📝 Paper Summary
Multi-modal representation learning
Contrastive Learning
Turbo enhances multi-modal classification by generating multiple representations of the same input via dropout and enforcing both in-modal and cross-modal contrastive alignment.
Core Problem
Existing multi-modal contrastive methods focus solely on aligning different modalities (cross-modal), neglecting the internal structure of single modalities (in-modal) and requiring large-scale pre-training data.
Why it matters:
- Ignoring in-modal contrastive learning limits the richness of individual modal representations, as proven by uni-modal successes like SimCSE.
- Standard multi-modal pre-training requires massive paired datasets, which are difficult to collect and clean for specific domains.
- Current methods often lack generalization when applied directly to smaller supervised tasks without extensive pre-training.
Concrete Example:
In speech emotion recognition, a model might align 'angry tone' with 'angry text' but fail to cluster different 'angry tone' samples tightly together in the audio space, leading to weaker overall classification boundaries.
Key Novelty
Turbo (Joint In-modal and Cross-modal Contrastive Learning)
- Uses dropout masks to generate two slightly different representations for the same input (audio and text) within a single training batch.
- Simultaneously minimizes in-modal contrastive loss (pulling same-modality views together) and cross-modal contrastive loss (pulling audio-text pairs together).
- Integrates this self-supervised contrastive objective directly into the supervised fine-tuning stage as an auxiliary task.
Architecture
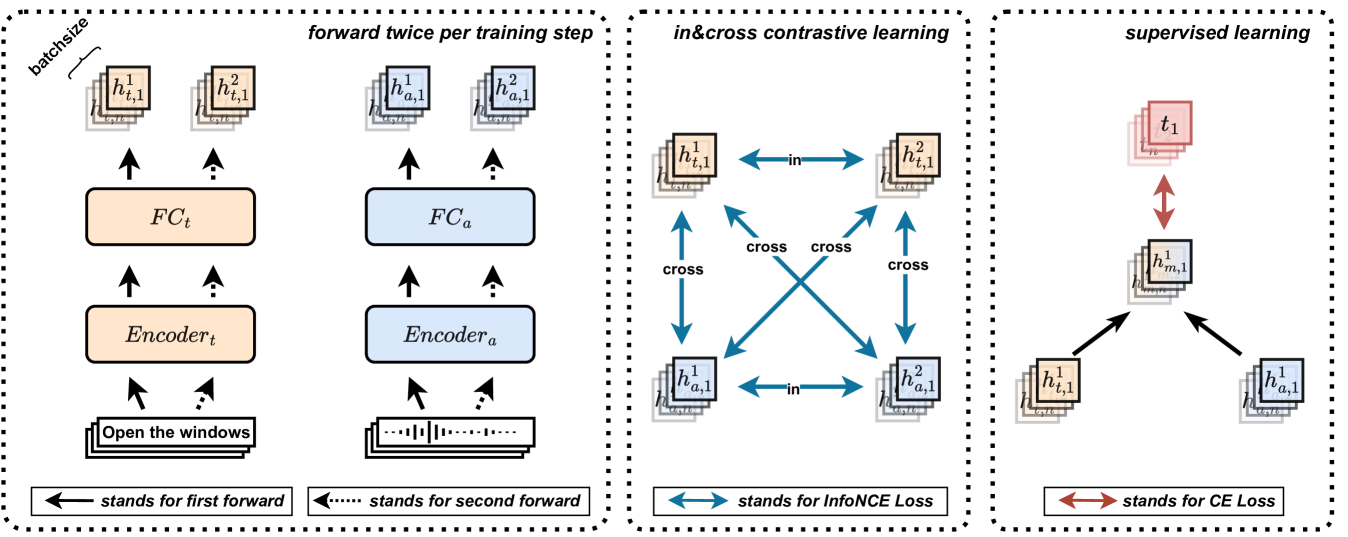
The Turbo framework training pipeline. It illustrates the dual forward pass mechanism where audio and text pass through encoders with dropout to create two views.
Evaluation Highlights
- +5.59% accuracy improvement on the IEMOCAP speech emotion recognition benchmark compared to the baseline.
- +3.83% accuracy improvement on the internal REJ device-directed speech detection task compared to the baseline.
- Achieves state-of-the-art performance on the IEMOCAP benchmark.
Breakthrough Assessment
7/10
Simple yet effective application of SimCSE-style dropout augmentation to multi-modal learning. Strong empirical gains on standard benchmarks, though the core mechanics are a combination of existing techniques.