📝 Paper Summary
Spatial Understanding
Multi-Frame Reasoning
Robotics Perception
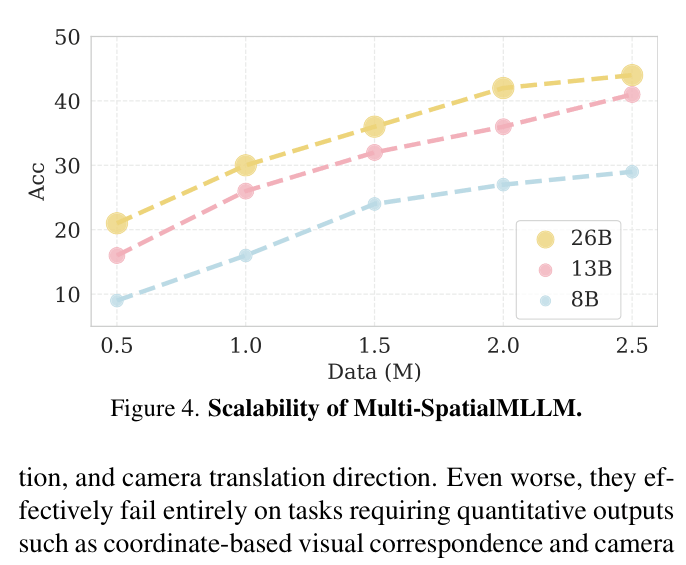
Multi-SpatialMLLM equips multi-modal models with multi-frame spatial reasoning capabilities by fine-tuning on a new 27-million-sample dataset (MultiSPA) automatically generated from 3D/4D scene scans.
Core Problem
Current MLLMs are trained primarily on single images and lack the spatial understanding required for robotics, failing to reason about depth, camera movement, or visual correspondence across multiple frames.
Why it matters:
- Robotics and autonomous vehicles require understanding 3D space and motion from 2D video frames, not just static semantic description
- Existing datasets rely on expensive manual annotation or noisy monocular estimators, limiting scale and quality
- SOTA models (like GPT-4o) often hallucinate movement or confuse camera motion with object motion
Concrete Example:
In a robotics scene where a camera moves around a static blue cube, GPT-4o incorrectly claims the cube moved 0.4 meters. Multi-SpatialMLLM correctly identifies that the cube is static and only the camera moved.
Key Novelty
MultiSPA Data Engine & Dataset
- Leverages existing 3D (ScanNet) and 4D (TAPVid3D) datasets to automatically generate high-quality QA pairs without human annotation
- Projects 3D point clouds into 2D image pairs to create ground-truth labels for depth, correspondence, and displacement vectors
- Defines a comprehensive set of 5 spatial tasks (e.g., depth perception, visual correspondence) with diverse output formats (coordinates, vectors, scalars)
Architecture

Overview of Multi-SpatialMLLM capabilities and input/output formats. Shows the model accepting multiple image frames and diverse referencing (coordinates, dots) to produce outputs like vectors and scalars.
Evaluation Highlights
- Achieves 56.11% average accuracy on the MultiSPA benchmark, outperforming GPT-4o (28.87%) and Gemini-2.0 (30.31%)
- Attains 18.00% accuracy on challenging camera movement vector prediction where baselines (GPT-4o, InternVL) achieve near 0% due to task difficulty
- Demonstrates strong zero-shot generalization on the external BLINK benchmark, improving Visual Correspondence accuracy from 39.0% (base model) to 89.5%
Breakthrough Assessment
8/10
Significant contribution in data engineering (27M samples) that unlocks a new capability (multi-frame spatial reasoning) in MLLMs, addressing a major gap for embodied AI.