📝 Paper Summary
Language Model Pretraining
Transformer Optimization
ProRes stabilizes Transformer pretraining by multiplying residual connections with a time-dependent scalar that warms up sequentially from shallow to deep layers, ensuring deeper layers only contribute once upstream representations stabilize.
Core Problem
Standard Transformers allow all layers to modify representations simultaneously from initialization, causing deeper layers to update based on unstable, noisy features from shallow layers.
Why it matters:
- Deep layers injecting noise early in training skews gradient signals for shallow layers, leading to inefficiency
- Uniform update constraints designed for initialization (like DeepNorm) are overly conservative during the stable training phase, limiting model capacity
- Shallow layers naturally converge earlier than deep layers, but standard optimization ignores this heterogeneity
Concrete Example:
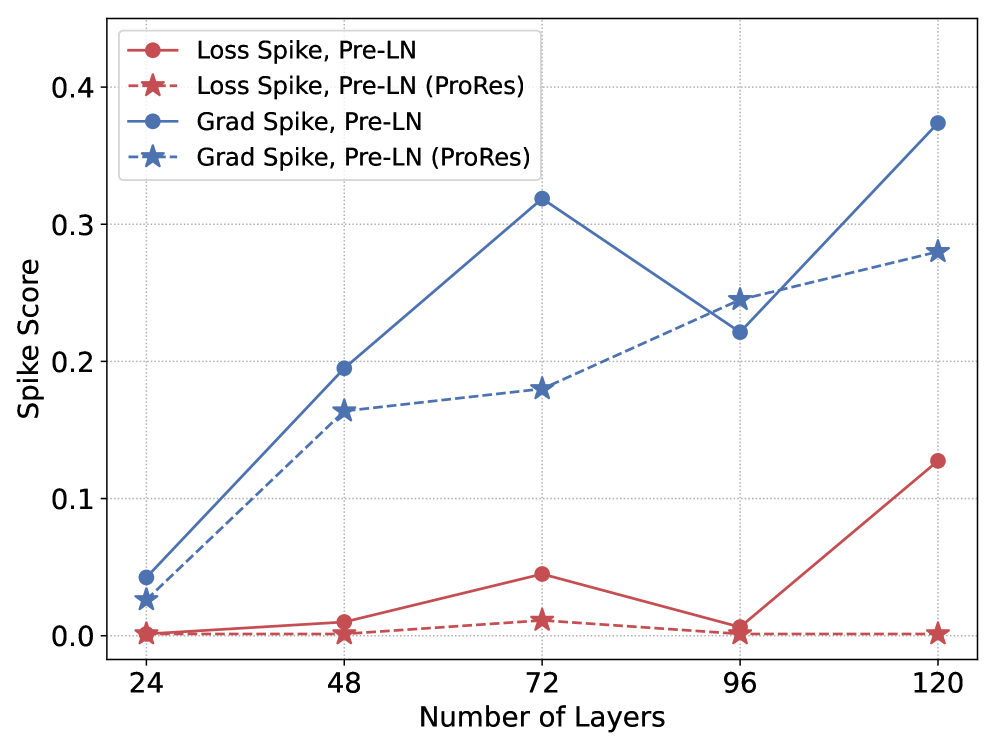
In a 24-layer model at step 100, Layer 24 receives chaotic inputs from Layer 1. If Layer 24's residual branch is fully active, it attempts to learn patterns from this noise, destabilizing the backward pass. ProRes keeps Layer 24's residual near zero at step 100, forcing identity mapping until Layer 1 settles.
Key Novelty
Progressive Residual Warmup (ProRes)
- Multiplies each residual block output by a scalar that linearly increases from 0 to 1 during training
- Applies a depth-dependent schedule where shallow layers warm up quickly and deeper layers wait longer, enforcing an 'early layer learns first' order
Architecture
Conceptually, the figure/equation illustrates the modified residual connection where the output of the sub-layer is multiplied by alpha(l,t).
Evaluation Highlights
- Reduces perplexity by 0.16 on C4-en for a 1.3B Post-LN model compared to standard Post-LN baseline
- Improves average accuracy on reasoning benchmarks (e.g., PIQA, HellaSwag) by ~1.27% across architectures, with up to +2.89% on LAMBADA
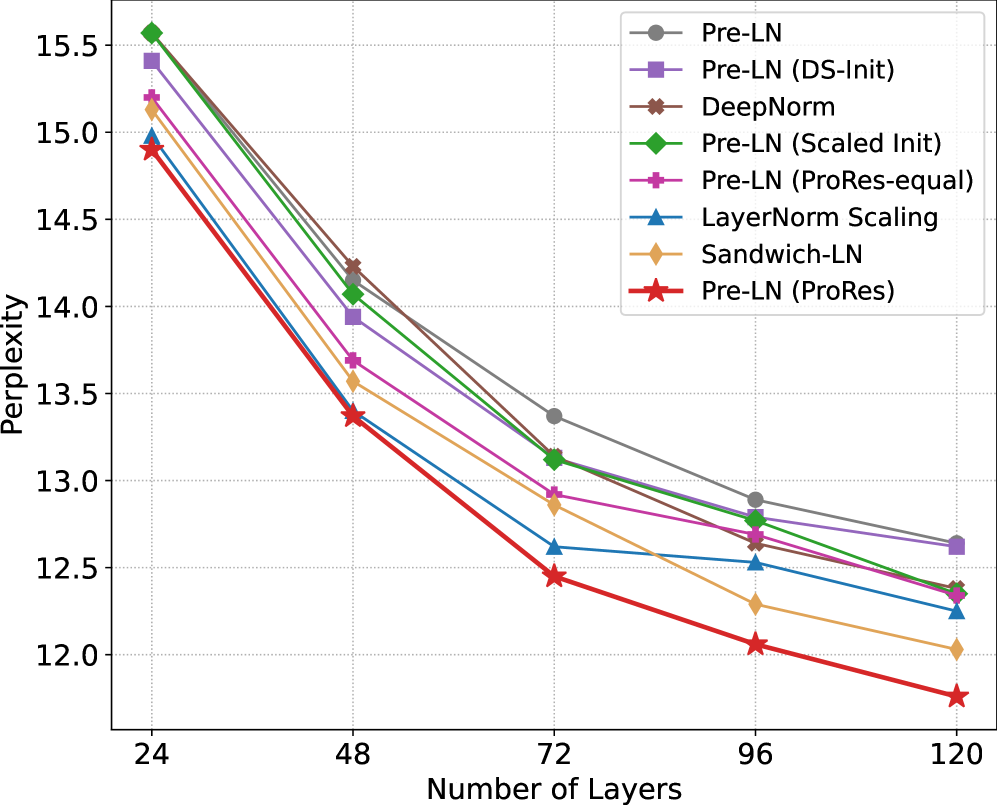
- Enables stable depth scaling up to 120 layers for Pre-LN models, outperforming DeepNorm and LayerNorm Scaling in perplexity at depth
Breakthrough Assessment
7/10
A simple, architecture-agnostic modification that consistently improves stability and performance across scales and normalization types. While not a fundamental architectural shift, it offers a robust optimization fix for deep Transformers.