📝 Paper Summary
LLM Quantization
Pretraining optimization
Outlier suppression
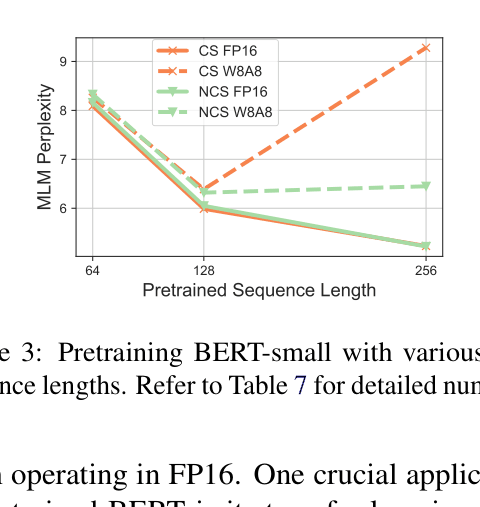
Outlier-free pretraining using clipped softmax degrades full-precision performance due to sequence length mismatch; a normalized variant (NCS) restores performance and enables effective pretraining for causal models like OPT.
Core Problem
Pretraining with 'clipped softmax' successfully removes outliers for quantization but degrades full-precision (FP16) performance and fails on causal LLMs.
Why it matters:
- Outliers in activations/weights are the main bottleneck for quantizing LLMs to low bit-widths (e.g., 8-bit or 4-bit) without accuracy loss
- Existing outlier-free pretraining methods (like Clipped Softmax) make models quantization-friendly but hurt their standard performance on downstream tasks
- Standard Clipped Softmax is sensitive to sequence length, causing a mismatch between pretraining (fixed length) and inference/finetuning (variable length)
Concrete Example:
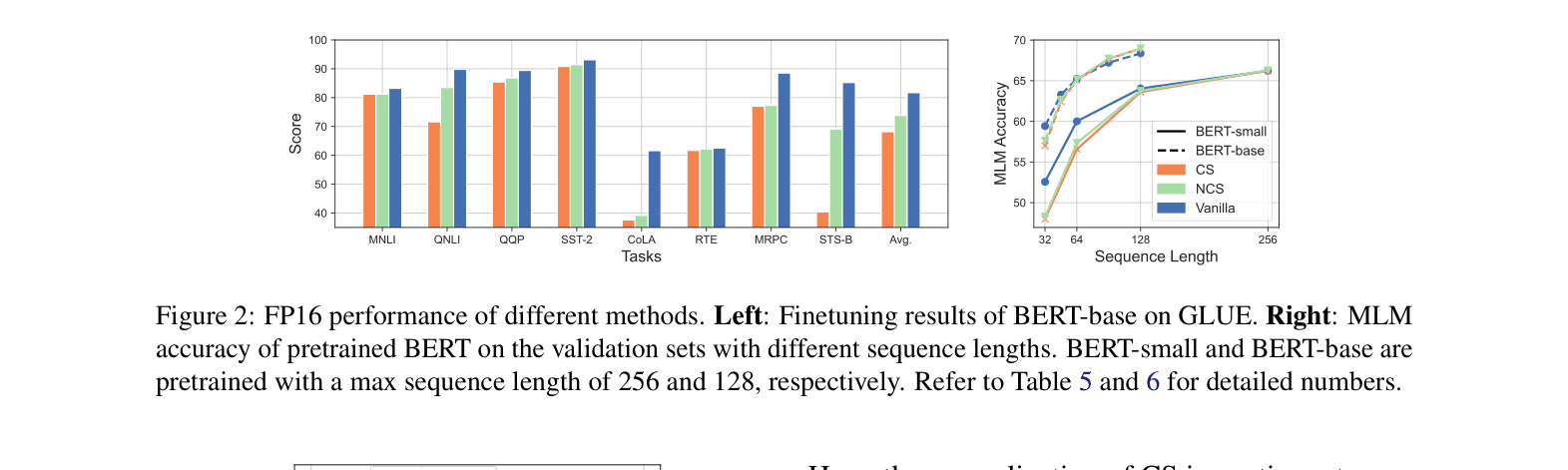
A BERT model pretrained with Clipped Softmax (CS) sees a massive drop in GLUE scores (avg 68.1) compared to a vanilla BERT (avg 81.7) because the CS normalization depends on sequence length, distorting attention probabilities when lengths change during finetuning.
Key Novelty
Normalized Clipped Softmax (NCS)
- Modifies the clipped softmax function to use a normalization term that is invariant to sequence length, unlike the original method where normalization fluctuated with length
- Ensures the product of attention probability and value matrix remains consistent between pretraining and downstream tasks with varying sequence lengths
- Adapts the normalization for causal attention (OPT) by accounting for the varying context length of tokens within the lower-triangular attention mask
Architecture
Mathematical formulation of the Clipped Softmax (CS) and Normalized Clipped Softmax (NCS)
Evaluation Highlights
- Recovered FP16 performance: NCS improves average GLUE score from 68.1 (CS) to 73.8, significantly closing the gap with vanilla BERT (81.7)
- Successful causal model quantization: On OPT-125M, NCS achieves W8A8 perplexity of 18.33, beating both Vanilla (21.18) and standard CS (37.20)
- Reduced sensitivity: NCS maintains consistent pretraining performance across different maximum sequence lengths (64 to 256), whereas standard CS fluctuates
Breakthrough Assessment
4/10
Identifies a critical flaw in prior outlier-free pretraining (length sensitivity) and proposes a fix. While it improves quantization for causal models, it still lags behind vanilla models in full-precision finetuning.