📝 Paper Summary
Language Model Training Strategies
Curriculum Learning
Data Mixture Optimization
Midtraining acts as a distributional bridge that improves initialization for posttraining, specifically benefiting domains distant from pretraining data (like code and math) while mitigating catastrophic forgetting.
Core Problem
Standard fine-tuning on specialized data often causes abrupt distribution shifts, leading to gradient conflicts and catastrophic forgetting of general capabilities.
Why it matters:
- Widely adopted heuristic in large-scale model training (e.g., Llama 3, OLMo) lacks theoretical or empirical understanding of why it works
- Direct fine-tuning on narrow domains can degrade general reasoning capabilities
- Timing and mixture composition of intermediate training phases are currently determined by intuition rather than systematic study
Concrete Example:
Directly fine-tuning a general web-pretrained model on Python code (CodeSearchNet) causes a sharp increase in loss on general text (C4) due to the abrupt distribution shift. Midtraining on a mix of code and general text smooths this transition, preserving general capabilities while improving code performance.
Key Novelty
Midtraining as Distributional Bridging
- Proposes that midtraining works by moving the model parameters to a geometric region that is 'closer' to the target task, reducing the work required during fine-tuning
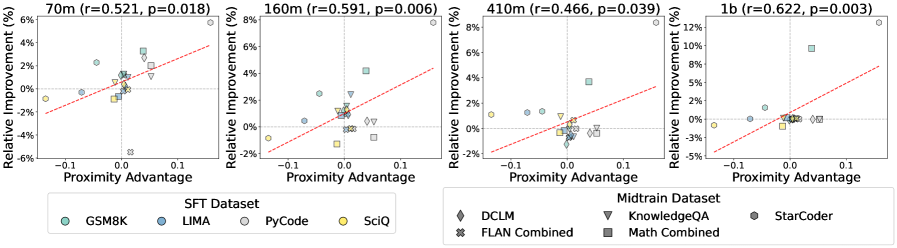
- Identifies 'Proximity Advantage'—how much closer the midtraining data is to the target than general pretraining data—as the key predictor of success
- Framed as a coarse-grained curriculum that orders data distributions rather than individual examples
Architecture
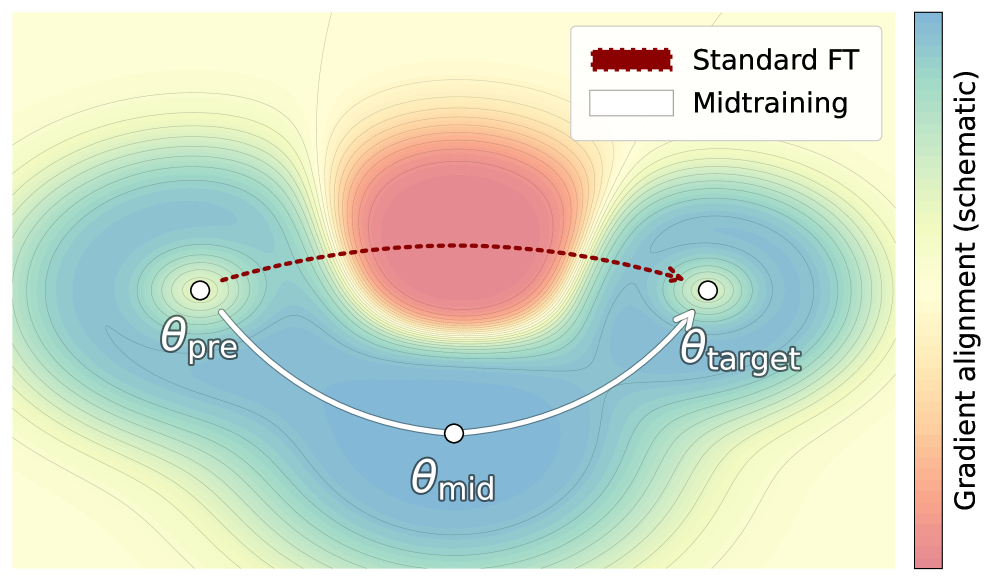
Conceptual flow of the training phases
Evaluation Highlights
- Midtraining on Starcoder (code) improves downstream CodeSearchNet loss from 2.656 (pretrain-only) to 2.504 (midtraining), outperforming continued pretraining (2.530) on 70M models
- Reduces catastrophic forgetting on C4: Math midtraining yields 6.358 C4 loss vs 6.376 for continued pretraining on 70M models (lower is better)
- Strong correlation (r=0.869) between proximity advantage (token-level similarity) and downstream performance gains for 70M models
Breakthrough Assessment
7/10
Provides the first systematic empirical and theoretical grounding for a widely used but poorly understood industry practice. Offers actionable insights on timing and data selection.