📝 Paper Summary
LLM Finetuning
Scaling Laws
Catastrophic Forgetting
Injecting as little as 1% of pretraining data during finetuning prevents forgetting, governed by a precise multiplicative scaling law involving model size, dataset size, and mixture fraction.
Core Problem
Finetuning LLMs on small target datasets causes two major issues: rapid overfitting to the target domain and catastrophic forgetting of general pretraining knowledge.
Why it matters:
- Specialized models are essential for specific tasks, but losing general capabilities (forgetting) limits their versatility and robustness
- Current practices for mixing pretraining data are heuristic; practitioners lack a principled way to determine the optimal mixture ratio
- Existing scaling laws focus on pretraining or simple finetuning performance, ignoring the precise dynamics of forgetting and data mixing
Concrete Example:
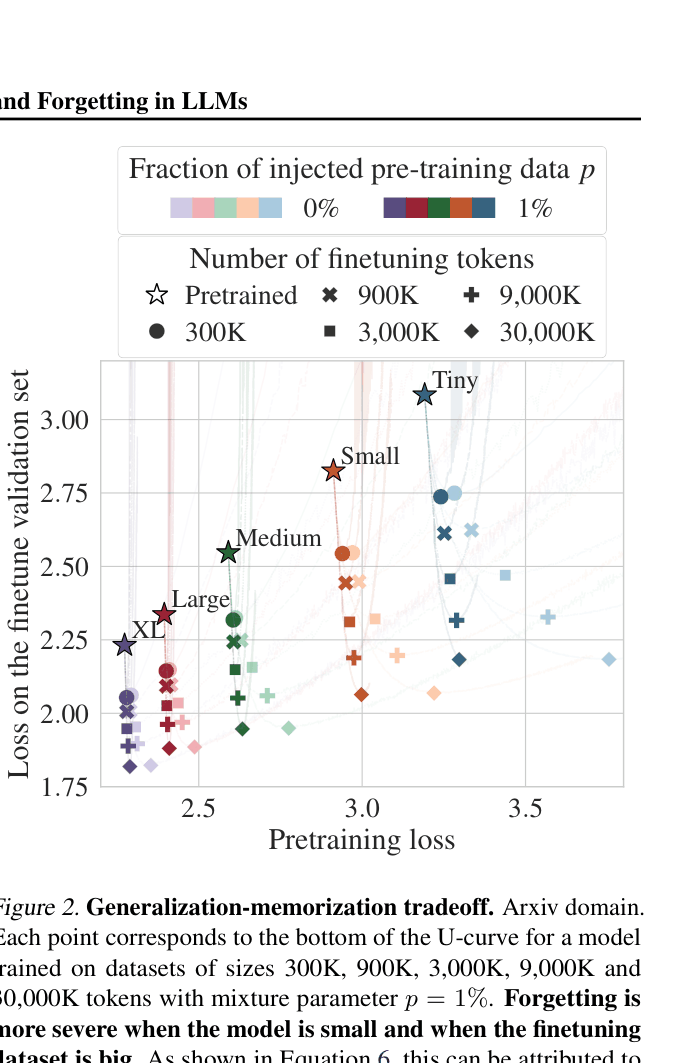
When finetuning a Small (109M) model on the 'Arxiv' domain, the pretraining loss increases significantly (forgetting). However, injecting just p=1% of pretraining data keeps the pretraining loss nearly flat, preserving general knowledge without hurting target performance.
Key Novelty
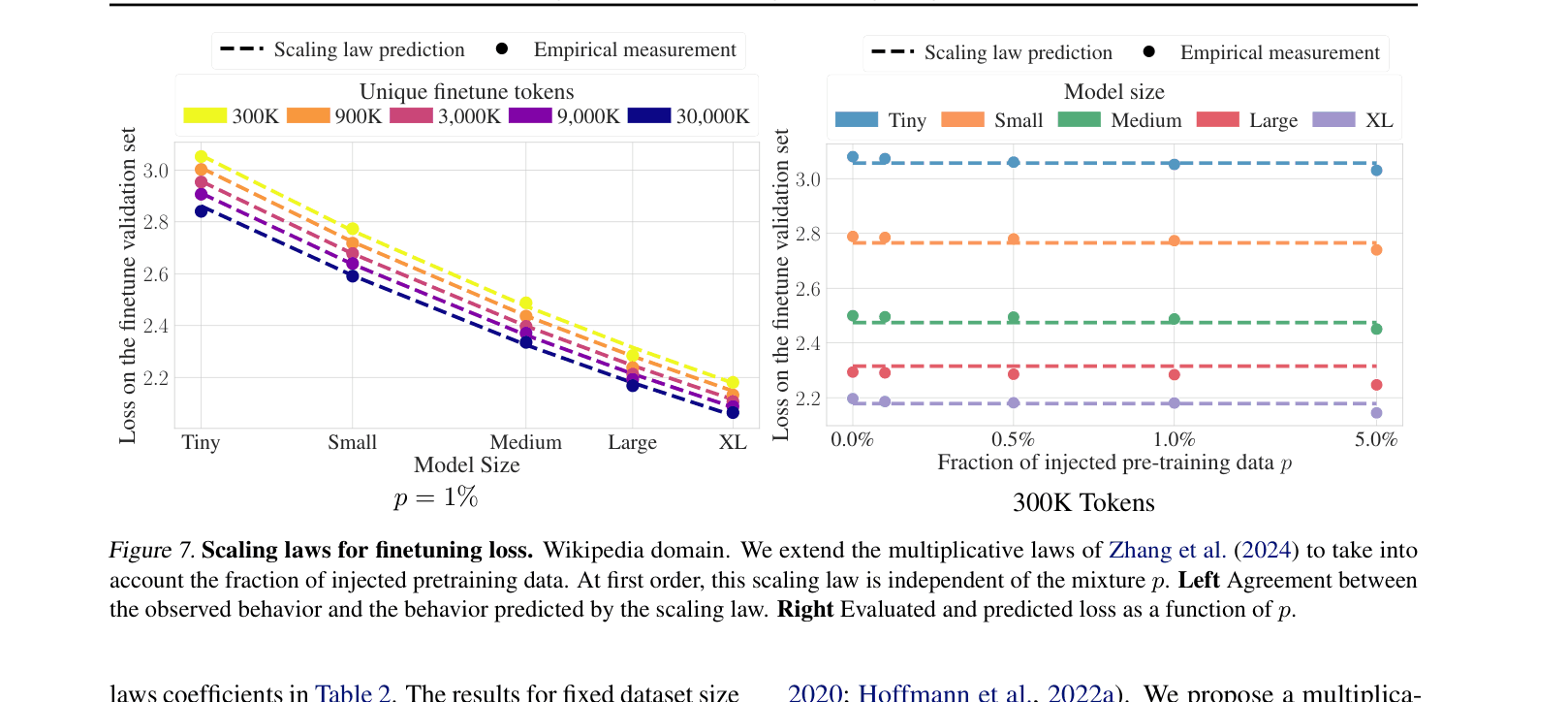
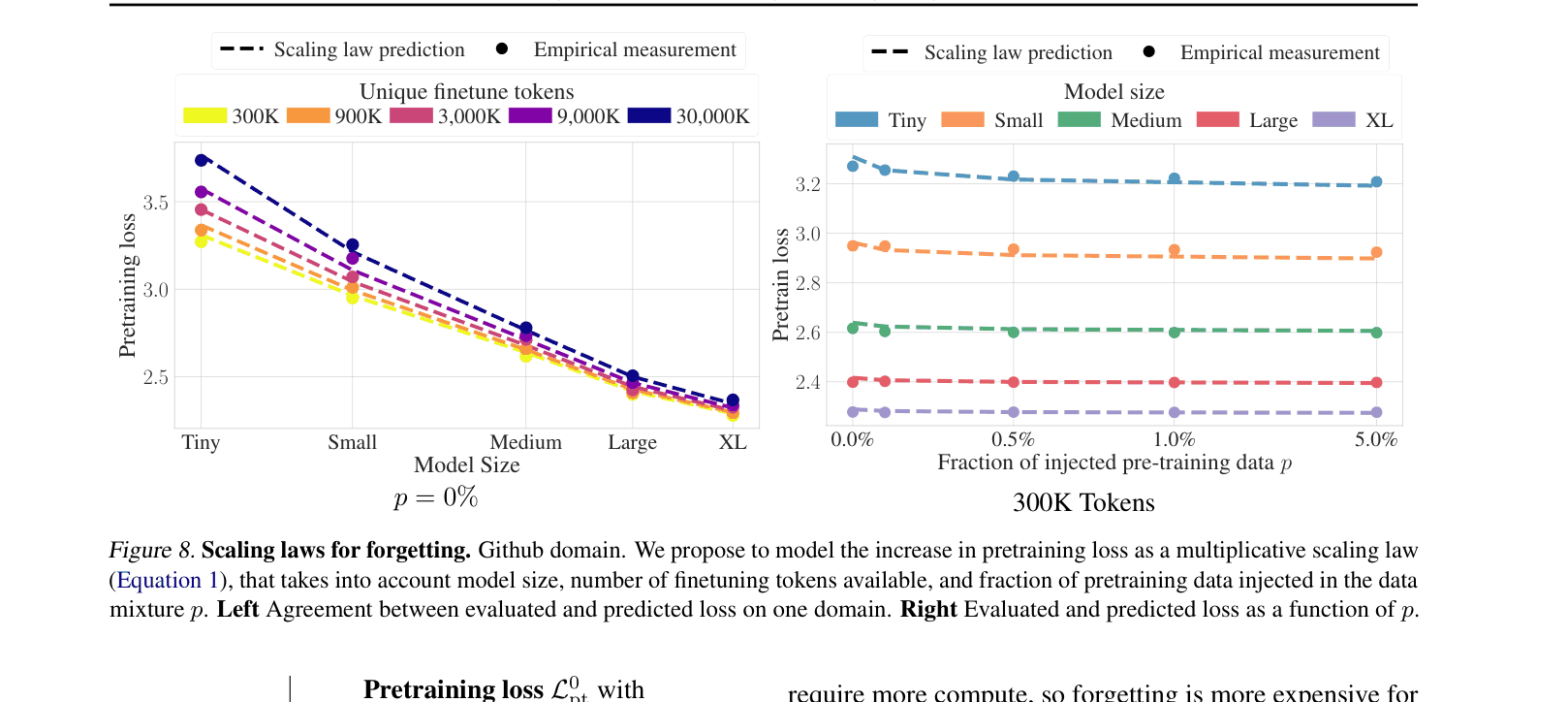
Scaling Law for Forgetting with Data Injection
- Derives a multiplicative scaling law predicting the pretraining loss after finetuning based on model size, finetuning tokens, and injection ratio
- Demonstrates that pretraining data injection acts as a regularizer, where effective parameters for the pretraining task scale with (1 + Bp)N
- Identifies that forgetting is primarily a capacity allocation issue: smaller models suffer most because they lack spare capacity to maintain old knowledge while learning new tasks
Architecture
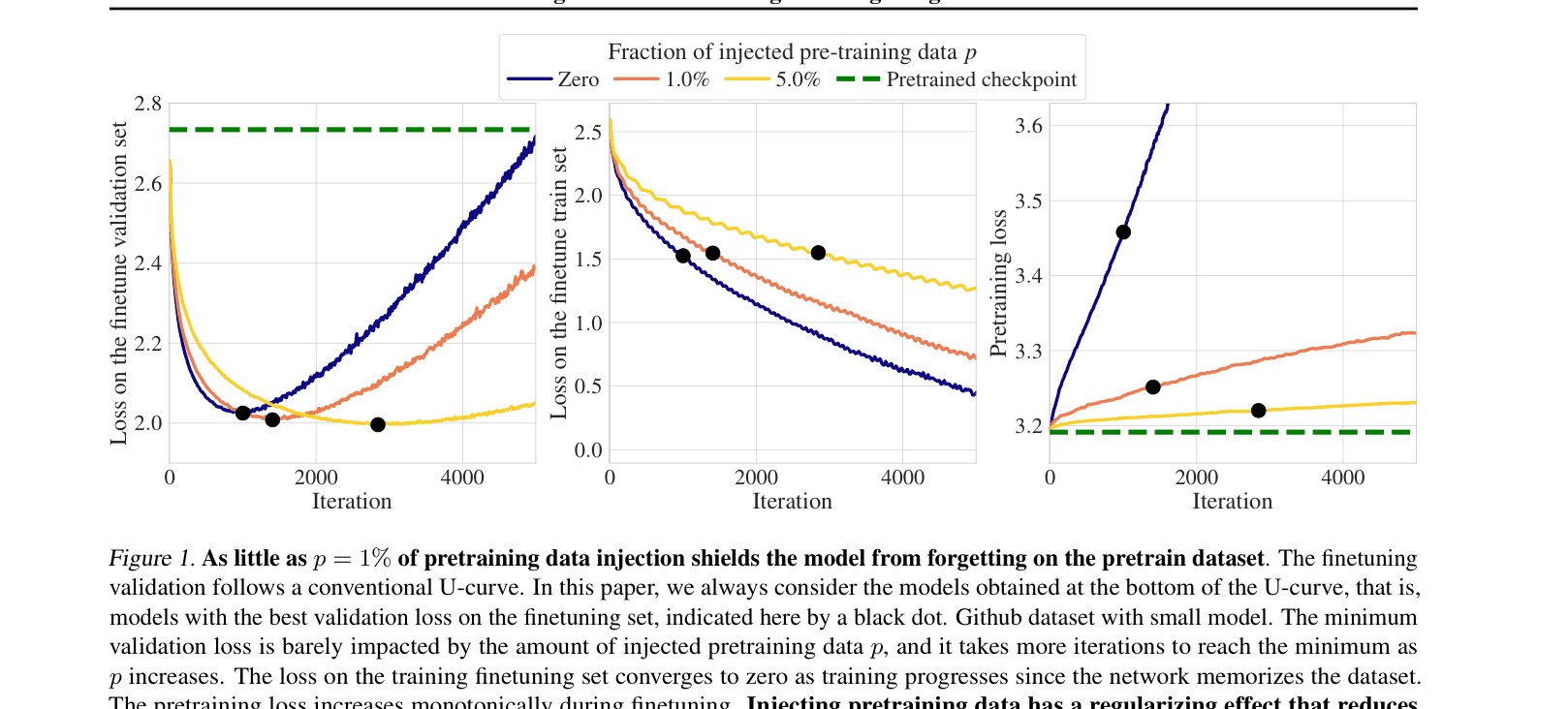
Evolution of Finetuning Validation Loss, Train Loss, and Pretraining Loss (Forgetting) during training iterations for different mixture fractions p.
Evaluation Highlights
- Mixing just p=1% of pretraining data effectively halts forgetting across all 12 domains and 5 model scales tested
- The proposed scaling law predicts forgetting with a Bootstrapped Mean Relative Error (MRE) of just 0.40% across domains
- Small models (Tiny, 41M) lose up to 95% of pretraining progress during finetuning, while Large models (XL, 1.27B) lose only ~20%, confirming capacity dependence
Breakthrough Assessment
8/10
Provides the first precise scaling law quantifying the impact of pretraining data injection on forgetting. The finding that 1% injection is sufficient is a highly practical rule of thumb.