📝 Paper Summary
Contrastive Learning
Theoretical Deep Learning
Feature Learning
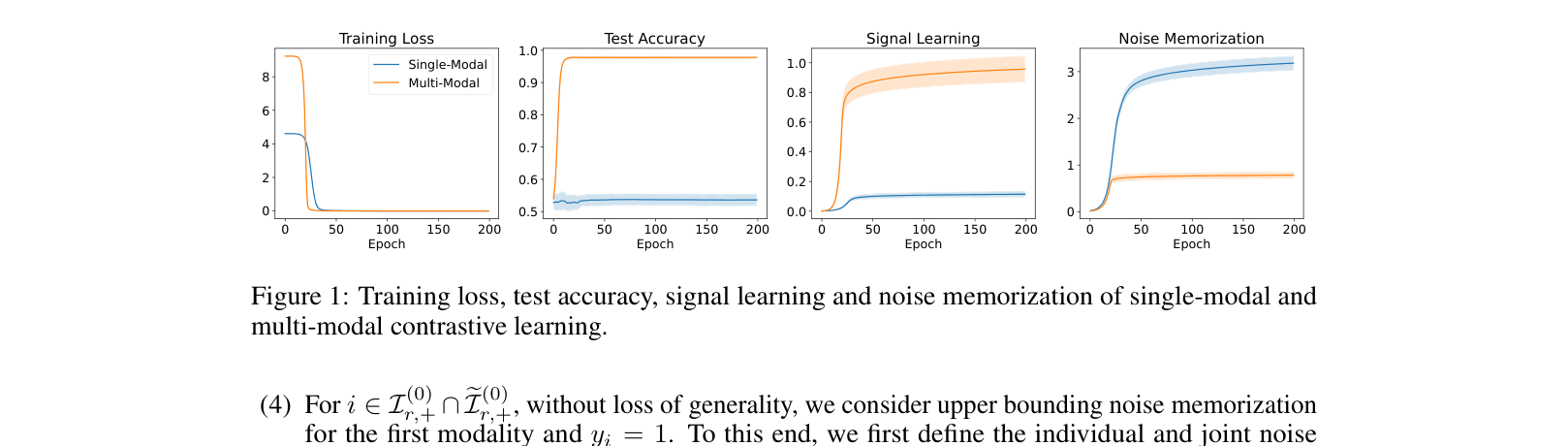
Multi-modal contrastive learning generalizes better than single-modal learning because high-quality signals in one modality help suppress noise memorization in the other through cooperative feature learning.
Core Problem
While multi-modal models like CLIP achieve superior robustness and transferability compared to single-modal baselines, the theoretical mechanism explaining this performance gap—specifically regarding optimization dynamics and feature learning—remains unexplained.
Why it matters:
- Foundation models (FMs) like CLIP rely on multi-modal pre-training, but we lack a theoretical understanding of why adding modalities improves generalization
- Existing theory focuses on single-modal or linear settings, failing to explain the interplay between signal learning and noise memorization in deep non-linear networks
- Understanding this mechanism is crucial for designing better pre-training objectives and data selection strategies for large-scale models
Concrete Example:
In single-modal learning with image augmentation, the augmentation often preserves the same noise level as the original image. Consequently, the model memorizes these noise features (spurious correlations) to minimize contrastive loss. In multi-modal learning (e.g., image-text), the text modality (signal) is uncorrelated with the image noise, allowing the model to filter out image noise and focus on the shared semantic signal.
Key Novelty
Signal-Noise Cooperation Theory for Contrastive Learning
- Models the training process as a competition between learning shared semantic signals (signal learning) and memorizing random data patterns (noise memorization)
- Demonstrates that in multi-modal learning, a high-quality second modality acts as a guide, accelerating signal learning in the first modality while suppressing noise
- Proves that single-modal learning is fundamentally limited by the signal-to-noise ratio (SNR) of augmentations, leading to unavoidable noise memorization
Architecture
Though no explicit block diagram is provided, the paper describes a dual-encoder architecture where gradients from the contrastive loss update both encoders simultaneously, allowing signal information to flow between modalities.
Evaluation Highlights
- Theoretical proof: Multi-modal contrastive learning achieves vanishing downstream test error (o(1)), while single-modal learning suffers constant error (Theta(1))
- Synthetic experiments: Multi-modal learning achieves near 1.0 test accuracy on OOD tasks, while single-modal stagnates near 0.5
- +69.45% accuracy gain on ColoredMNIST (82.13% vs 12.68%) by using multi-modal supervision to ignore spurious color correlations
Breakthrough Assessment
8/10
Provides the first unified theoretical framework analyzing optimization and generalization for both single- and multi-modal contrastive learning in non-linear networks, rigorously explaining the empirical success of CLIP-like models.