📝 Paper Summary
Image Stylization
Diffusion Model Sampling
Modifying the null-text noise input during classifier-free guidance sampling in diffusion models can spontaneously generate cartoon-style images without any model training.
Core Problem
Existing cartoonization methods typically require training separate GANs or fine-tuning diffusion models, which can be resource-intensive and lack flexibility.
Why it matters:
- Training dedicated models (like CartoonGAN) requires curated datasets and significant compute
- Current fine-tuned diffusion models (like Anything-v3) often fail to generalize to new concepts or lose spatial information from the original image
- Users need a lightweight, plug-and-play way to stylize images using existing powerful pre-trained models
Concrete Example:
When Anything-v3 attempts to cartoonize 'A Photo of Robert Downey Jr.', it may fail to retain his likeness or generate a generic anime face. Stable Diffusion v1.4 with the prompt 'cartoon style' often produces images that lack the original's spatial structure.
Key Novelty
Null-text Noise Disturbance (Back-D and Image-D)
- Discovers that the 'null-text' branch in Classifier-Free Guidance (typically used as a negative baseline) strongly influences style when its input noise is mismatched
- Introduces 'Rollback Disturbance' (Back-D): Feeding a noisier version of the current image into the null-text branch forces the model to steer away from 'noisy/chaotic' features, resulting in a smoothed, cartoon-like output
- Introduces 'Image Disturbance' (Image-D): Feeding the clean reference image into the null-text branch to preserve high-fidelity details while still inducing cartoonization
Architecture
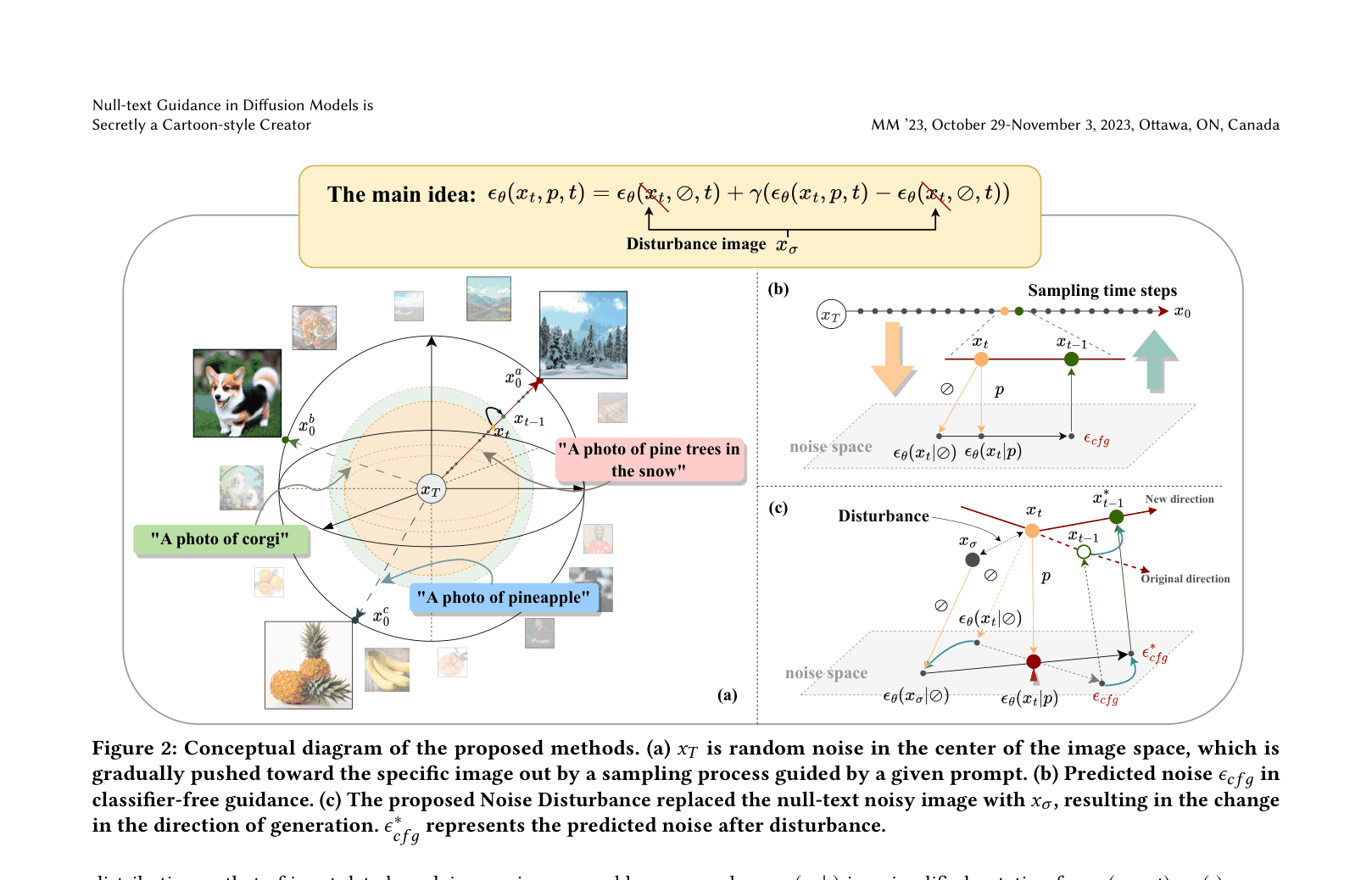
Conceptual diagram of the Noise Disturbance strategy compared to standard Classifier-Free Guidance
Evaluation Highlights
- Demonstrates successful cartoonization across diverse domains (portraits, animals, landscapes, architecture) without any training
- Achieves higher fidelity and more 3D-like vivid textures compared to the flat, blocky outputs of GAN-based methods like AnimeGANv3
- Validates effectiveness as a plug-and-play component by integrating with ControlNet for scribble-to-image cartoonization
Breakthrough Assessment
7/10
A clever, training-free empirical discovery that repurposes the mechanics of CFG for style transfer. While mathematically heuristic, it offers significant practical utility for style generation without fine-tuning.

