📊 Experiments & Results
Evaluation Setup
Text-guided image editing on standard benchmarks
Benchmarks:
- PIE-Bench (Image Editing)
- TEDBench++ (Image Editing)
- EditEval (Image Editing)
Metrics:
- Editing Fidelity (implied)
- Image Quality (implied)
- Statistical methodology: Not explicitly reported in the paper
Experiment Figures
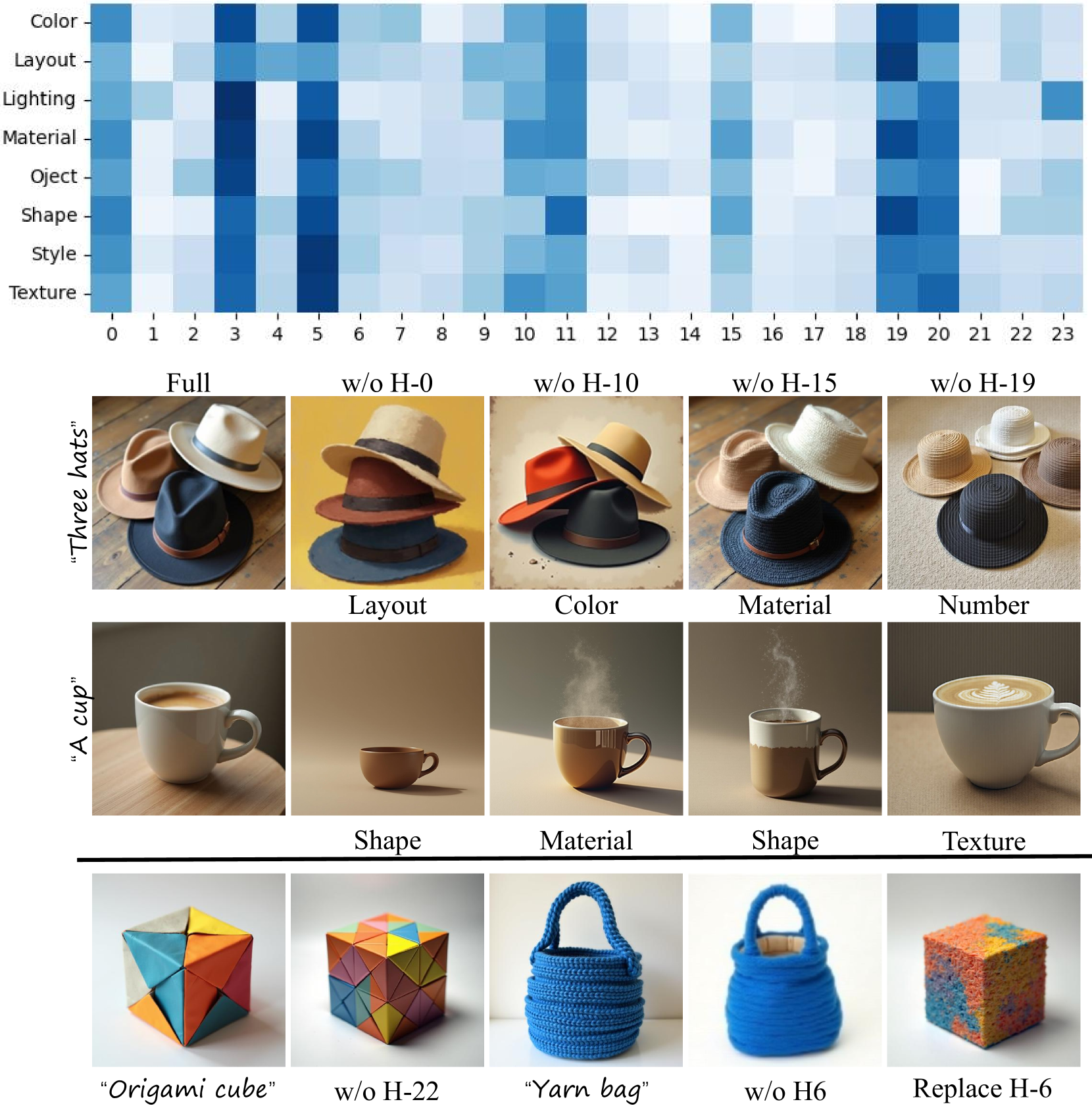
Heatmap of attention head sensitivity across different semantics, and visual results of head dropout/swapping
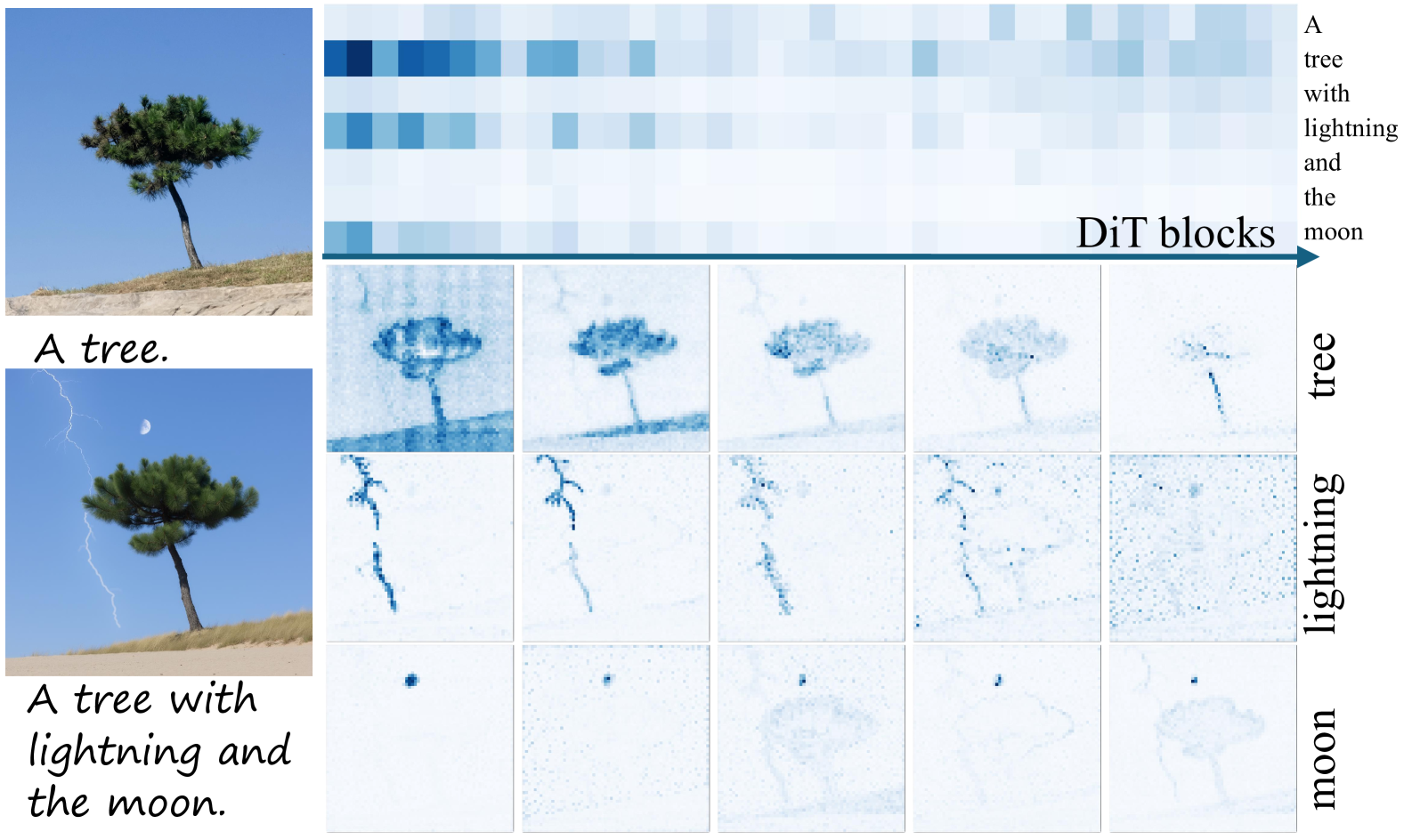
Heatmap of text-image token interaction weights and a plot of text token attention weight across blocks
Main Takeaways
- Attention heads in MM-DiTs are not uniform; they exhibit distinct sensitivities to different image semantics (e.g., some track color, others track shape)
- Text guidance in MM-DiTs naturally wanes as the network depth increases, unlike in UNets where it remains constant via cross-attention layers
- Qualitative analysis shows that identifying and boosting sensitive heads (HeadRouter) leads to more accurate semantic injection compared to uniform processing
- Analysis of token interactions reveals that while text and image tokens are entangled, there are specific 'critical regions' in the joint attention map where text strongly influences image generation