📝 Paper Summary
Multimodal Agents
Web Browsing Agents
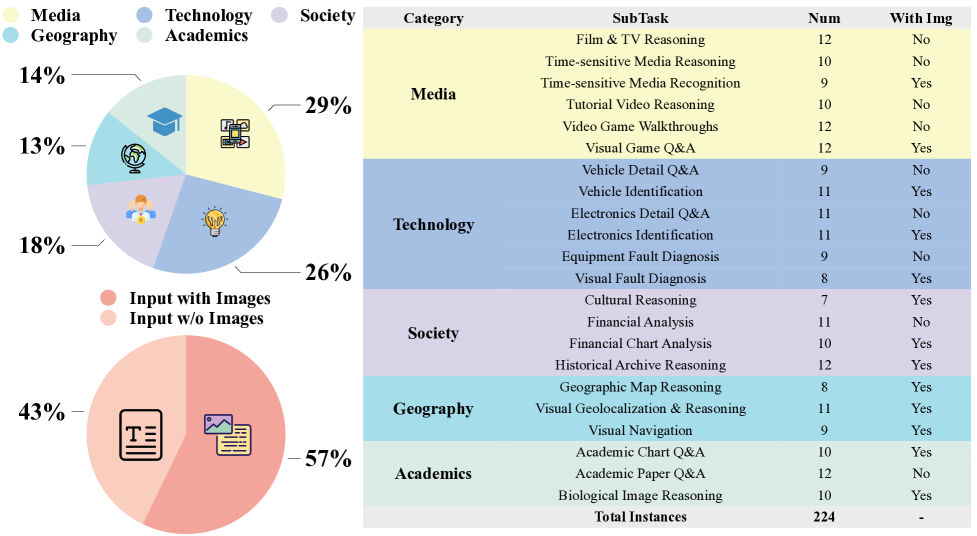
Benchmark Construction
MM-BrowseComp is a challenging benchmark for multimodal browsing agents that requires retrieving and reasoning over visual content on the web, revealing significant gaps in current state-of-the-art models.
Core Problem
Existing browsing benchmarks like BrowseComp focus primarily on text, overlooking the critical need for agents to retrieve and reason with multimodal content (images, videos) embedded in web pages.
Why it matters:
- A vast amount of internet knowledge is locked in images and videos, which text-only search agents cannot access
- Current benchmarks are nearing saturation on text tasks, failing to distinguish the reasoning capabilities of advanced agents in realistic multimodal scenarios
- Approaches relying on captioning tools for images suffer from significant information loss and hallucination compared to native multimodal reasoning
Concrete Example:
A user asks about the color of a specific object in a video clip. A text-only agent might find the video title but cannot watch it to answer. MM-BrowseComp requires the agent to find the video, process the visual frames, and identify the color, which cannot be solved by text search alone.
Key Novelty
Irreducible Multimodal Reasoning Checklist
- Introduces a verified checklist for every question that defines the minimal reasoning path required, distinguishing genuine reasoning from lucky guessing
- Enforces 'Mandatory Multimodal Dependency' where essential information is embedded primarily in visual modalities (images/videos) and not in text, preventing text-only shortcuts
- Constructs questions using an inverted methodology (fact-to-question) with rigorous filtering to ensure questions are unanswerable by GPT-4o/Gemini without tools
Architecture
Overview of the MM-BrowseComp benchmark concept, showing a user query with an image, the agent browsing web pages containing text and video, and the 'Irreducible Reasoning Checklist' used for evaluation.
Evaluation Highlights
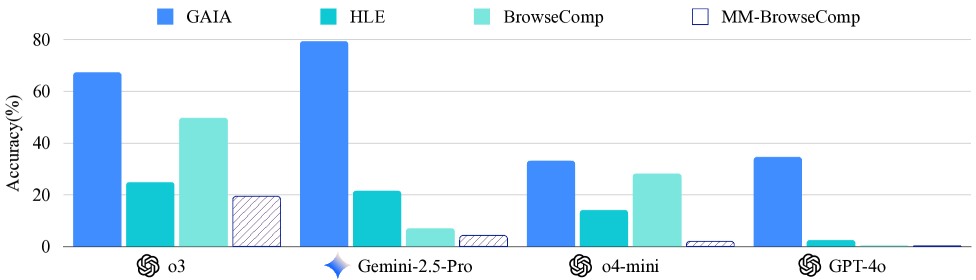
- OpenAI o3 with tools achieves only 29.02% accuracy, significantly outperforming other models but still showing ample room for improvement
- State-of-the-art open-source and closed-source VLMs (e.g., Gemini-2.5-Pro) fail to surpass 10% accuracy, highlighting extreme difficulty
- Native multimodal agents (o3) significantly outperform agents that rely on captioning tools, which suffer from information loss
Breakthrough Assessment
9/10
Addresses a critical gap in agent evaluation (multimodality in web browsing) with a rigorous construction process. The extremely low performance of current SOTA models (even o3 is <30%) establishes it as a definitive challenge for the next generation of agents.