📝 Paper Summary
LLM Compression
Edge Language Models
Structured Pruning
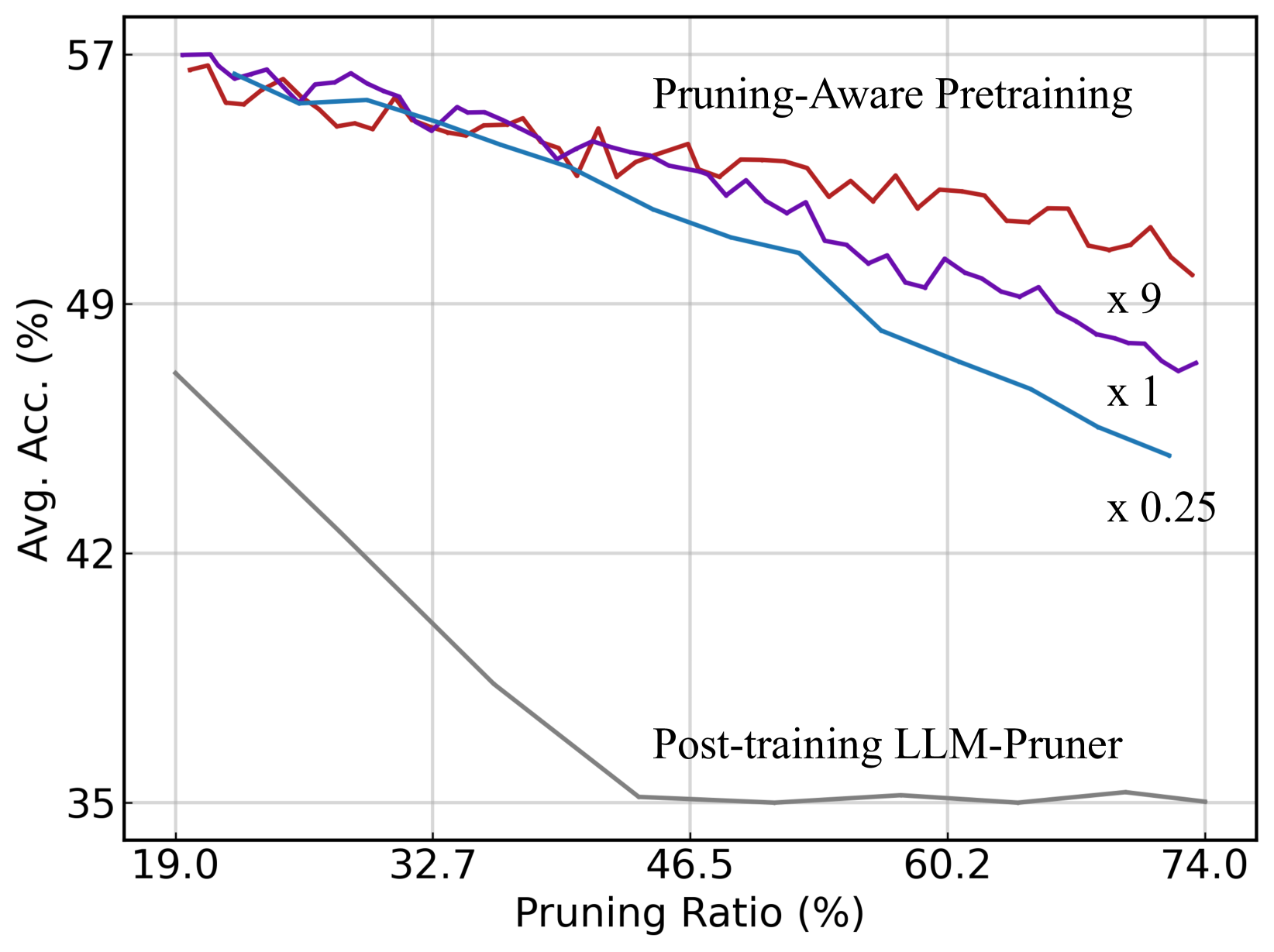
EfficientLLM introduces pruning-aware pretraining, which continuously prunes a larger, optimized source model during pretraining using scalable saliency metrics to create high-performance edge models.
Core Problem
Training compact edge models (100M-1B) via direct pretraining is limited by scaling laws, while post-training pruning suffers significant performance degradation due to small calibration datasets.
Why it matters:
- Edge devices require compact models for low latency and privacy, but tiny models lack the 'intelligence emergence' of larger counterparts
- Directly pretraining small models is data-inefficient compared to larger models
- Existing pruning methods rely on limited calibration data (post-training), failing to scale or recover performance fully
Concrete Example:
Directly pretraining a tiny model like Pythia-410M yields suboptimal results compared to pruning a larger model. Conversely, standard post-training pruning of Llama-7B using only small calibration sets degrades accuracy significantly compared to the proposed method.
Key Novelty
Pruning-Aware Pretraining (scaling up pruning)
- Integrates structural pruning directly into the pretraining phase rather than as a post-training step, allowing the pruning process to scale with massive datasets
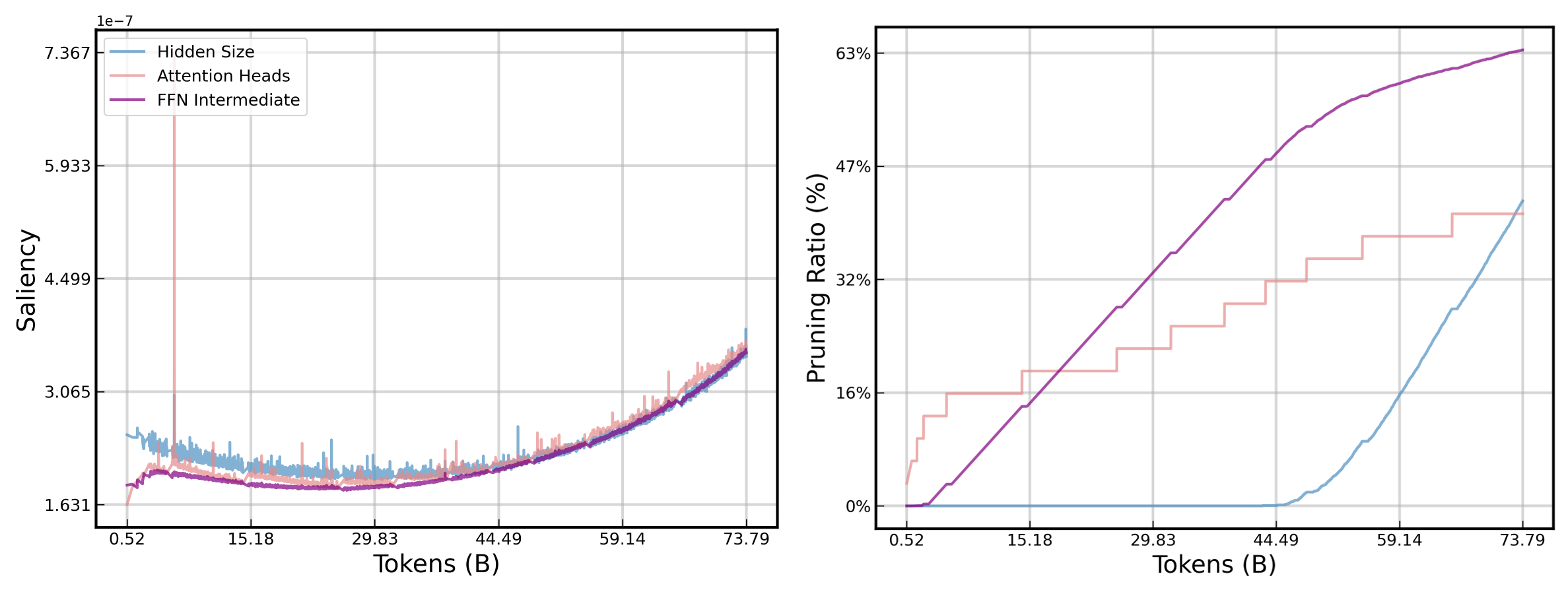
- Defines 'minimal parameter groups' (mini-groups) that are dynamically pruned based on saliency, allowing the model architecture to be auto-designed rather than human-engineered
- Decouples Hessian approximation for saliency detection (global diagonal) and weight updating (layerwise) to make second-order optimization feasible during pretraining
Architecture
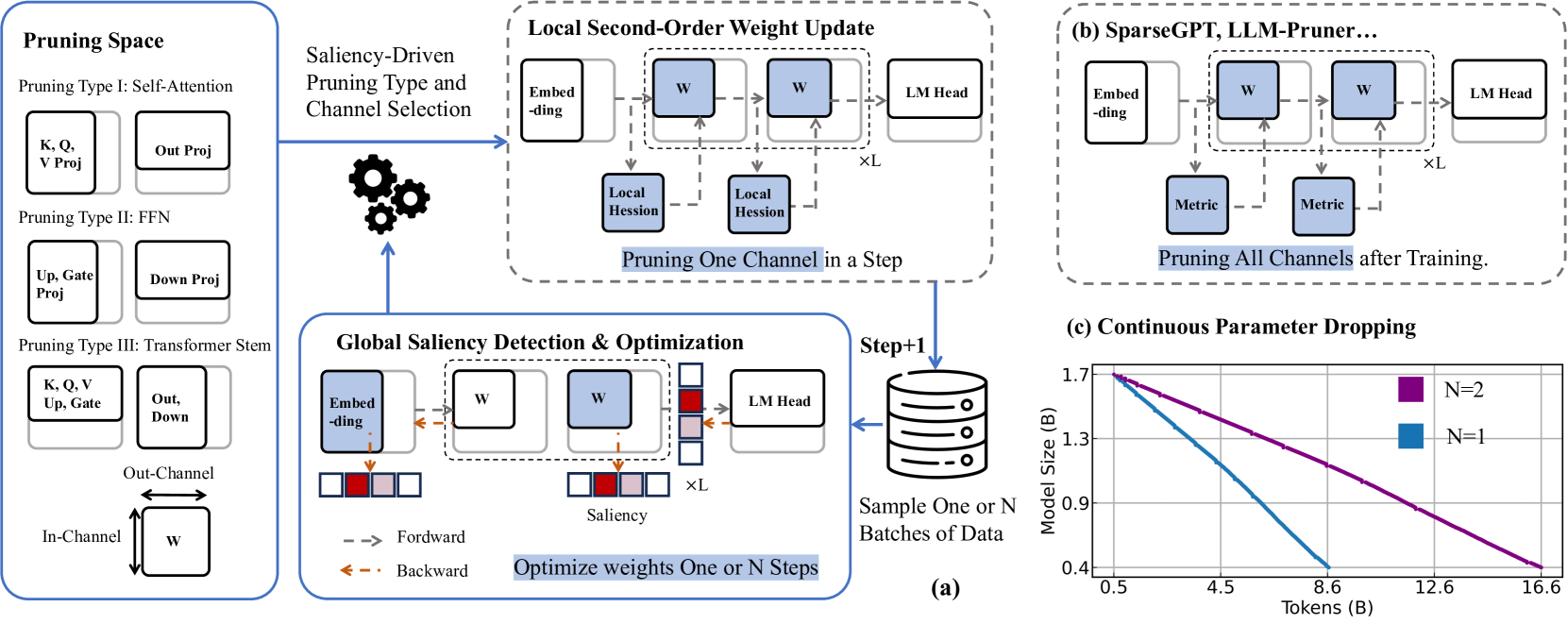
Overview of Pruning-Aware Pretraining pipeline
Evaluation Highlights
- EfficientLLM-469M (50B tokens) outperforms SmolLM-360M (600B tokens) in Common Sense Reasoning, demonstrating superior data efficiency
- EfficientLLM-134M exceeds Pythia-410M by 4.13% average accuracy despite being significantly smaller
- Scaling up vanilla LLM-Pruner in the pretraining stage improves accuracy by >10% compared to standard post-training usage
Breakthrough Assessment
8/10
Significantly bridges the gap between direct pretraining and compression. Shows that 'pruning as pretraining' beats both dedicated tiny-model training and standard post-training compression.