📝 Paper Summary
Supervised Multi-modal Learning
Probabilistic Graphical Models
Model Ensembling / Fusion
I2M2 improves multi-modal learning by decomposing predictions into separate uni-modal and joint classifiers, ensuring the model captures both individual modality signals and cross-modality interactions.
Core Problem
Existing multi-modal methods typically focus on either fusing modalities (inter-dependency) or processing them independently (intra-dependency), often failing when the dataset's dominant signal type doesn't match the model's assumption.
Why it matters:
- Multi-modal models sometimes paradoxically underperform simple uni-modal baselines when cross-modality interactions are weak or noisy.
- Prior approaches lack a principled framework to explain performance discrepancies across different dataset types (e.g., healthcare vs. vision-language).
- Real-world tasks vary unpredictably in their reliance on single-modality evidence versus complex cross-modal reasoning.
Concrete Example:
In 'Tiger Detection', seeing a tiger shape (intra-modality) is sufficient for prediction regardless of texture, requiring strong intra-modality modeling. Conversely, in NLVR2, an image and text must be compared (inter-modality) to verify truthfulness. Models focusing on only one dependency type fail on the other task.
Key Novelty
Inter- & Intra-Modality Modeling (I2M2)
- Views multi-modal data generation as a process where a label generates both individual modalities (intra) and a selection variable that governs their interaction (inter).
- Decomposes the prediction into three explicit components: a classifier for Modality A, a classifier for Modality B, and a joint classifier for the (A, B) pair.
- Combines these components via a Product of Experts (summing logits), allowing the system to dynamically leverage whichever dependency type is strongest for the specific datapoint.
Architecture
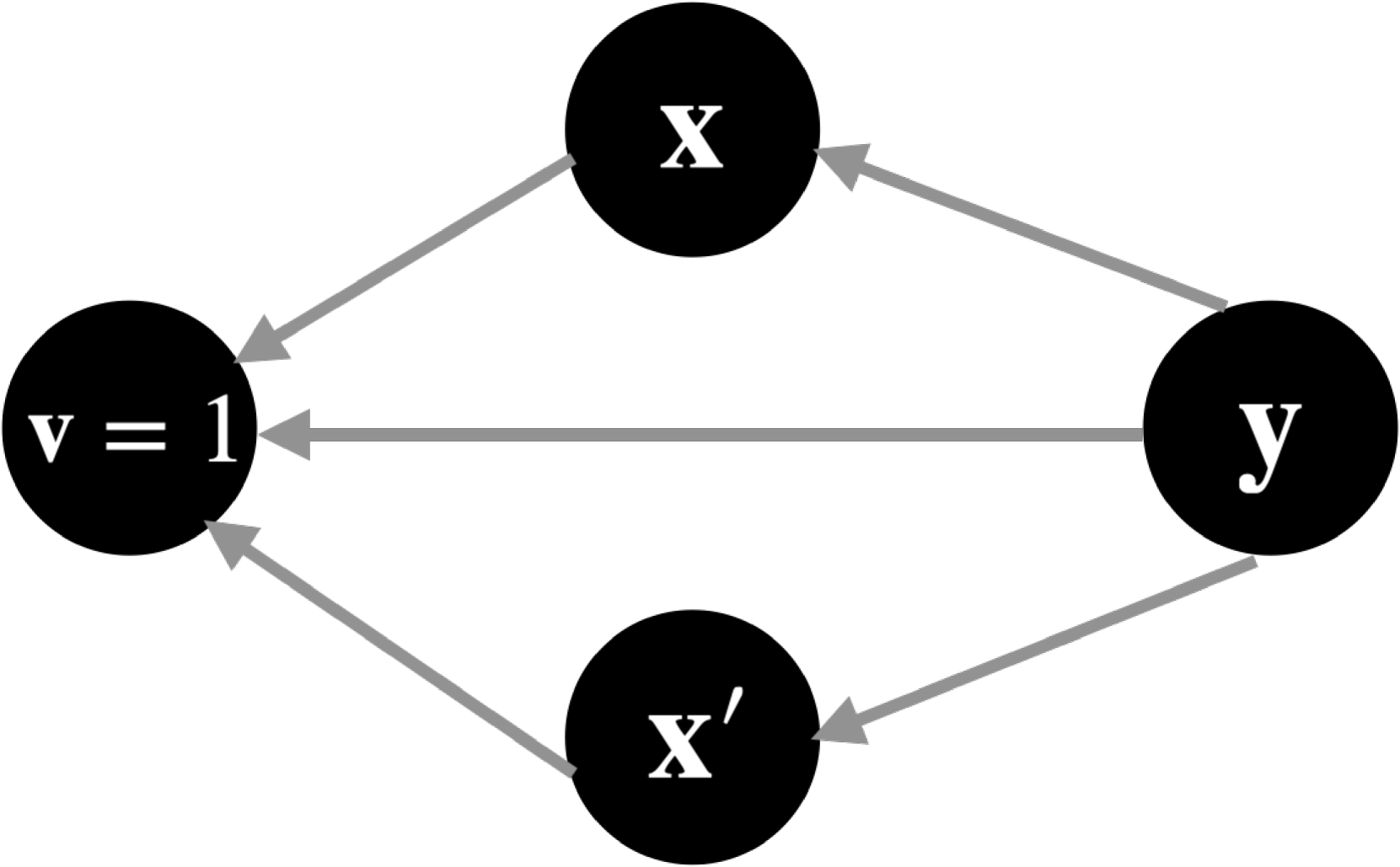
A comparison of generative processes (graphical models) for multi-modal learning: (a) The proposed joint model with selection variable v, (b) Inter-modality only model, and (c) Intra-modality only model.
Breakthrough Assessment
7/10
Provides a theoretically grounded explanation for common multi-modal failure modes and a robust, unified framework (I2M2) to address them. The approach is architectural-agnostic and principled.