📝 Paper Summary
MultiModal Large Language Models (MM-LLMs)
Model Architecture Survey
This survey establishes a comprehensive taxonomy of 126 MM-LLMs and defines a general five-component architecture to organize and facilitate research in the rapidly expanding field of multimodal large language models.
Core Problem
The rapid expansion of MM-LLMs and datasets has made traditional MM models computationally expensive to train from scratch, while the field lacks a unified architectural framework to organize the heterogeneous approaches.
Why it matters:
- Training multimodal models from scratch incurs substantial computational costs
- Effectively connecting pre-trained LLMs with other modalities (audio, vision) remains a core challenge
- The lack of a unified taxonomy hinders researchers from tracking the timeline and specific formulations of the exploding number of new models
Concrete Example:
Traditional MM models require massive compute; MM-LLMs mitigate this by keeping the heavy LLM backbone frozen or using PEFT (Parameter-Efficient Fine-Tuning), training only lightweight projectors (taking up ~2% of parameters) to align modalities.
Key Novelty
Unified General Architecture & Taxonomy for MM-LLMs
- Proposes a general model architecture consisting of five components: Modality Encoder, Input Projector, LLM Backbone, Output Projector, and Modality Generator
- Establishes a taxonomy encompassing 126 State-of-the-Art MM-LLMs, categorizing them by their specific architectural formulations and capabilities (e.g., MM Understanding vs. MM Generation)
Architecture
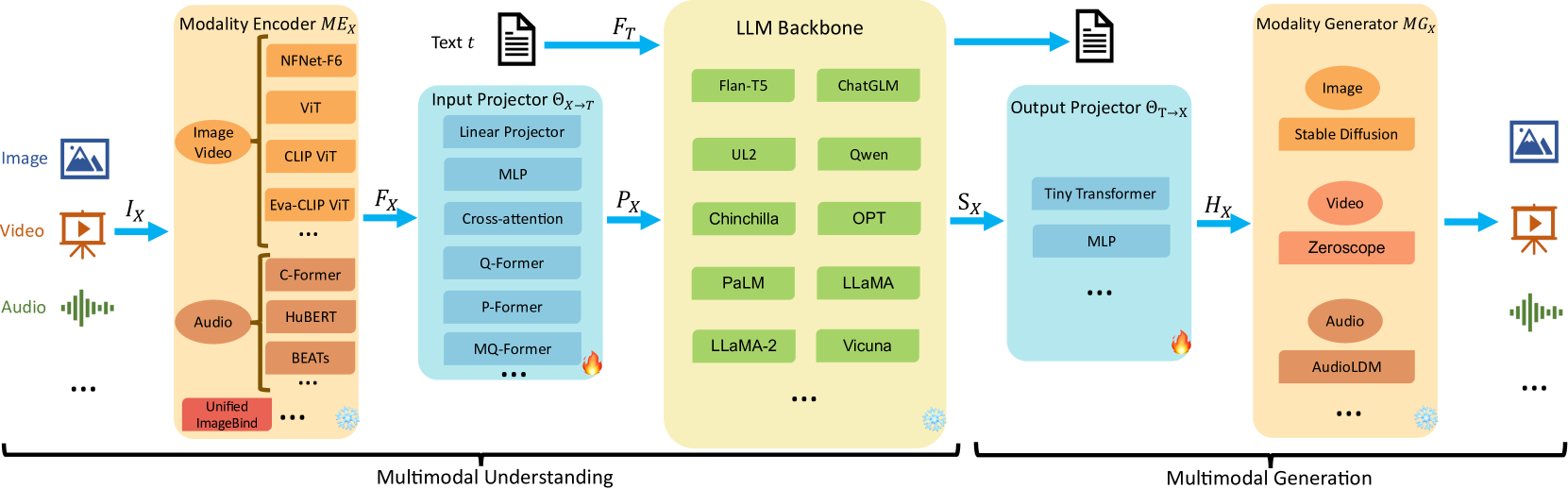
The general model architecture of MM-LLMs showing the five core components and the data flow between them.
Evaluation Highlights
- Taxonomy categorizes 126 distinct MM-LLMs (e.g., BLIP-2, LLaVA, GPT-4 Vision)
- Identifies a standard training pipeline consisting of MM Pre-Training (PT) for alignment and MM Instruction-Tuning (IT) for intent alignment
- Defines a modular architecture where trainable parameters are typically around 2% of the total count, enabling cost-effective training
Breakthrough Assessment
9/10
A highly necessary and comprehensive survey that organizes a chaotic field. The definition of the general 5-component architecture provides a standard language for future research.