📝 Paper Summary
Scientific Machine Learning (SciML)
Spatiotemporal Surrogate Modeling
Foundation Models for Physics
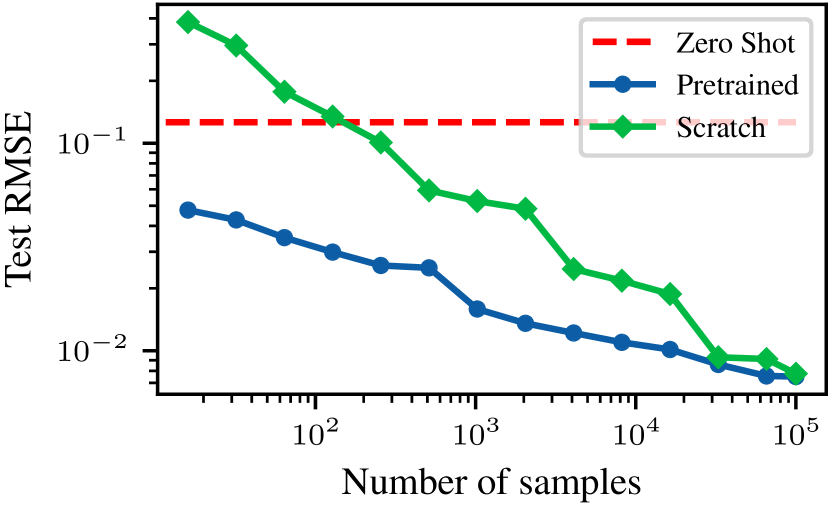
MPP trains a single transformer backbone on multiple heterogeneous physical systems simultaneously using shared embeddings and normalization to enable zero-shot prediction and efficient transfer to unseen physics.
Core Problem
Deep learning surrogates for physics are typically trained on single, specific systems, making them data-hungry and unable to transfer knowledge to new physical regimes or equations.
Why it matters:
- Training surrogates from scratch is impractical for low-data settings common in simulation-driven exploration
- Current methods fail to leverage the shared underlying principles (conservation laws, advection, diffusion) common across different PDEs
- Existing 'foundation models' in vision/language leverage massive data, but this scale has not yet been successfully applied to nonlinear spatiotemporal physics
Concrete Example:
A model trained solely on advection cannot predict diffusion, and vice-versa. To model a combined advection-diffusion system, standard approaches require training a new model from scratch, whereas MPP leverages features learned from observing advection and diffusion separately.
Key Novelty
Multiple Physics Pretraining (MPP)
- Projects diverse physical fields (pressure, velocity) from different systems into a shared embedding space using 1x1 convolutions
- Normalizes varying scales using Reversible Instance Normalization (RevIN) to allow a single backbone to process heterogeneous magnitudes
- Uses an Axial Attention backbone to efficiently process high-dimensional spatiotemporal data by attending to time and space axes independently
Architecture
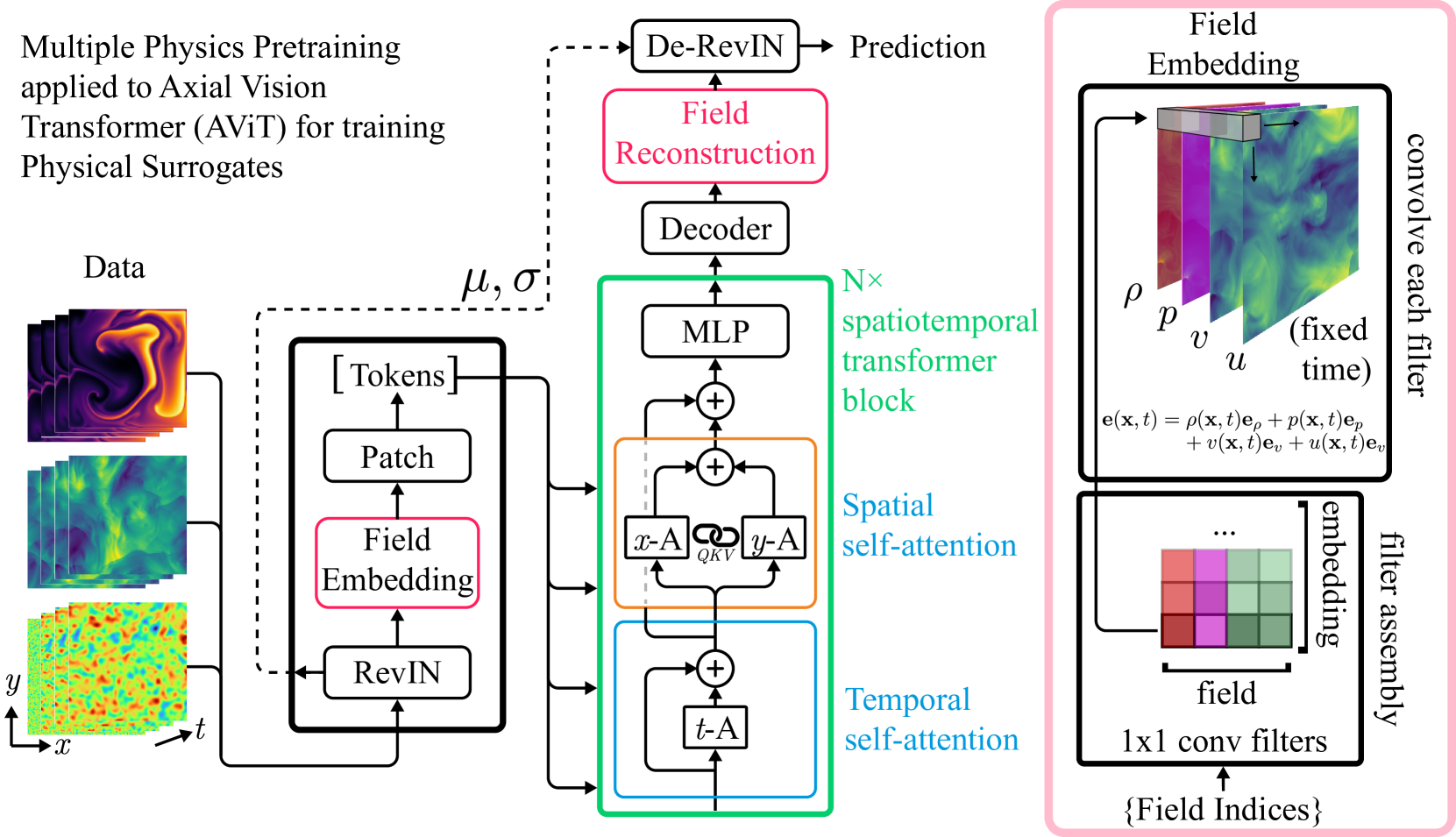
The architecture of the Multiple Physics Pretraining (MPP) transformer backbone.
Breakthrough Assessment
8/10
Proposes a viable architecture for a 'Physics Foundation Model' that handles heterogeneous inputs and scales, addressing a major bottleneck in Scientific ML. Methodologically sound, though full experimental results were not in the provided snippet.