📝 Paper Summary
Offline Reinforcement Learning
Representation Learning for Control
Self-Supervised Learning
SMART pretrains a reward-agnostic transformer on diverse control tasks using a mix of short-term dynamics prediction and long-term masked action recovery to enable efficient downstream policy learning.
Core Problem
Pretraining for sequential decision-making faces challenges like distribution shift, lack of shared semantics across diverse tasks, and the need to capture both short-term dynamics and long-term planning without reliable rewards.
Why it matters:
- Standard pretraining from vision/language (like BERT or CLIP) doesn't transfer well to control because it misses decision-critical dynamics.
- Learning control policies from scratch is sample-inefficient and requires expensive high-quality data.
- Existing methods often rely on reward signals during pretraining, making them brittle when downstream tasks have different or missing rewards.
Concrete Example:
A robot arm trained to 'stack blocks' using reward-based pretraining might fail completely if the downstream task changes to 'push blocks,' because its representation is overfitted to the specific 'stacking' reward rather than understanding the physics of the arm and blocks.
Key Novelty
Control-Centric Self-Supervised Objective
- Decouples representation learning from policy learning by removing rewards from the input sequence, making the model versatile for both Imitation Learning and Reinforcement Learning.
- Combines short-term physics understanding (predicting the next state) with long-term planning capability (masking random actions in a sequence and asking the model to fill them in, effectively asking 'what did I do to get here?').
Architecture
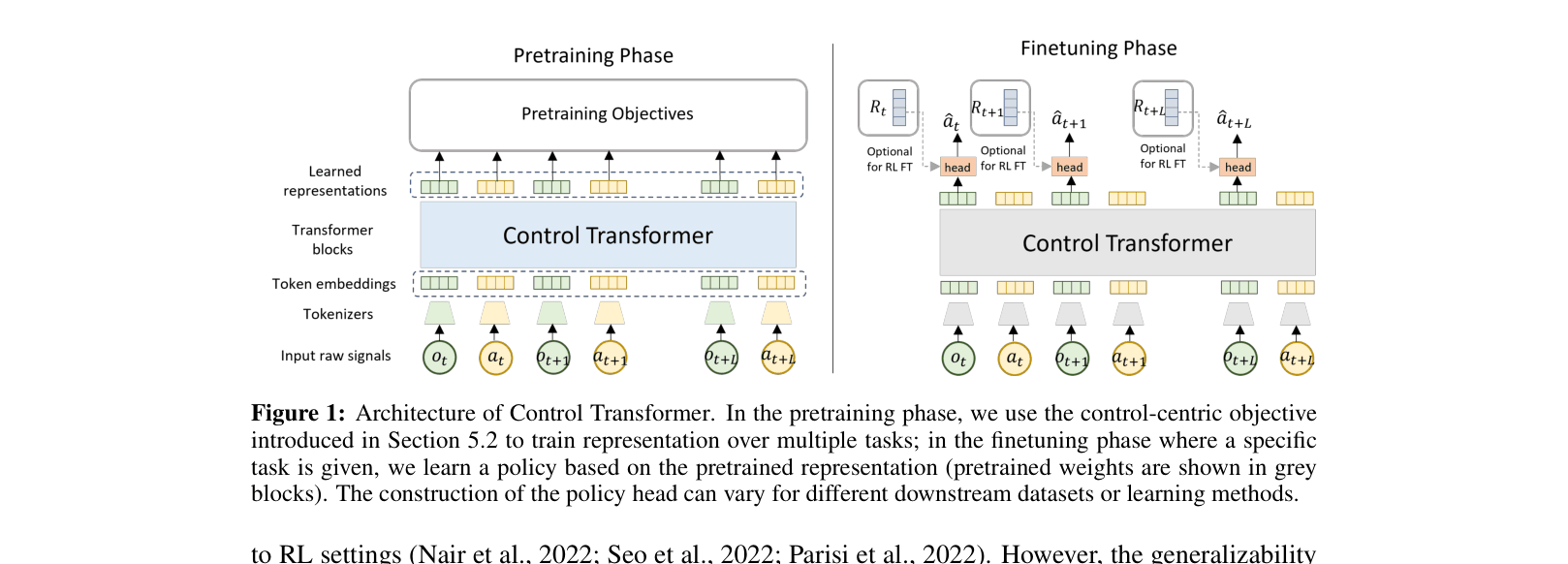
The Control Transformer architecture showing the pretraining vs. fine-tuning phases.
Evaluation Highlights
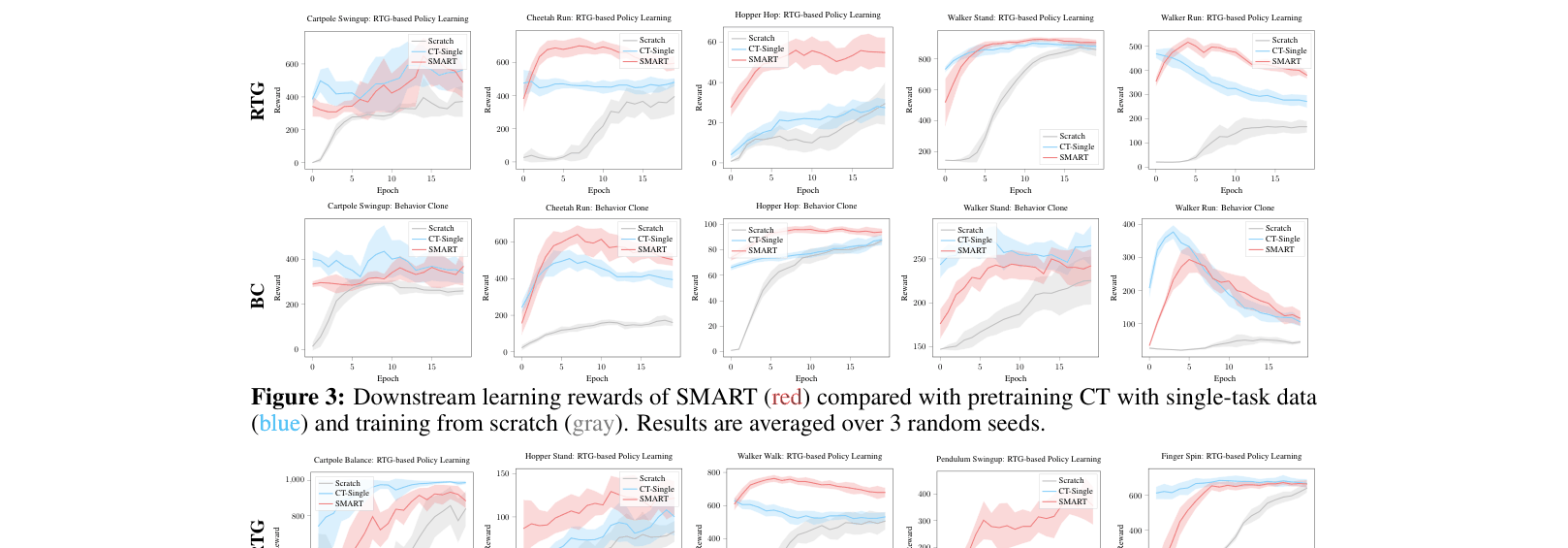
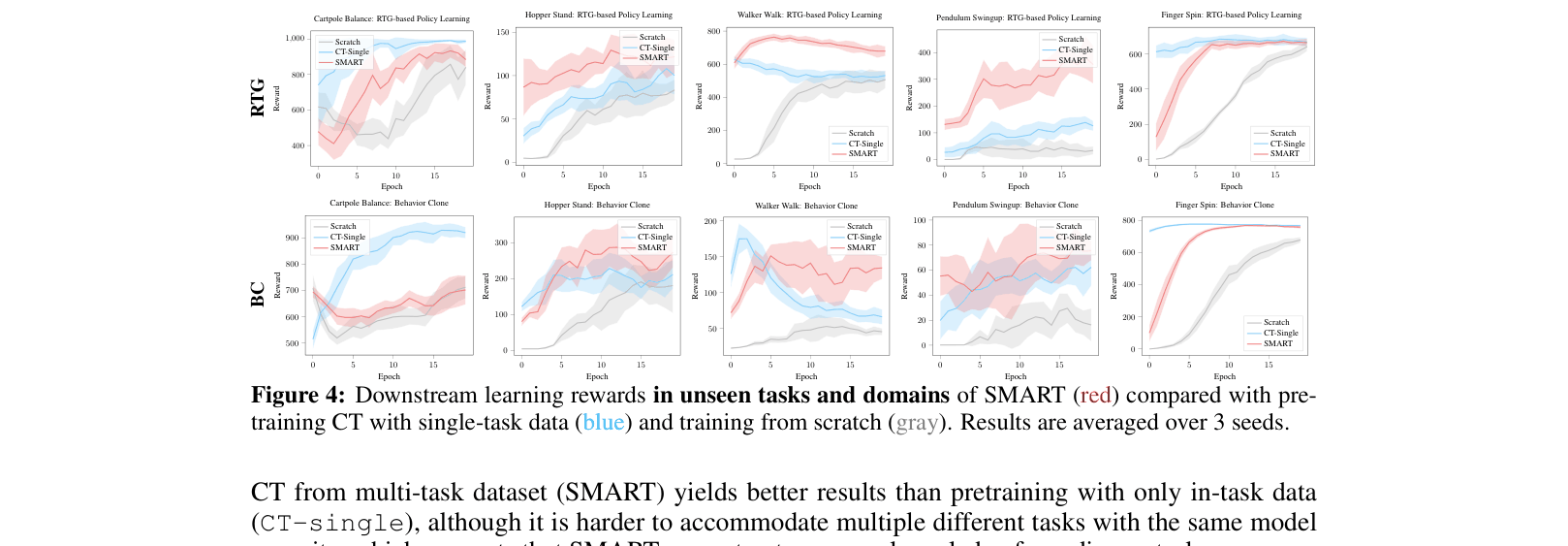
- Outperforms training from scratch and single-task pretraining on 10 DeepMind Control tasks, including 5 unseen tasks and 2 unseen domains.
- Achieves higher normalized reward than ACL and Decision Transformer when pretrained on low-quality 'Random' datasets, demonstrating resilience to poor data quality.
- Generalizes to unseen domains (e.g., pendulum-swingup) better than baselines that have seen the environment but not the specific task.
Breakthrough Assessment
7/10
Strong empirical results on generalization and resilience to data quality. The separation of reward-free pretraining from downstream policy learning is a valuable step towards generalist agents, though tested primarily on DMC benchmarks.