📝 Paper Summary
Multimodal Evaluation Benchmark
Large Multimodal Models (LMMs)
MM-Vet is a benchmark that evaluates large multimodal models on complicated tasks by defining six core capabilities and examining their integration using an LLM-based evaluator for open-ended responses.
Core Problem
Existing vision-language benchmarks focus on isolated capabilities (like recognition or OCR) and simple tasks, failing to evaluate how Large Multimodal Models (LMMs) integrate multiple skills to solve complex, real-world problems.
Why it matters:
- Current benchmarks cannot assess the 'generalist' nature of LMMs which solve tasks requiring simultaneous reasoning, recognition, and spatial awareness.
- Rapid model advancements (like GPT-4V) require evaluation metrics that handle diverse, open-ended answer styles beyond simple multiple-choice or binary classification.
- Simple performance rankings hide model insights; developers need to know *which* specific capability integrations (e.g., OCR + Math) cause failure.
Concrete Example:
A question asks: 'What will the girl on the right write on the board?' To answer, a model must detect genders (Recognition), locate the girl (Spatial Awareness), read the text (OCR), and solve the equation (Math). Existing benchmarks test these separately, missing the integration failure points.
Key Novelty
Capability Integration Evaluation
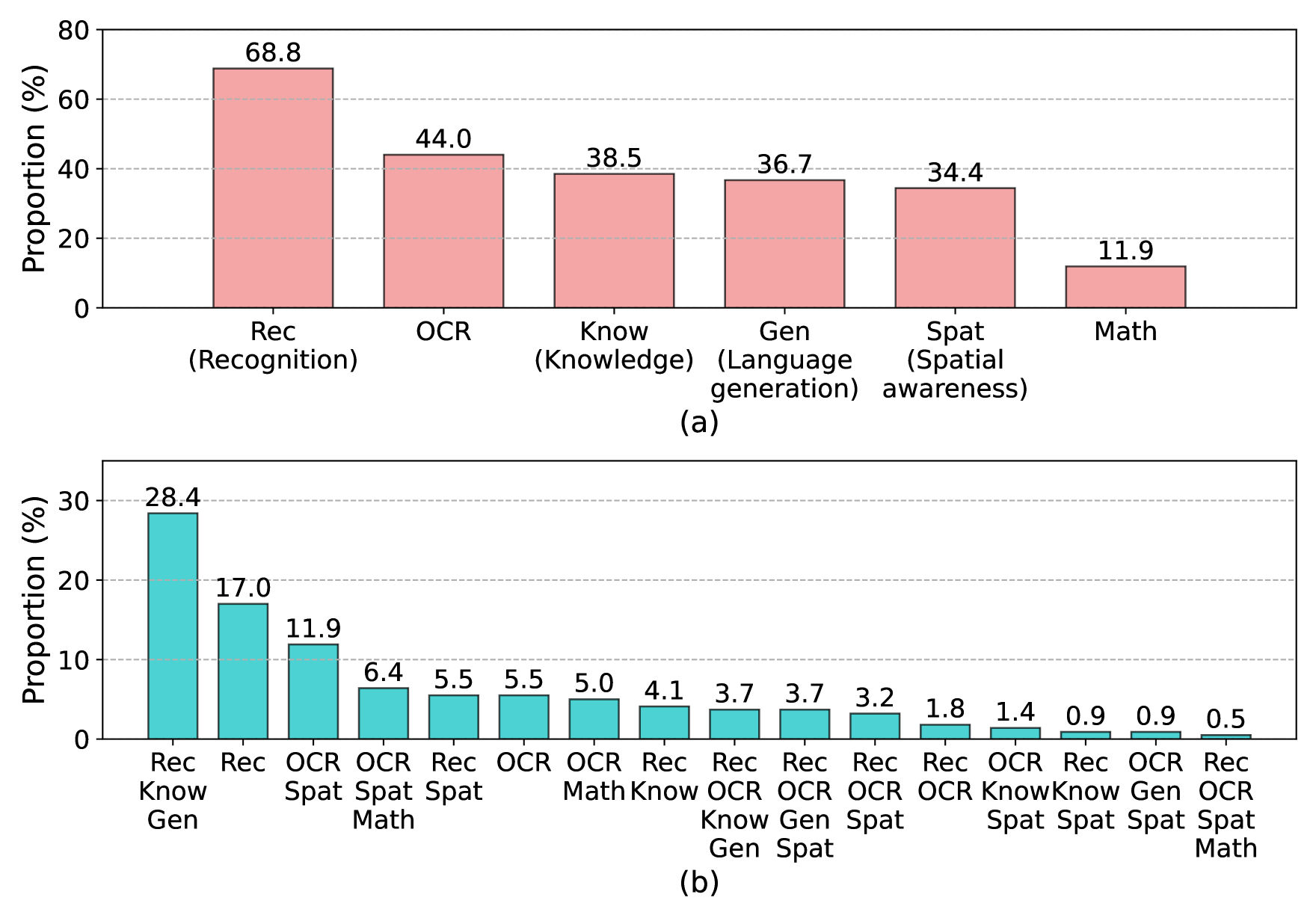
- Defines 6 core Vision-Language (VL) capabilities (Recognition, Knowledge, OCR, Spatial, Generation, Math) and explicitly evaluates the 16 different combinations (integrations) of these skills.
- Uses an LLM-based evaluator (GPT-4) with soft scoring (0.0 to 1.0) to handle open-ended outputs, unified across diverse question types and answer lengths.
Architecture

Contrast between existing benchmarks (isolated tasks) and MM-Vet (integrated capabilities).
Evaluation Highlights
- GPT-4V achieves the highest total score of 67.8%, significantly outperforming open-source alternatives like LLaVA-13B (LLaMA-2) at 36.3%.
- LLaVA-13B (LLaMA-2) outperforms LLaVA-13B (Vicuna-13B) by 8.3% on Recognition, suggesting stronger Language Models (LLMs) improve visual recognition.
- MM-ReAct (using GPT-4 + tools) achieves the best OCR performance (65.7%) among open-source/tool-using systems, surpassing end-to-end models like LLaVA-13B (22.7%).
Breakthrough Assessment
8/10
Significant contribution to LMM evaluation by shifting focus from isolated tasks to integrated capabilities. The LLM-based soft scoring for open-ended QA is a practical modernization of VL benchmarking.