📝 Paper Summary
Multimodal Math Reasoning
Large Multimodal Models (LMMs) Evaluation
Process Evaluation
MM-MATH is a multimodal math benchmark comprising 5,929 problems that evaluates LMMs not just on final answers but also on reasoning steps, revealing that diagram misinterpretation is the primary cause of failure.
Core Problem
Existing multimodal math benchmarks rely on binary answer comparisons, failing to identify why models fail (e.g., visual misunderstanding vs. reasoning errors) or where their specific weaknesses lie.
Why it matters:
- Current LMMs like GPT-4V still underperform on math tasks requiring interleaved text and image reasoning, but the specific failure modes remain opaque
- Outcome-only evaluation hides whether a correct answer was derived from correct reasoning or lucky guessing
- Lack of fine-grained metadata (difficulty, grade, knowledge point) in prior benchmarks hinders targeted improvement of model capabilities
Concrete Example:
In a geometry problem where 'D is the midpoint of AB', a model might incorrectly reason 'AD=AB' instead of 'AD=DB'. A standard benchmark simply marks the final answer wrong; MM-MATH identifies this specific intermediate step as a 'Reasoning error' using LMM-as-a-judge.
Key Novelty
Process Evaluation via LMM-as-a-Judge
- Combines traditional outcome evaluation with a process evaluation pipeline that compares model-generated steps against a groundtruth solution
- Uses GPT-4V to identify the *first* error in a solution trace and categorize it into four specific types (e.g., Diagram misinterpretation, Calculation error)
- Includes extensive metadata (difficulty, grade level, knowledge points) for fine-grained performance analysis rather than a single aggregate score
Architecture
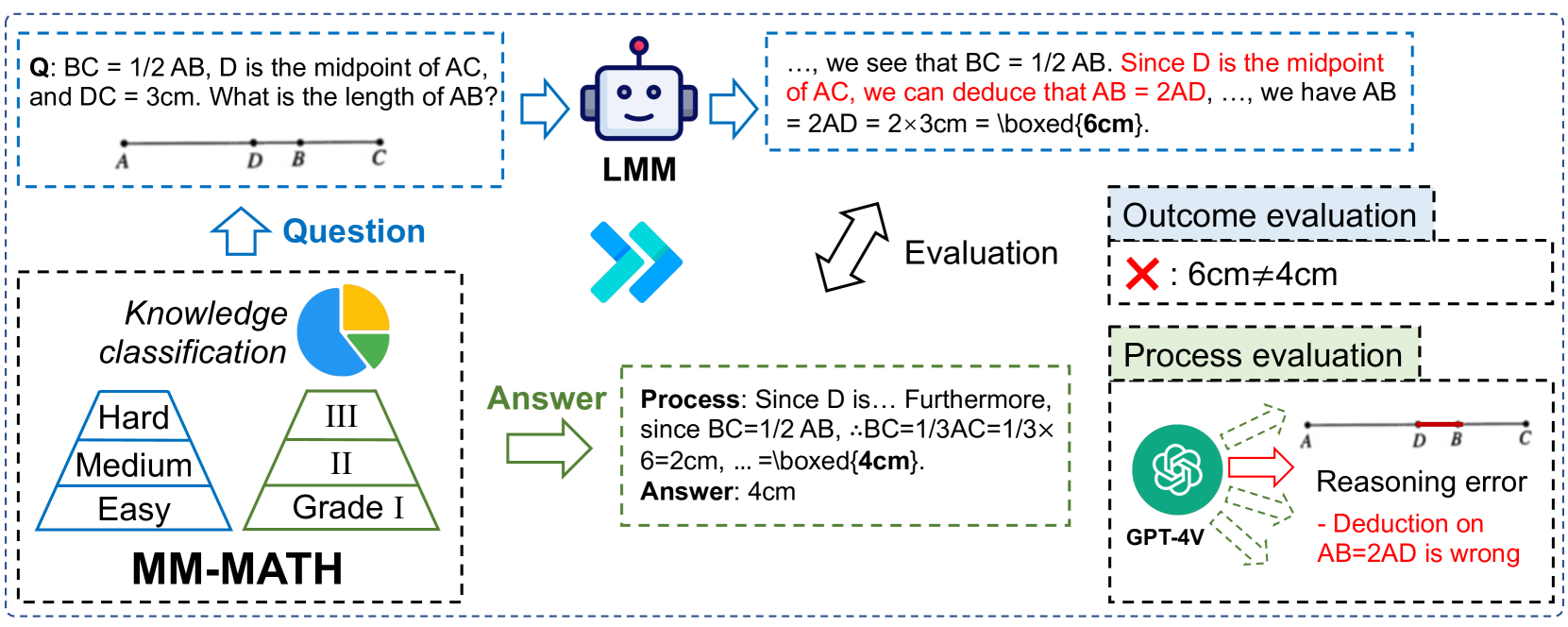
Overview of the MM-MATH benchmark construction and evaluation pipeline.
Evaluation Highlights
- GPT-4o achieves only 31.8% accuracy on MM-MATH, significantly lagging behind the human student average of 80.4%
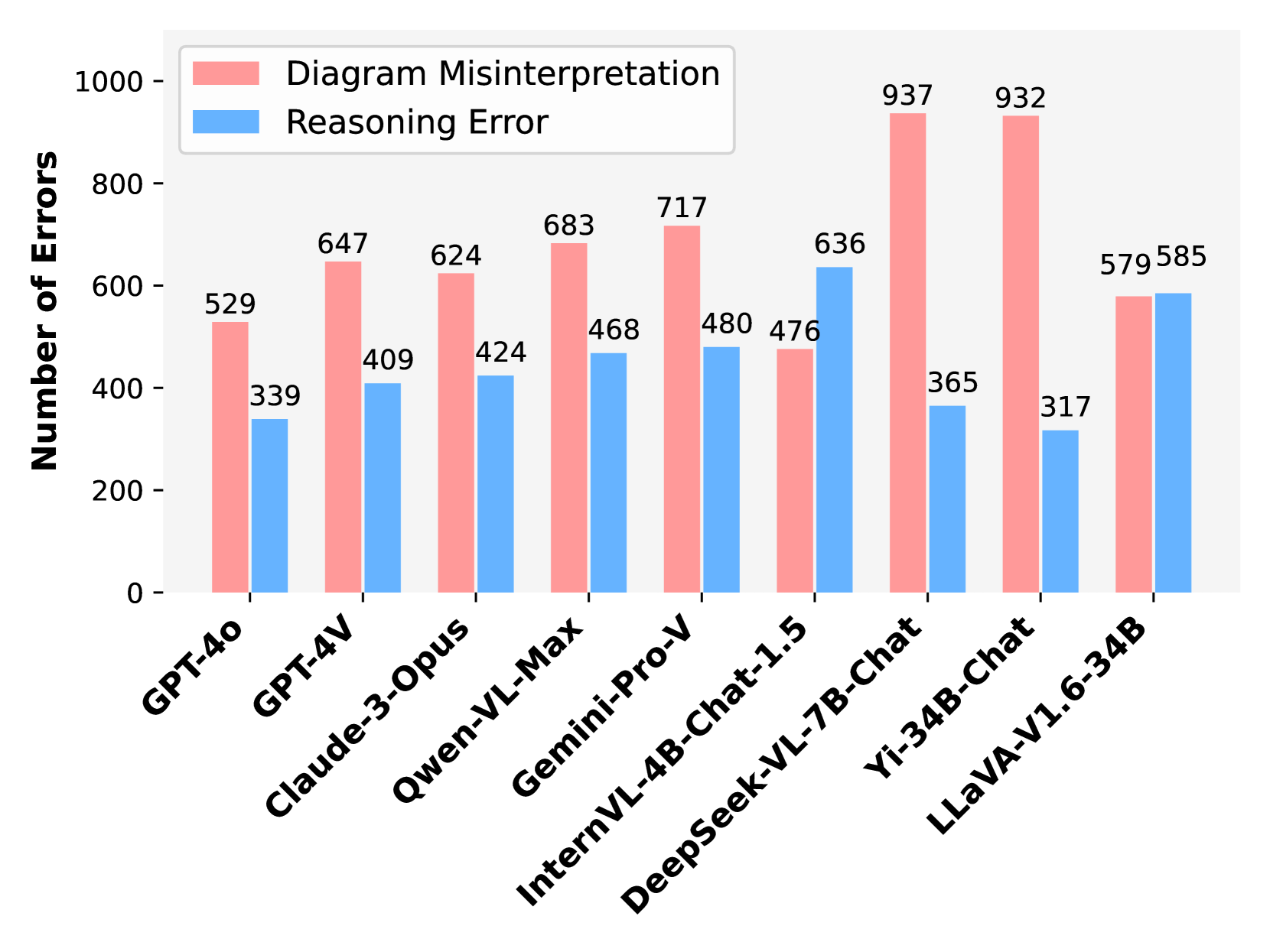
- Diagram misinterpretation accounts for >50% of errors across major LMMs (GPT-4o, GPT-4V, Claude-3-Opus), highlighting a critical vision-reasoning gap
- Multimodal inputs (text+image) improve performance by only 2-4% over text-only inputs for top models, suggesting LMMs struggle to effectively utilize visual contexts
Breakthrough Assessment
8/10
While the dataset scale is moderate, the shift from binary outcome to process-oriented error analysis is a significant methodological improvement for understanding LMM reasoning failures.