📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Reasoning and Chain-of-Thought (CoT) Evaluation
Hallucination detection
MM-THEBench evaluates the intermediate thinking process of reasoning MLLMs, revealing that models often produce correct final answers despite hallucinations in perception or reasoning steps.
Core Problem
Current benchmarks for reasoning MLLMs focus only on final answer correctness, ignoring the internal 'thinking' process. This masks cases where models get the right answer for the wrong reasons due to hallucinations in intermediate steps.
Why it matters:
- Reasoning MLLMs (like OpenAI o1/o3) generate long Chains-of-Thought (CoT), but users cannot verify if the reasoning is sound or coincidentally correct
- Existing hallucination benchmarks lack fine-grained taxonomies for intermediate steps, failing to distinguish between perceptual errors and logical failures during the thinking process
- The free-form, unstructured nature of intermediate CoTs makes scalable automated evaluation difficult compared to simple final-answer checking
Concrete Example:
A model might correctly identify a final answer to a visual question, but its intermediate CoT claims to see objects that aren't there (perception hallucination) or uses flawed logic (reasoning hallucination). For instance, correctly guessing a physics problem answer while misinterpreting the diagram's forces.
Key Novelty
MM-THEBench (Multimodal Thinking Hallucination Evaluation Benchmark)
- Introduces a fine-grained, two-layer hallucination taxonomy for intermediate thoughts, categorizing errors into three cognitive dimensions: Knowledge, Perception, and Reasoning
- Transforms existing datasets into a process-aware benchmark by annotating 1,340 questions with verified atomic reasoning steps and evaluation rubrics
- Implements a multi-level automated evaluation framework using an LLM-as-a-judge to assess answer accuracy, step-level alignment, and rubric-based hallucination scoring
Architecture
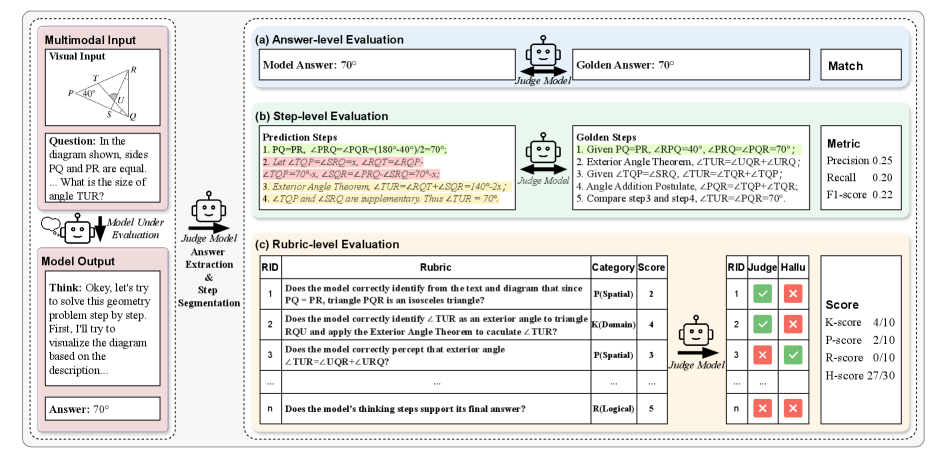
The MM-THEBench evaluation framework, illustrating the pipeline from model output to multi-level evaluation.
Evaluation Highlights
- Qwen3-VL-235B-A22B-Thinking achieves the highest final answer accuracy (70.62%) on image tasks, but intermediate step precision is only 22.75%
- Thinking correctness consistently lags behind final answer accuracy across 14 models; e.g., GPT-5 shows high accuracy but lower rubric scores in perception compared to reasoning
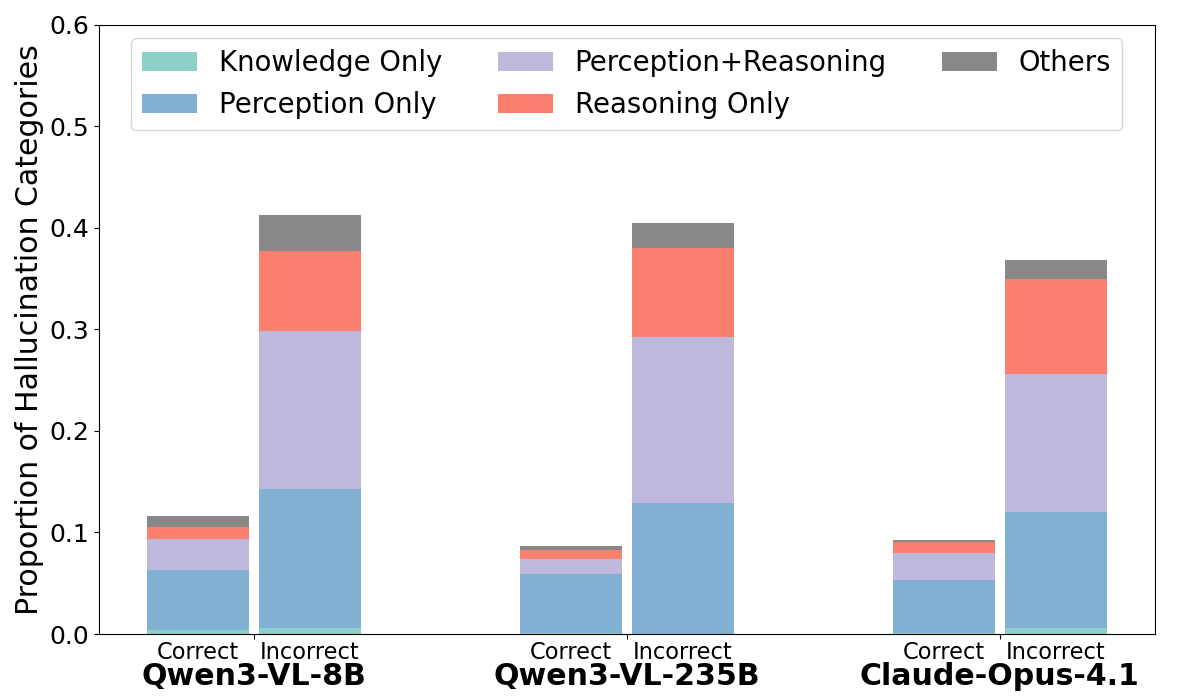
- Perception hallucinations are the most frequent error type but rarely cause wrong answers, whereas reasoning hallucinations are strongly correlated with incorrect final outcomes
Breakthrough Assessment
8/10
Significant contribution to the interpretability of reasoning MLLMs. It moves evaluation beyond final-answer accuracy to the validity of the reasoning process itself, addressing a critical gap in trustworthy AI.