📝 Paper Summary
Audio Description (AD) Generation
Long-form Video Understanding
Multimodal In-Context Learning
MM-Narrator is a training-free system that generates coherent audio descriptions for long videos by combining GPT-4 with a register-and-recall memory mechanism and a complexity-based strategy for selecting in-context examples.
Core Problem
Generating Audio Descriptions (AD) for long-form videos requires maintaining narrative consistency and tracking character identities over hours, which current short-clip methods and fine-tuned models fail to handle effectively.
Why it matters:
- Traditional human-annotated AD is costly and suffers from low inter-annotator agreement
- Existing automated methods often ignore subtitles for character naming and lack the long-term memory needed for story coherence
- AD serves as a testbed for evaluating Long Multimodal Models (LMM) on long-form reasoning capabilities beyond simple captioning
Concrete Example:
In a movie like 'Spider-Man', a model must infer 'Peter' and 'Spider-Man' are the same person based on past dialogue and context ADs to describe actions correctly later, which frame-by-frame captioning fails to do.
Key Novelty
Memory-Augmented Recurrent Generation with Complexity-Based ICL
- Utilizes a 'register-and-recall' visual memory bank to re-identify characters across long durations by matching current faces with past registered visual signatures
- Proposes 'complexity-based' demonstration selection: instead of finding similar examples, it selects the simplest examples (shortest chain-of-thought reasoning) to teach the model multimodal reasoning more effectively
Architecture
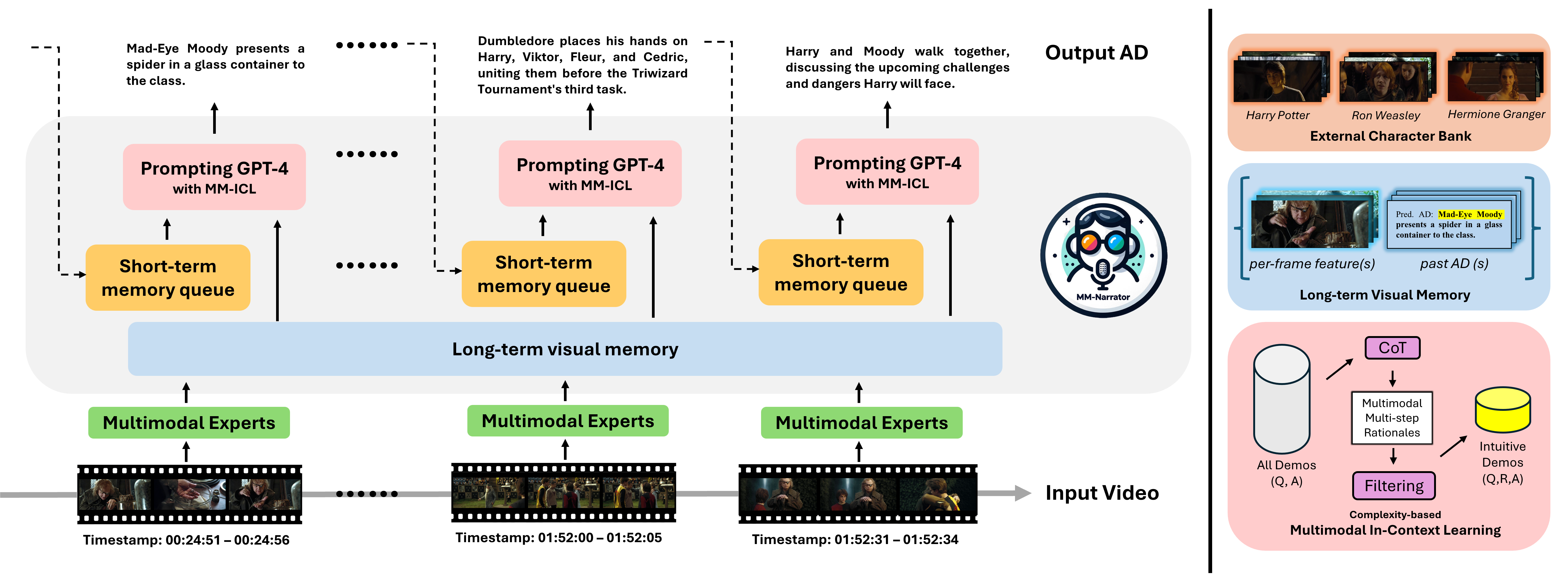
The overall inference pipeline of MM-Narrator processing a video clip.
Evaluation Highlights
- Consistently outperforms existing fine-tuning-based approaches on the MAD-eval dataset [quantitative values not in provided text]
- Surpasses LLM-based approaches, including GPT-4V, in standard captioning metrics [quantitative values not in provided text]
- Generates ADs comparable to human annotations across multiple dimensions as measured by a novel GPT-4 based segment evaluator
Breakthrough Assessment
7/10
Strong conceptual contribution in applying memory mechanisms to long-form video narrations and offering a counter-intuitive insight on ICL example selection (simple > similar).