📝 Paper Summary
Visual Instruction Tuning
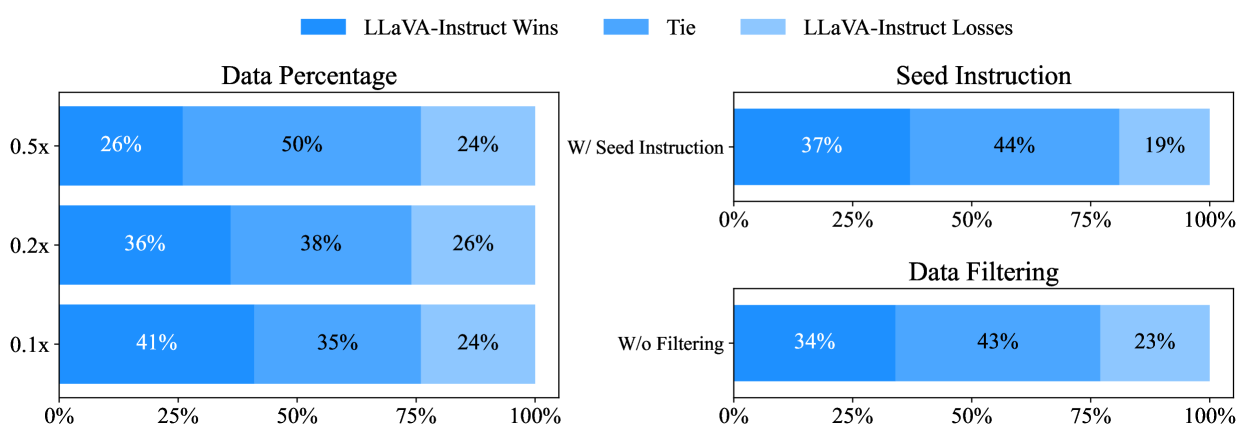
Synthetic Data Generation
MM-Instruct leverages LLMs to generate diverse visual instructions and coherent answers from image captioning datasets, significantly improving LMM performance on creative and complex tasks beyond standard QA.
Core Problem
Existing visual instruction datasets focus heavily on basic question-answering or captioning, causing Large Multimodal Models (LMMs) to fail at real-world tasks requiring creativity, summarization, or complex analysis.
Why it matters:
- Current models perform well on benchmarks but fail user requests in real scenarios (e.g., 'write a poem about this image' or 'summarize the event')
- Manually collecting diverse, high-quality instruction data is prohibitively expensive and hard to scale for academic groups
- Standard image captioning datasets lack the textual diversity needed to train robust instruction-following capabilities
Concrete Example:
When asked to 'Write a news report about the event in the image,' LLaVA-1.5 often fails to adopt the requested format or style, merely describing the image content factually. The proposed LLaVA-Instruct generates a structured news report with a headline and narrative style.
Key Novelty
LLM-driven augmentation of caption datasets into complex instructions
- Uses a text-only LLM (ChatGPT) to brainstorm diverse instructions based on detailed image descriptions, rather than relying on human annotation or simple templates
- Employs a retrieval-based pipeline where images are matched to these synthetic instructions via CLIP, ensuring visual relevance without needing paired data initially
- Generates answers using a strong LLM grounded by detailed textual descriptions of the image, ensuring the reasoning trace aligns with visual content
Architecture
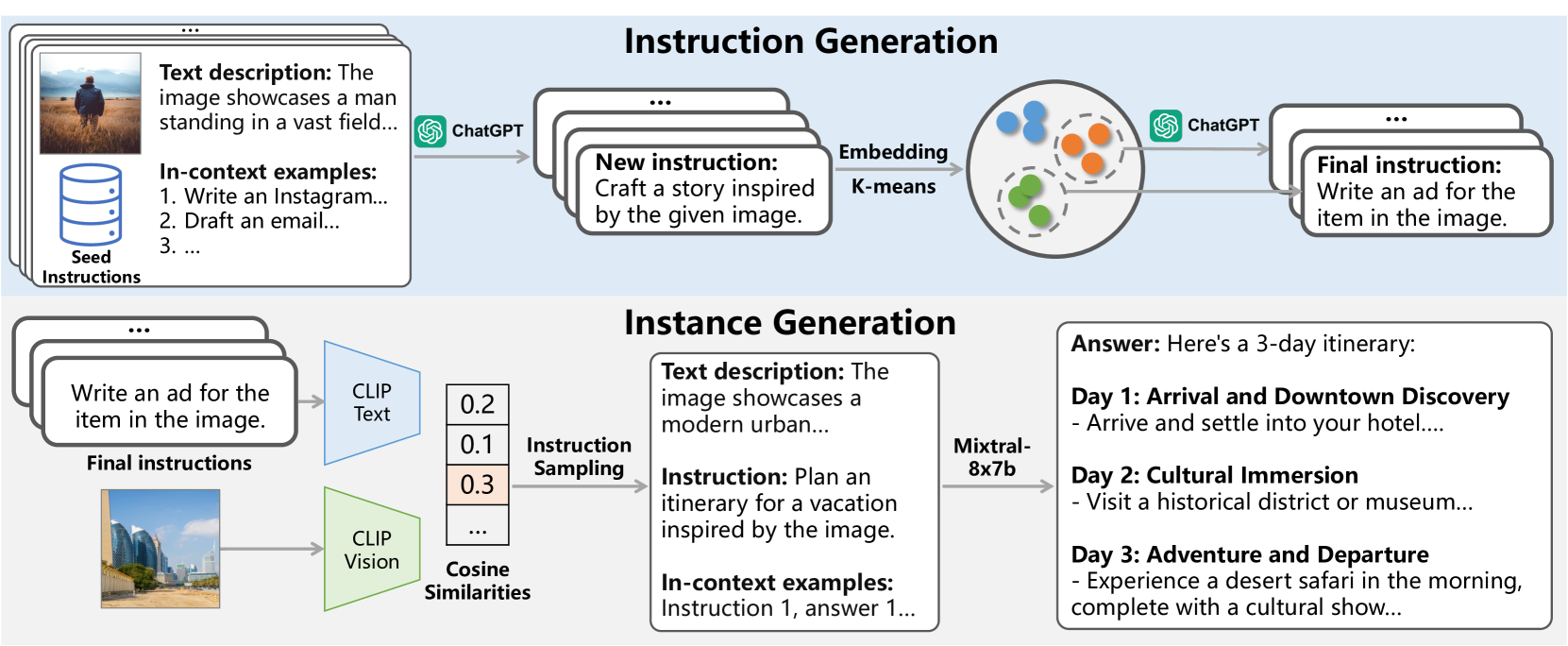
The automated pipeline for constructing the MM-Instruct dataset, divided into Instruction Generation (top) and Instance Generation (bottom).
Evaluation Highlights
- LLaVA-Instruct-13B outperforms LLaVA-1.5-13B significantly on VizWiz (+219.78 score) and MME (+101.46 score) benchmarks despite using generated data
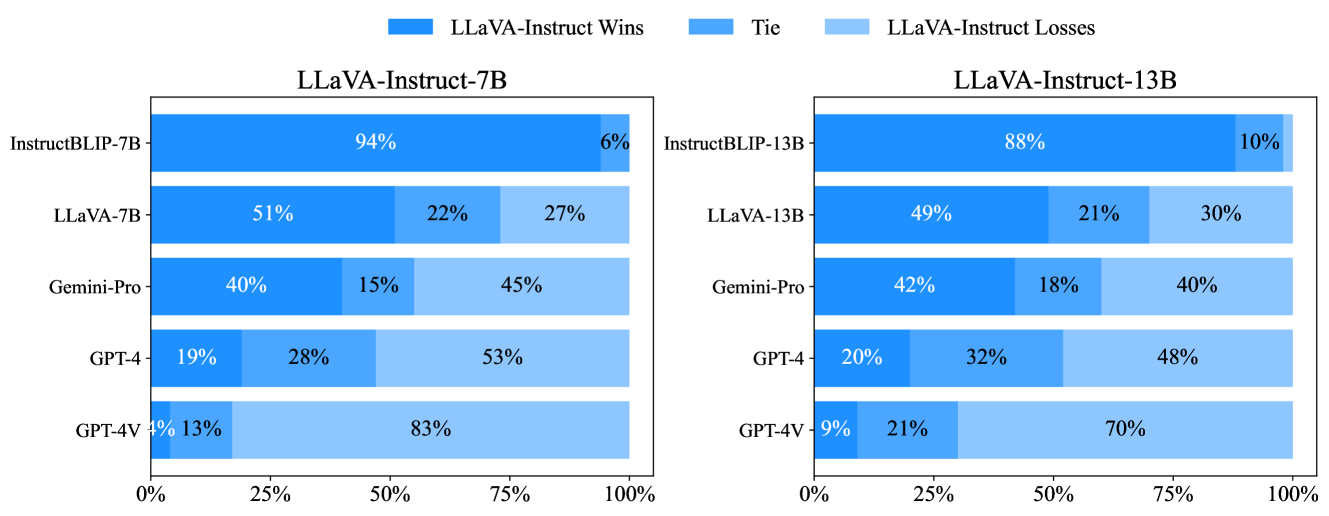
- According to GPT-4V judging, LLaVA-Instruct-7B produces equally or more preferable responses in 72% of cases compared to the base LLaVA-1.5-7B model
- Outperforms LLaVA-1.5 on 9 out of 12 evaluated vision-language benchmarks, showing that diverse instruction tuning improves general perception
Breakthrough Assessment
7/10
Strong pragmatic contribution demonstrating that synthetic instruction data from text-only LLMs can significantly boost LMM alignment and general performance, though the core architecture remains standard LLaVA.