📝 Paper Summary
Distributed Training
Small Language Models (SLMs)
Pipeshard parallelism significantly outperforms data parallelism for pretraining small language models on geographically distributed academic GPU clusters by effectively masking high network latency.
Core Problem
Pretraining language models typically requires expensive, low-latency clusters; academic users relying on free, geo-distributed testbeds (like FABRIC) face high network latency that degrades standard distributed training performance.
Why it matters:
- Academic researchers cannot afford the massive compute budget or low-latency interconnects (like NVLink) used by industry for LLM training
- Standard data parallelism fails or becomes prohibitively slow when GPU nodes are separated by wide-area networks (10ms+ latency)
- Domain-specific vector databases require custom embeddings from models pretrained on specialized datasets, necessitating accessible pretraining methods for SLMs
Concrete Example:
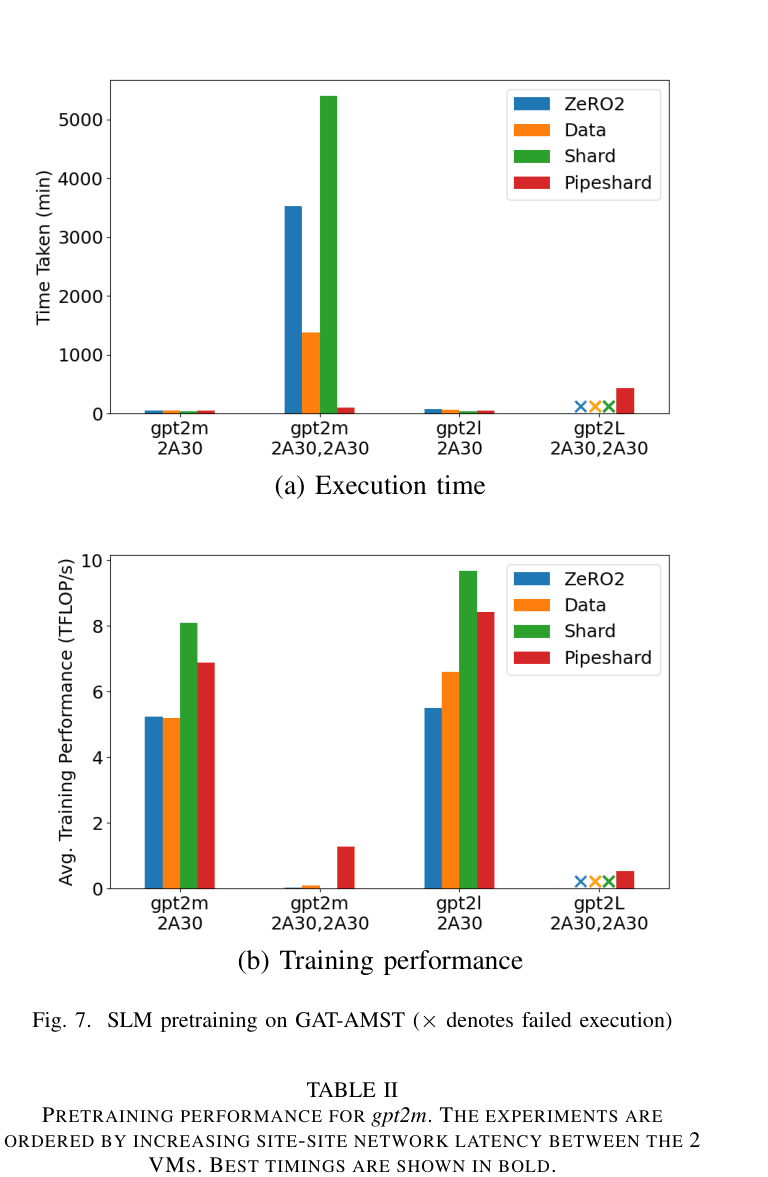
When training GPT-2 on a cluster spanning Utah and Amsterdam (103ms latency), standard Data Parallelism takes 1,375 minutes for 20 epochs due to synchronization overhead, whereas the proposed Pipeshard approach finishes in 100 minutes.
Key Novelty
Empirical Strategy Selection for Geo-Distributed Pretraining
- Demonstrates that Alpa's Pipeshard (combining intra-operator and pipeline parallelism) tolerates high network latency (10-100ms) far better than Data Parallelism or ZeRO
- Proposes a heuristic algorithm to dynamically select the best parallelization strategy (Data vs. Pipeshard) based on cluster topology and measured throughput
Architecture
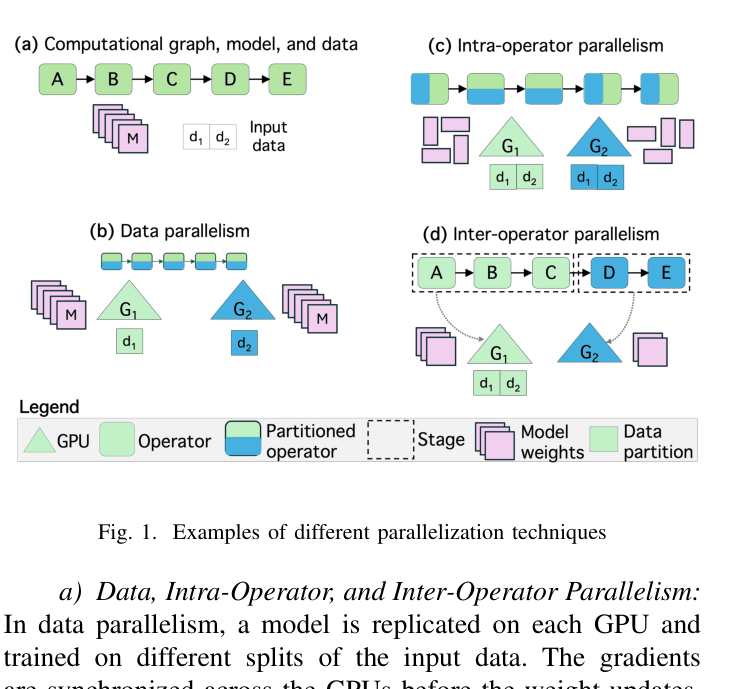
Conceptual illustration of different parallelization techniques: Data, Intra-Operator, and Inter-Operator (Pipeline) parallelism
Evaluation Highlights
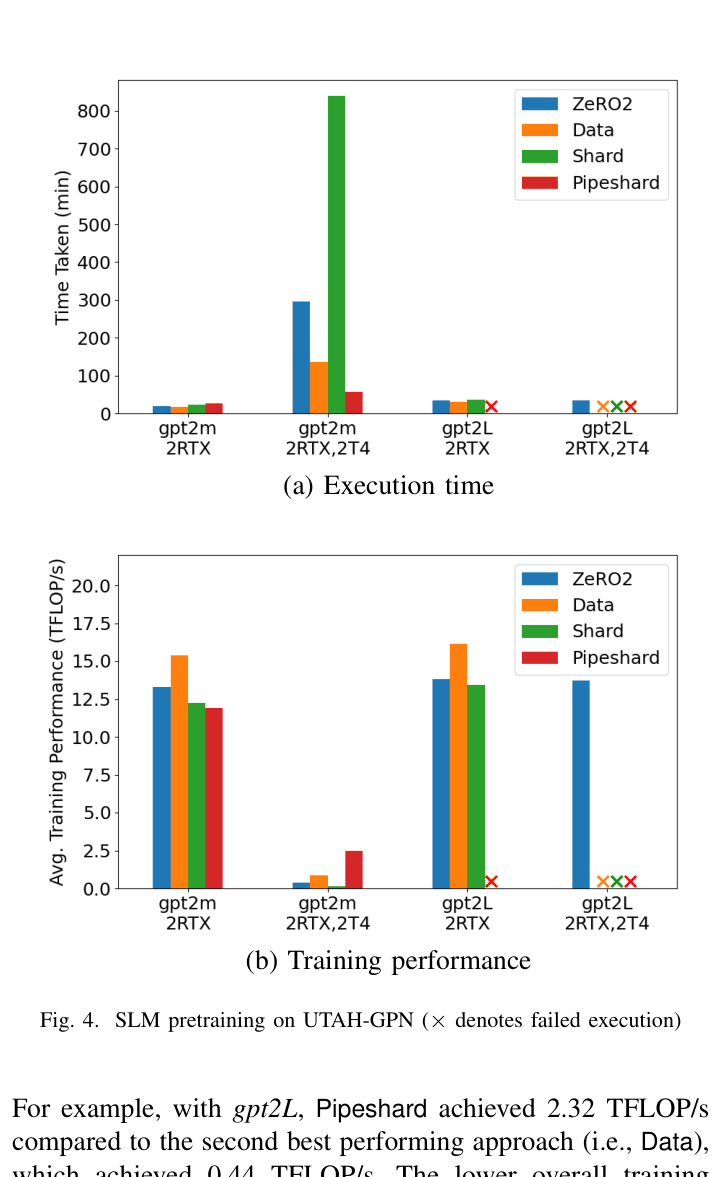
- Pipeshard achieves 13.7x speedup (100 min vs 1,375 min) over Data Parallelism for GPT-2 Medium on a cross-continent cluster (103ms latency)
- On a US-based distributed cluster (20ms latency), Pipeshard reaches 2.49 TFLOP/s compared to Data Parallelism's 0.88 TFLOP/s
- Pipeshard successfully trains GPT-2 Large on heterogeneous hardware where Data and Shard parallelism fail due to Out-Of-Memory errors
Breakthrough Assessment
5/10
A solid empirical study offering practical guidelines for academic pretraining on suboptimal hardware. While not an algorithmic breakthrough, it validates existing tools (Alpa) in a novel, resource-constrained environment.