📝 Paper Summary
Multi-modal Large Language Models (MLLMs)
Knowledge Distillation
CoMD is a bidirectional distillation framework that identifies difficult visual instructions where a student model fails and generates new, challenging training data to specifically target those weaknesses.
Core Problem
Standard instruction tuning for multi-modal models is resource-intensive (relying on GPT-4) and unidirectional, transferring knowledge from teacher to student without addressing specific student weaknesses.
Why it matters:
- Current distillation methods ignore feedback from the student model, failing to adapt training to where the student actually struggles
- Constructing high-quality multi-modal instruction datasets manually or via closed-source models (GPT-4) is expensive and labor-intensive
- Student models often learn easy concepts (e.g., day vs. night) but fail at hard reasoning (e.g., specific character identification) if the teacher doesn't specifically target those gaps
Concrete Example:
A student model correctly identifies a scene is at 'night' (easy) but fails to identify a snowman as 'Olaf' from Frozen (hard). Standard distillation doesn't prioritize the failed 'Olaf' query, leaving the student weak in specific entity recognition.
Key Novelty
Competitive Multi-modal Distillation (CoMD)
- Establishes a bidirectional loop where an 'Assessor' compares Teacher and Student answers to identify 'difficult' instructions where the Student underperforms
- Uses an 'Augmentor' to generate new, challenging instructions based on the identified difficult examples, creating a curriculum that evolves with the student's capability
- Iteratively updates the training dataset with these targeted hard examples, allowing a smaller student (7B) to eventually surpass the larger teacher (13B)
Architecture
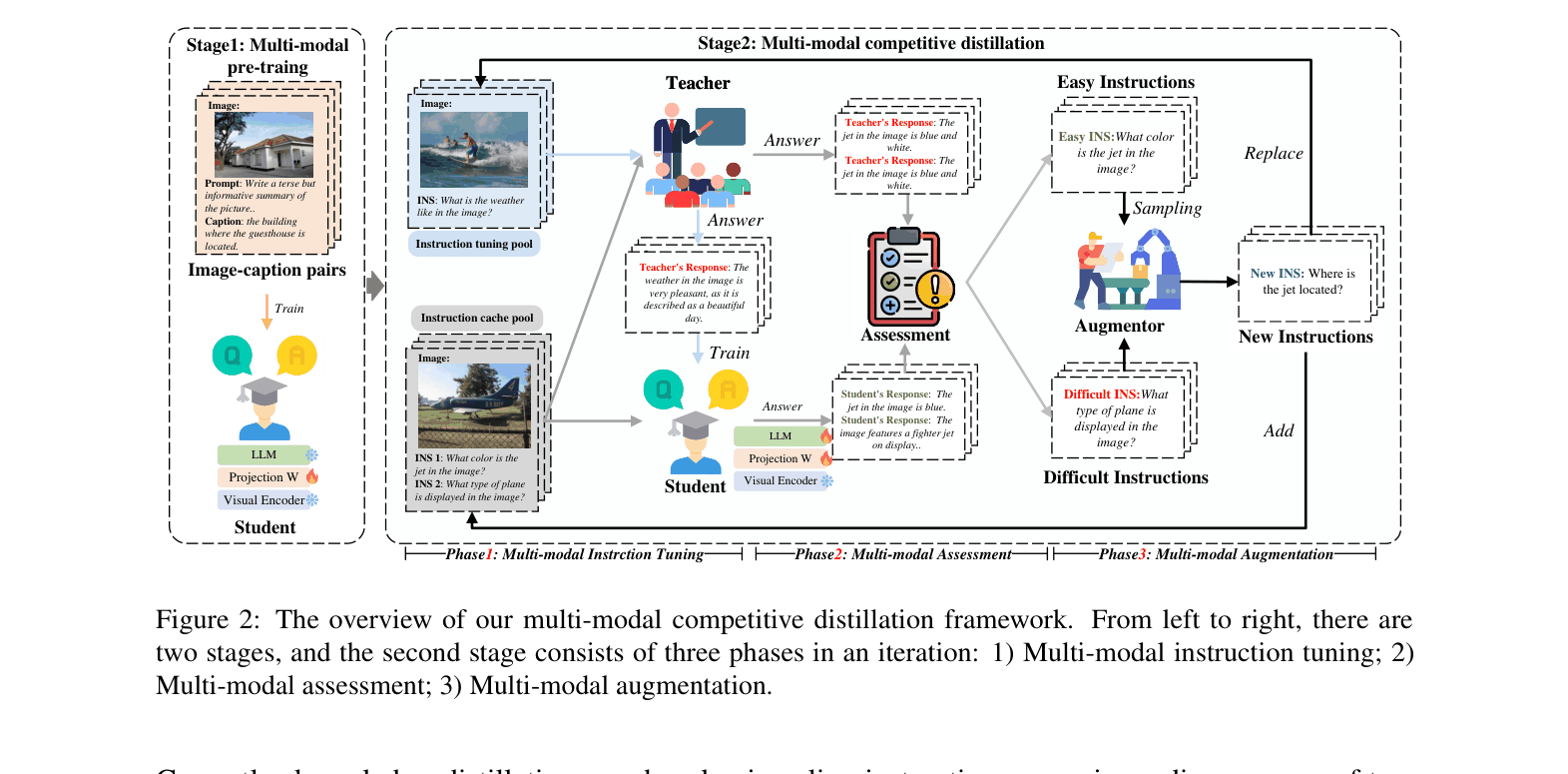
Overview of the Competitive Multi-modal Distillation framework, showing the two stages (Pre-training and Distillation) and the three phases within the distillation loop (Instruction Tuning, Assessment, Augmentation).
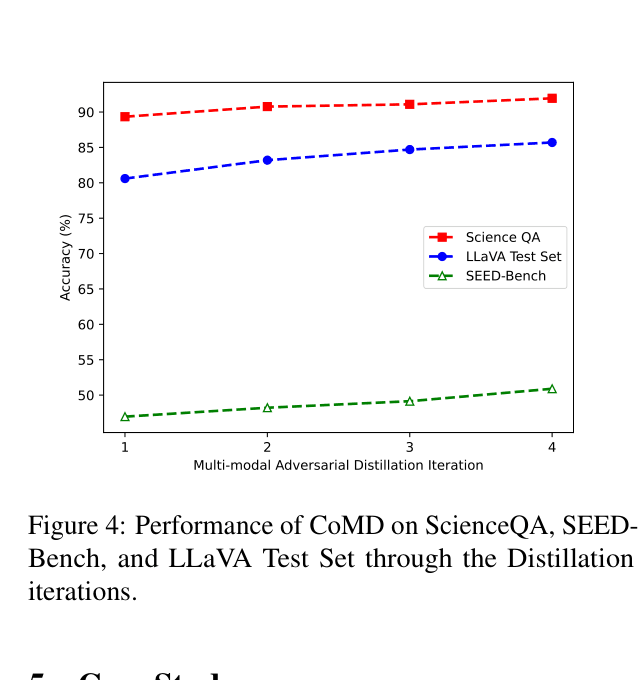
Evaluation Highlights
- 7B Student model surpasses its own Teacher (LLaVA-13B) by +1.47% accuracy on ScienceQA
- Achieves 91.83% on ScienceQA, outperforming the previous SOTA (MM-CoT Large) by +0.15% with significantly fewer parameters
- Outperforms LLaVA-13B by +2.47% on SEED-Bench (Image) among comparable 7B models (though trailing InstructBLIP)
Breakthrough Assessment
7/10
Novel bidirectional feedback mechanism for distillation allows a smaller model to beat a larger teacher. Strong results on ScienceQA, though relies on existing LLaVA architecture.