📝 Paper Summary
Vision Language Models (VLMs)
Self-Evolving Systems
MM-Zero enables Vision Language Models to self-evolve reasoning capabilities without external data by using a tri-role framework where agents propose tasks, generate executable code to render images, and solve them.
Core Problem
Self-evolving VLMs typically require seed image data, making them dependent on the quality and diversity of collected datasets and limiting scalability compared to text-only LLMs.
Why it matters:
- Collecting and filtering image data is costly, labor-intensive, and limits the diversity of scenarios a model can learn from
- Existing proposer-solver pipelines for VLMs remain bounded by the static distribution of pre-collected images
- Synthetic generation via code allows for virtually unlimited variations and complex scenarios (e.g., charts, geometry) that are hard to mine from the web
Concrete Example:
A standard VLM self-training loop might retrieve a static image of a chart and ask questions about it. If the dataset lacks complex 3D function plots, the model never improves on them. MM-Zero's Coder can write Python/SVG code to render a new, specific 3D plot requested by the Proposer, creating the training data on the fly.
Key Novelty
Tri-Role Zero-Data Self-Evolution
- Expands the standard Proposer-Solver dual model to a three-agent system (Proposer, Coder, Solver) to bridge abstract concepts and visual data via code
- Uses executable code (SVG/Python) as an intermediate representation to programmatically generate visual training data rather than retrieving existing images
- Implements a 'Goldilocks' reward mechanism where the Proposer is incentivized to generate tasks that are challenging but solvable for the Solver
Architecture
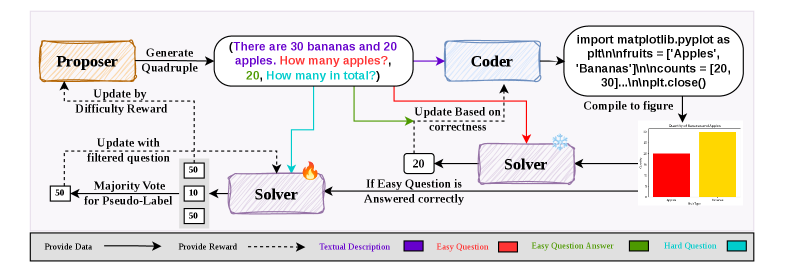
The tri-role self-evolving training framework comprising Proposer, Coder, and Solver.
Breakthrough Assessment
9/10
Proposes a theoretically significant shift from data-driven to code-driven visual self-evolution, potentially removing the data bottleneck for VLM reasoning entirely.