📝 Paper Summary
Multimodal Agents
Tool Use
Visual Reasoning
MM-REACT empowers ChatGPT to perform advanced visual tasks by prompting it to plan and invoke specialized vision models as external tools, treating images as file paths.
Core Problem
Specialized vision models lack reasoning capabilities, while powerful end-to-end multimodal models (like PaLM-E) are expensive to train and inflexible to upgrade.
Why it matters:
- Training monolithic multimodal models requires massive compute and annotated data
- Single-purpose vision models (e.g., face detection) cannot answer complex queries like 'How much tax did I pay?' from a receipt image
- Existing systems lack the flexibility to plug-and-play improved vision experts without retraining
Concrete Example:
When asked 'How much in total did I pay for taxes?' given multiple receipt images, a standard image captioner fails. MM-REACT invokes an OCR tool to read the text, then uses ChatGPT's math reasoning to sum the tax amounts ($323.23), which neither model could do alone.
Key Novelty
Synergistic Composition of ChatGPT and Vision Experts
- Represents visual inputs (images/videos) as file path strings (placeholders) that ChatGPT can pass as arguments to external tools
- Injects tool usage knowledge into ChatGPT via prompt engineering (instructions and in-context examples) rather than fine-tuning
- Standardizes vision tool outputs (e.g., bounding boxes, captions) into text formats that the LLM can process to generate final answers
Architecture
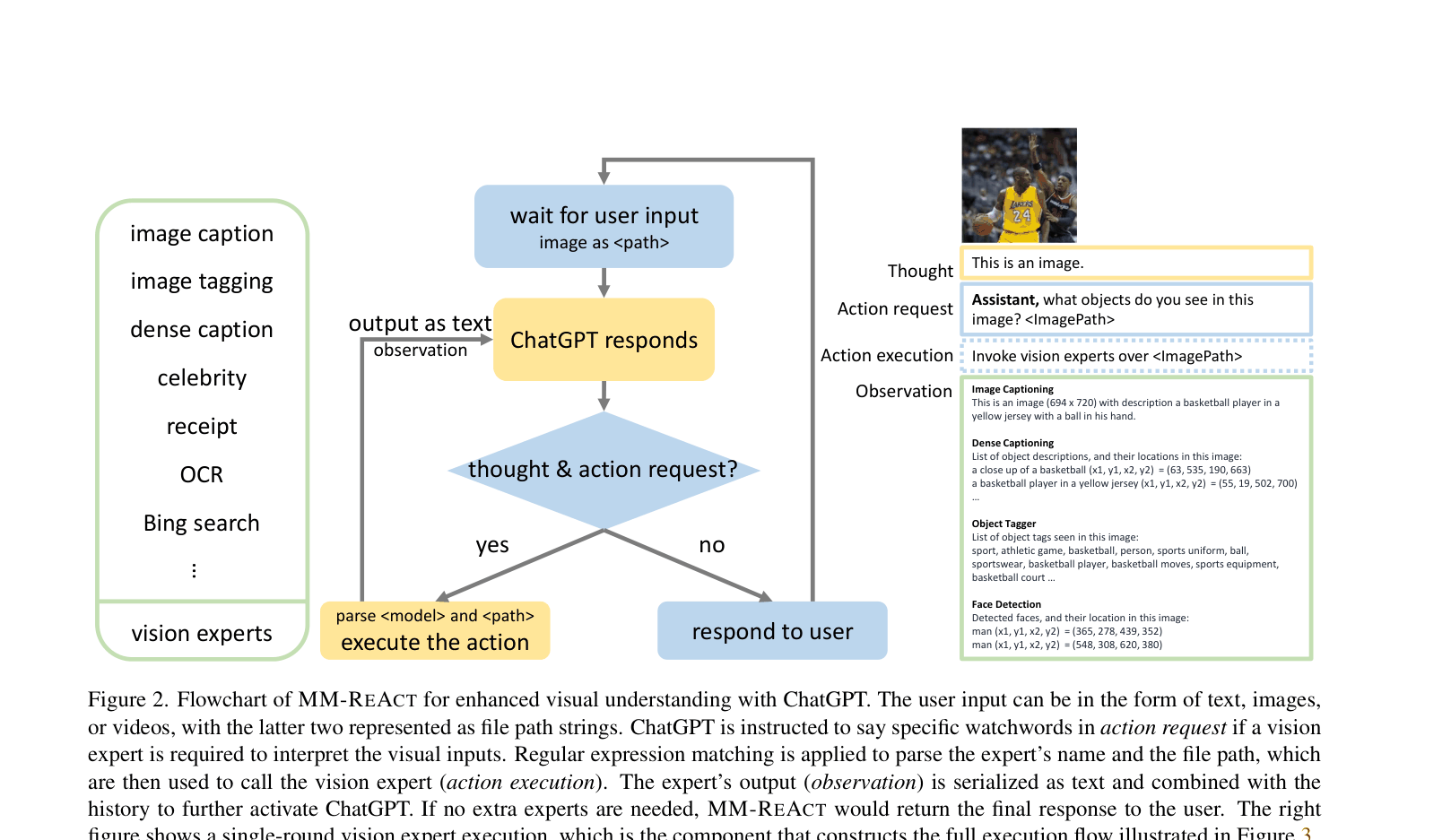
The flowchart of the MM-REACT system paradigm, illustrating the loop between ChatGPT and Vision Experts
Breakthrough Assessment
8/10
A pioneering framework for training-free multimodal agents. It established the paradigm of using LLMs as controllers for vision tools, influencing subsequent 'agentic' vision systems.