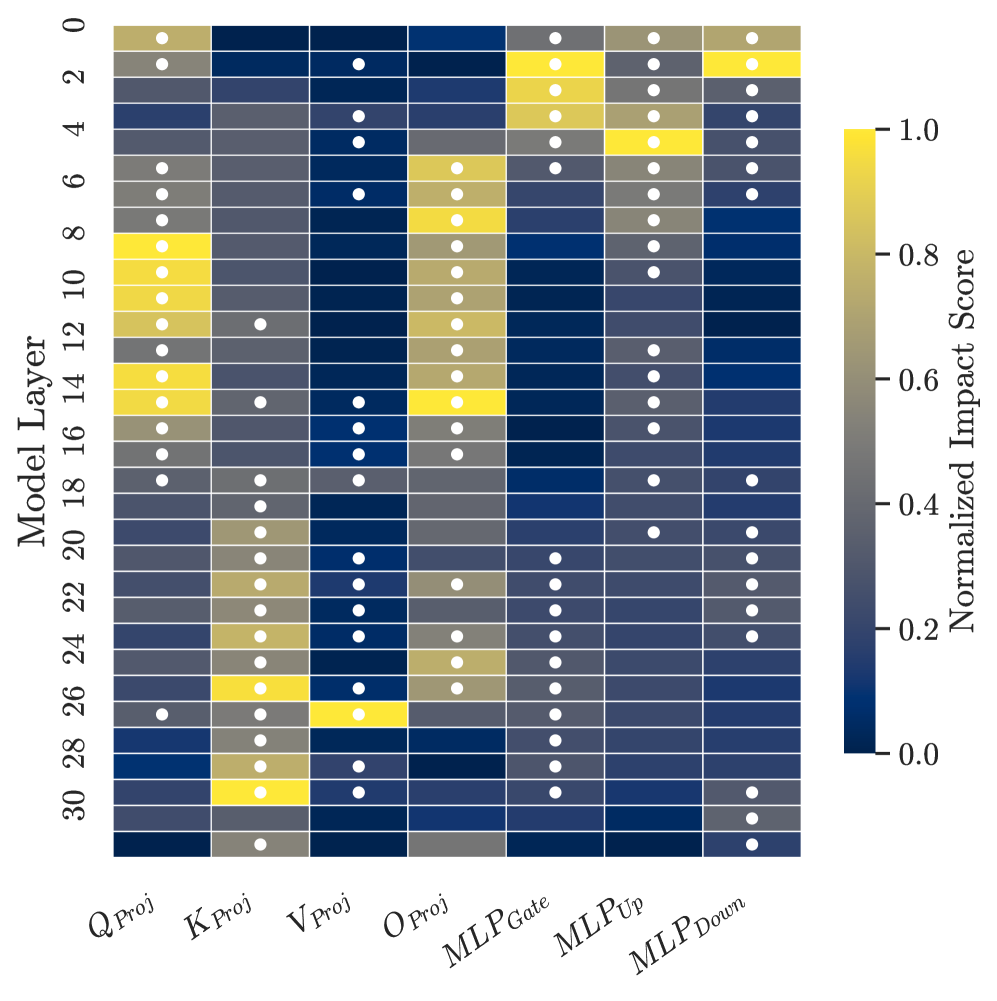
- Instead of constraining the model during training, SPEAR-MM analyzes the fully adapted model to measure which layers drifted significantly using signal-to-noise ratio (SWCI) and structural rank changes (SVDR).
- It selectively restores the 'drifting' parameters that caused forgetting by merging them back towards the base model using Spherical Linear Interpolation (SLERP), creating a hybrid model without retraining.
Architecture
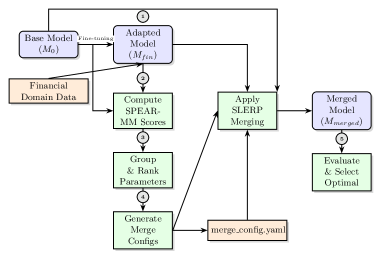
The SPEAR-MM workflow pipeline.
Evaluation Highlights
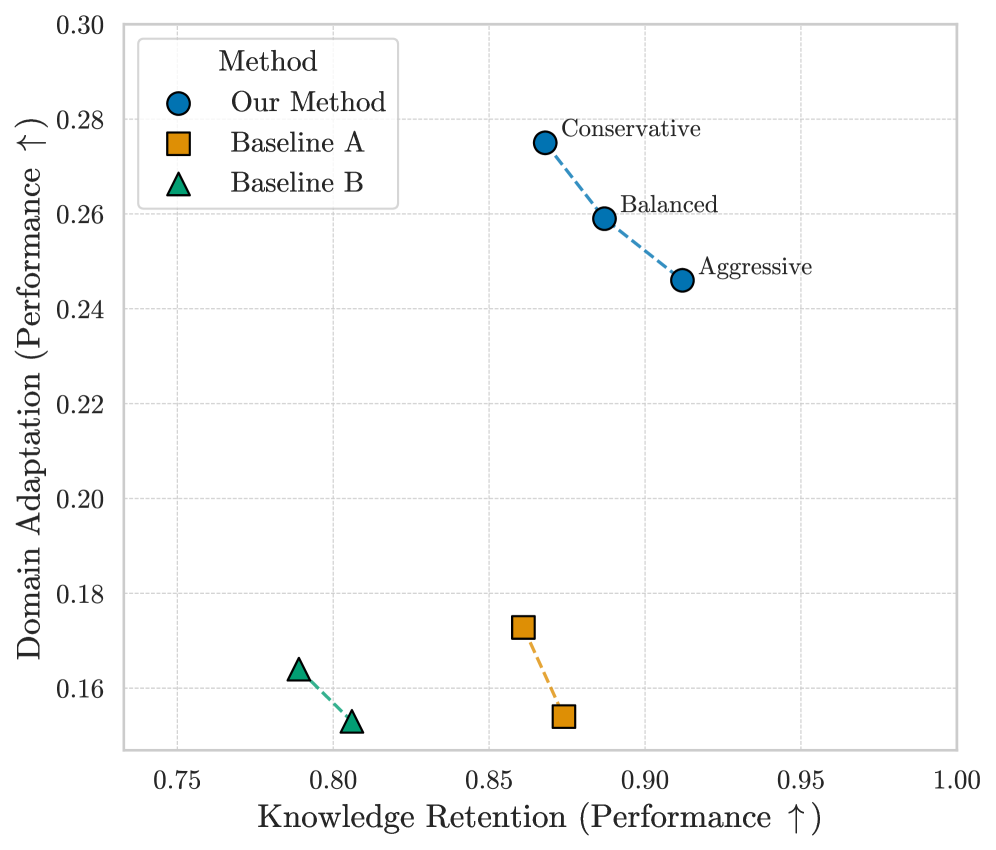
- Achieves 91.2% retention of general capabilities (vs. 69.7% for standard CPT) on LLaMA-3.1-8B while maintaining 94% of financial domain adaptation gains.
- Reduces computational costs by >99% compared to exploring freezing strategies via retraining (1.5 GPU-hours for analysis vs. 18,000+ GPU-hours for CPT).
- Restores mathematical reasoning (GSM8K) to 97.5% of the base model's performance, compared to just 69.5% retention for the standard CPT baseline.
Breakthrough Assessment
8/10
Offers a highly practical, privacy-preserving solution for regulated industries. drastic compute reduction for exploring trade-offs makes it very adoptable, though it relies on existing merging techniques (SLERP).