📝 Paper Summary
Domain Adaptation
Pretraining Strategies
Continual Learning / Forgetting
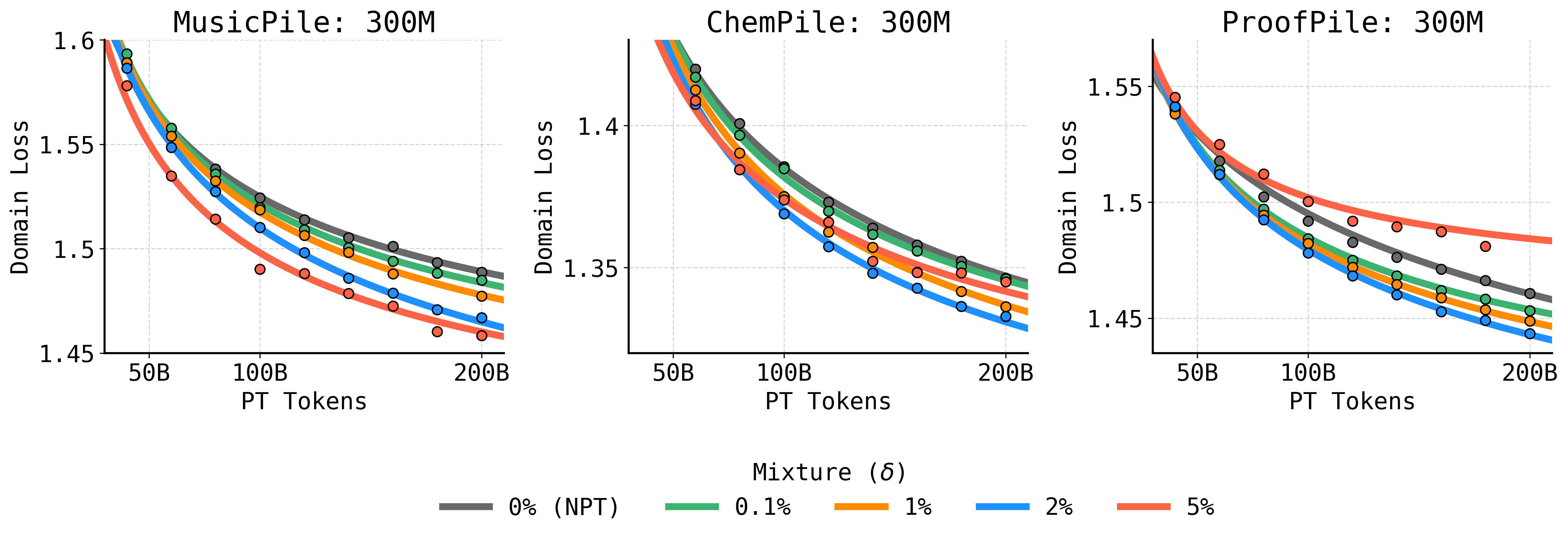
Interleaving domain-specific data throughout pretraining (Specialized Pretraining) yields better performance and less overfitting than the standard practice of reserving domain data exclusively for finetuning.
Core Problem
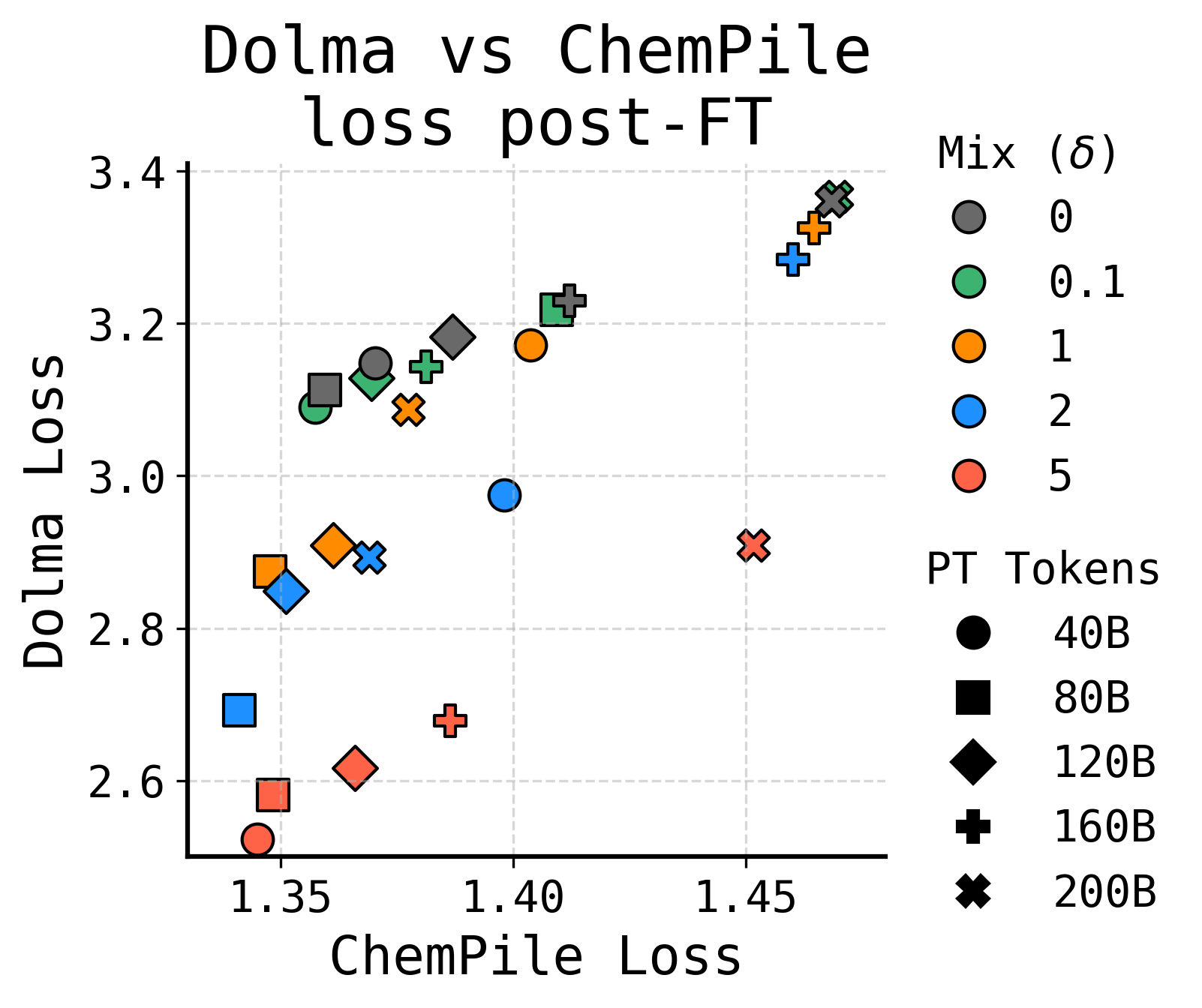
Standard domain adaptation treats pretraining and finetuning as disjoint phases, reserving specialized data for finetuning. This often leads to rapid overfitting on the small domain dataset and catastrophic forgetting of general knowledge.
Why it matters:
- Organizations often rely on finetuning for proprietary data (legal, medical), assuming it is the most efficient path, but this may yield suboptimal models compared to early data integration.
- Finetuning on small corpora requires aggressive updates that degrade general capabilities, while pretraining models from scratch is often viewed as too expensive.
- Current scaling laws do not account for the trade-offs between repeated domain data during pretraining versus finetuning.
Concrete Example:
A 1B model trained with standard pretraining (Web data) followed by finetuning on 'ProofPile' (math) overfits rapidly after ~5 epochs. In contrast, a model that sees ProofPile mixed into pretraining (SPT) sustains performance improvement for far longer and matches the performance of a 3B standard model.
Key Novelty
Specialized Pretraining (SPT)
- Mix a small fraction of domain-specific data (e.g., 2%) into the general pretraining corpus from the start, repeating it as necessary (up to ~50x), rather than saving it for finetuning.
- Derives 'overfitting scaling laws' that model test loss as a sum of learning (power law) and overfitting (gap growing with repetitions), allowing prediction of optimal data mixing ratios.
Architecture

Contrast between Naive Pretraining (NPT) and Specialized Pretraining (SPT) workflows.
Evaluation Highlights
- On the 'ProofPile' domain, a 1B parameter SPT model outperforms a 3B parameter standard model, effectively closing >100% of the performance gap.
- SPT reduces the pretraining tokens needed to reach a specific domain loss by up to 1.75x compared to standard pretraining (on MusicPile).
- Improves downstream accuracy by up to 6 percentage points on MATH and 4 percentage points on MusicTheoryBench compared to the finetuning-only baseline.
Breakthrough Assessment
8/10
Challenges the standard industry practice of 'pretrain then finetune' for domain adaptation. Provides actionable scaling laws and demonstrates that smaller, specialized models can beat larger general models.