📝 Paper Summary
3D Vision-Language Datasets
3D Visual Grounding
3D Question Answering
3D Large Language Models (3D-LLMs)
MMScan is a large-scale multi-modal 3D scene dataset constructed via a top-down, human-in-the-loop pipeline to provide hierarchical language annotations for training and benchmarking 3D perception models.
Core Problem
Existing 3D multi-modal datasets are limited to object-level understanding or specific tasks, lacking hierarchical scene structures (regions, inter-object relations) and scalable, high-quality annotations.
Why it matters:
- Current 3D-LLMs are constrained to object-level tasks and struggle with holistic scene understanding due to data limitations.
- Rule-based or purely manual annotations in prior works are either limited in scope (spatial relations only) or biased/unscalable.
- Purely VLM-generated annotations often lack correctness and fine-grained grounding, leading to suboptimal training for embodied agents.
Concrete Example:
A 3D-LLM trained on existing datasets might identify a 'chair' but fail to answer 'Which chair in the living room is nearest to the dining table?' because it lacks hierarchical region-level context and inter-target relationship data.
Key Novelty
Top-Down Hierarchical 3D-Language Annotation Pipeline
- Decomposes 3D scenes from global regions down to individual objects, capturing spatial and attribute information at multiple granularities.
- Uses a hybrid annotation workflow where VLMs (like GPT-4 and CogVLM) initialize captions based on optimal 2D views, which are then rigorously corrected by humans.
- Retains explicit correspondence between text phrases and 3D entities (objects/regions), enabling the generation of diverse benchmark samples (QA, Grounding) from a single set of meta-annotations.
Architecture
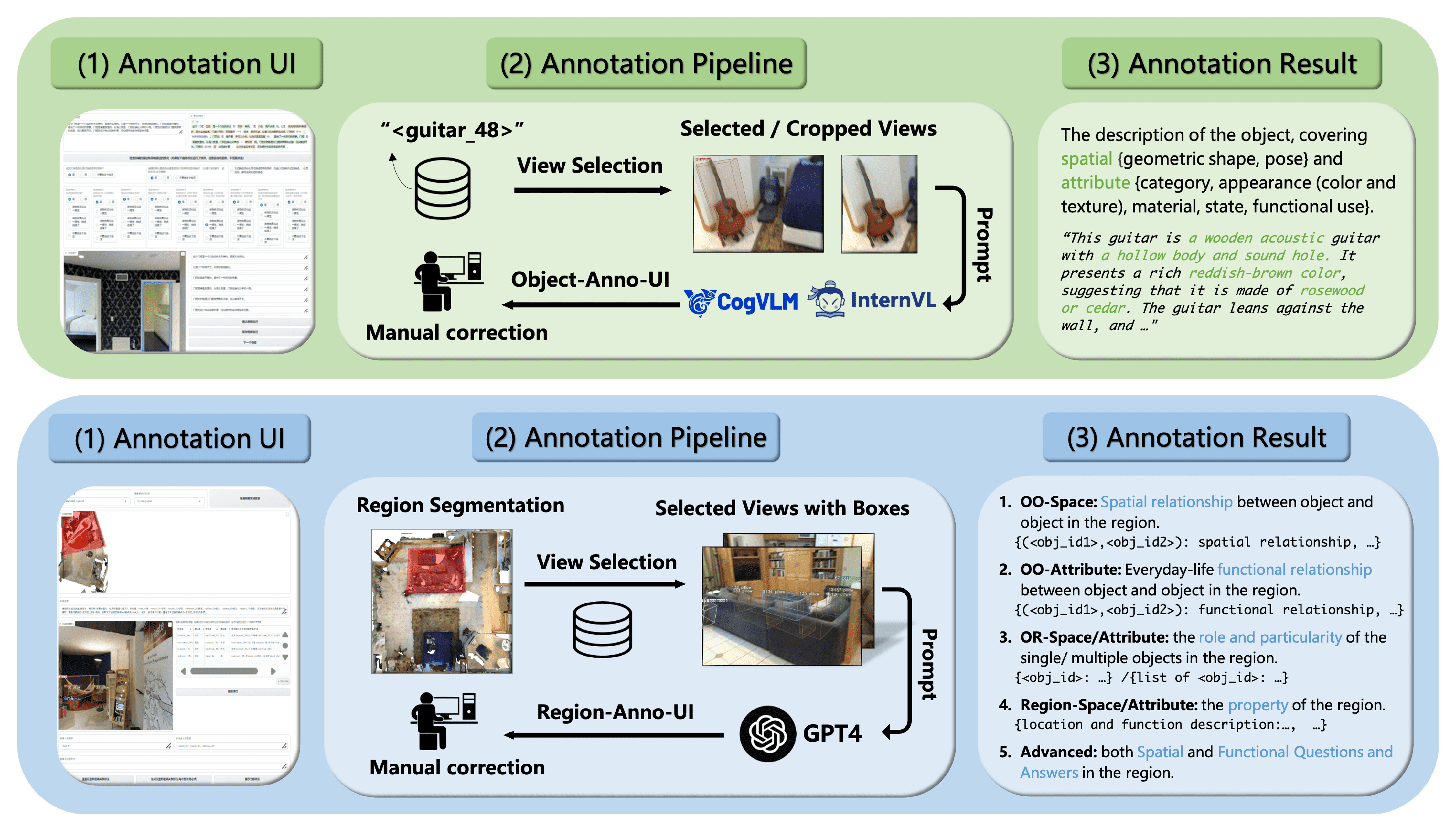
The human-in-the-loop annotation pipeline. It shows the process from data selection to VLM initialization (using specific prompts and views) and finally human correction using a custom UI.
Evaluation Highlights
- Fine-tuning LLaVA-Next-Vicuna-7B on MMScan captions achieves state-of-the-art 64.6% Accuracy on ScanQA (val), surpassing the previous best of 57.6%.
- Training on MMScan improves 3D visual grounding performance by +7.17% AP on the ScanRefer benchmark compared to baselines.
- Instruction tuning with MMScan data yields up to +25.6% accuracy improvement on the proposed MMScan-QA benchmark compared to base 3D-LLMs.
Breakthrough Assessment
9/10
Significantly scales up 3D-language data with a novel hierarchical approach. The massive improvement in downstream tasks (up to +25% in QA) and the release of a comprehensive benchmark make it a foundational resource.