📝 Paper Summary
Multimodal Dialogue Systems
Affective Computing
E3RG is a training-free modular system that explicitly conditions speech and video generation on MLLM-predicted emotions to ensure multimodal alignment and identity consistency.
Core Problem
Existing empathetic response systems rely on expensive fine-tuning and often fail to synchronize emotional cues across text, audio, and video, leading to inconsistent or disjointed avatars.
Why it matters:
- Inconsistent emotional cues (e.g., sad text with a happy face) break user immersion and trust in human-computer interaction
- Current end-to-end training approaches are computationally expensive and struggle to generalize to new identities without retraining
- Maintaining identity consistency (voice timbre and facial appearance) across long conversations is difficult for standard generative models
Concrete Example:
If a user shares a traumatic car accident story, a standard system might generate text saying 'That sounds scary' but deliver it with a neutral robot voice and a smiling face, creating a jarring, unempathetic interaction. E3RG explicitly forces the TTS and video generator to use a 'Fear/Sad' style.
Key Novelty
Explicit Emotion-Driven Modular Generation
- Decomposes the complex generation task into three discrete, training-free stages: understanding (predicting emotion label), retrieval (fetching specific voice/face references), and generation (conditioning separate models on the label)
- Uses the predicted emotion label as an explicit control signal for independent state-of-the-art generative models (OpenVoice, DICE-Talk) rather than relying on implicit latent space alignment
Architecture
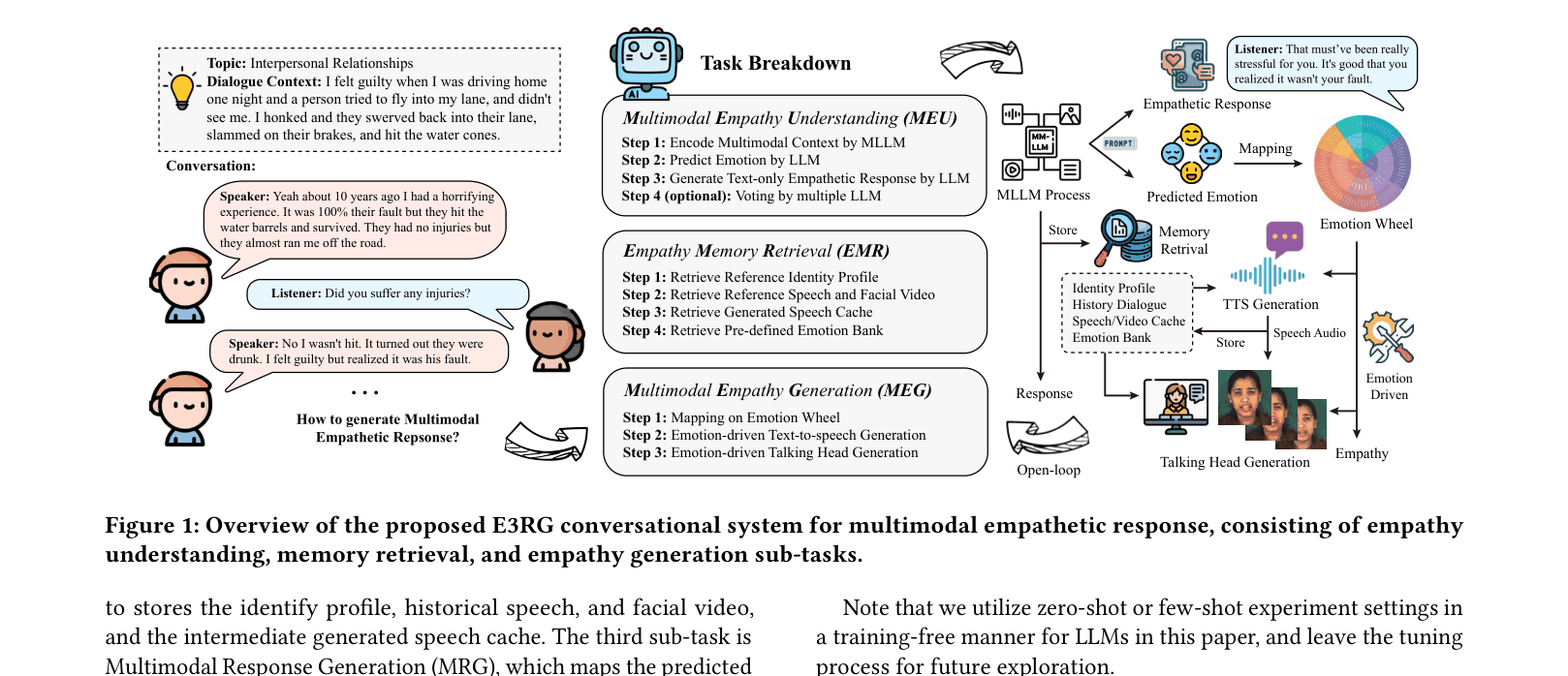
The complete workflow of the E3RG system, illustrating the decomposition into three sub-tasks: Empathy Understanding, Memory Retrieval, and Empathy Generation.
Evaluation Highlights
- Secured Top-1 position in the Avatar-based Multimodal Empathy Challenge at ACM MM'25
- Achieves 76.3% HIT Rate (emotion prediction accuracy) with Ola-Omni-7B in a 3-shot setting, outperforming text-only baselines
- Scored 4.03 average in human evaluation, surpassing the second-place team (3.83) in expressiveness, consistency, and naturalness
Breakthrough Assessment
7/10
Effective system integration that won a top-tier challenge. While it relies on off-the-shelf components (OpenVoice, DICE-Talk), the explicit emotion-driven control flow solves key consistency issues without training.
