📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Mathematical Reasoning
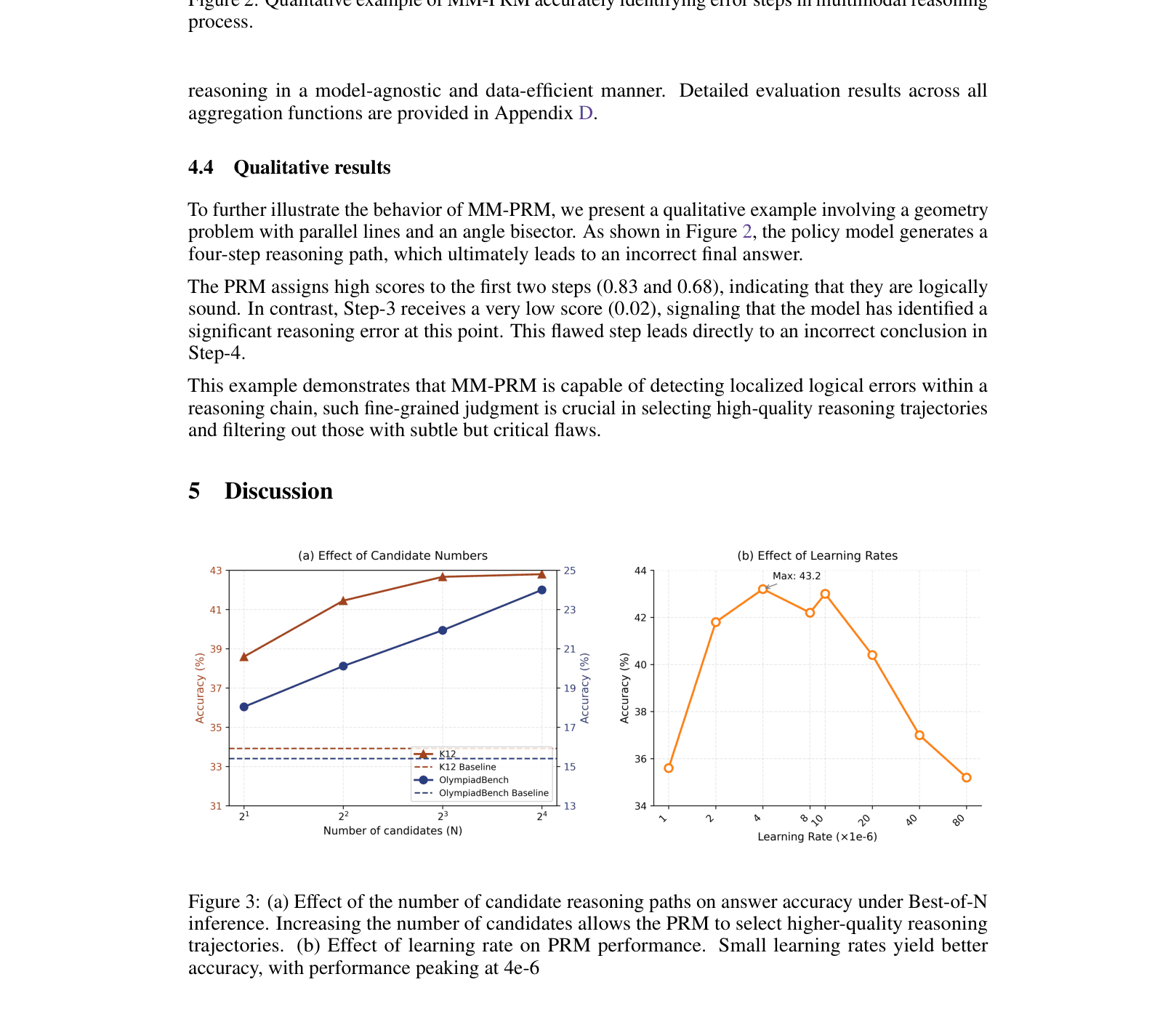
MM-PRM is an automated framework that generates scalable step-level supervision for multimodal math problems using Monte Carlo Tree Search, training a reward model to significantly improve reasoning accuracy.
Core Problem
Multimodal Large Language Models (MLLMs) struggle with complex multi-step mathematical reasoning, often producing logically inconsistent steps or false positives where incorrect reasoning leads to the correct answer.
Why it matters:
- Current Outcome Reward Models (ORMs) only evaluate final answers, failing to detect flawed intermediate logic or guide models through long reasoning chains
- Existing Process Reward Models (PRMs) rely on expensive manual annotation or inefficient sampling methods, making them hard to scale for multimodal tasks
- High false-positive rates in current models undermine interpretability and trustworthiness in educational and scientific applications
Concrete Example:
In a geometry problem (Figure 2), a policy model correctly identifies parallel lines but then uses an incorrect property (Angle Bisector Theorem incorrectly applied) in Step 3. An outcome-based model might miss this if the final number happened to be correct by chance, but MM-PRM assigns a low score (0.02) to that specific flawed step.
Key Novelty
Scalable Automated Process Supervision for Multimodal Math
- Constructs a high-quality seed dataset (MM-K12) of 10,000 verifiable multimodal math problems to initialize the supervision pipeline
- Adapts Monte Carlo Tree Search (MCTS) to multimodal contexts, efficiently exploring reasoning paths to generate over 700,000 step-level correctness labels without human annotation
- Trains a dense Process Reward Model (PRM) using soft labels derived from MCTS value estimates, preserving uncertainty better than hard binary labels
Architecture
The three-stage framework: Policy Construction, Data Generation (MCTS), and PRM Training
Evaluation Highlights
- +8.88% accuracy improvement on MM-K12 test set when applying MM-PRM to the base MM-Policy model
- +10.10% accuracy boost on OlympiadBench (OOD) when applied to InternVL2.5-8B, demonstrating strong generalization
- Outperforms hard-label training by ~6% (42.8% vs 37.0% on MM-K12) by using soft labels that capture step-wise uncertainty
Breakthrough Assessment
8/10
Significantly advances multimodal reasoning by solving the data bottleneck for process supervision. The automated MCTS pipeline enables scalable PRM training without human labels, showing strong generalization.