📝 Paper Summary
Time Series Representation Learning
Self-Supervised Learning
Transfer Learning
XIT is a self-supervised time series pretraining framework that leverages a new interpolation method (XD-MixUp) and loss function (SICC) to effectively learn a shared representation across 75 diverse datasets.
Core Problem
Pretraining on multiple diverse time series datasets typically fails or degrades performance compared to single-source training due to significant domain mismatches and varying temporal dynamics.
Why it matters:
- Real-world time series tasks often lack sufficient labeled data (e.g., healthcare privacy constraints), making supervised learning difficult.
- Existing methods generally require source and target domains to be very similar, limiting the utility of large collections of unlabeled data.
- Common belief holds that multi-dataset pretraining for time series is ineffective, unlike in NLP or Vision where it is standard practice.
Concrete Example:
The UCR/UEA archive contains many small datasets (57% have <300 samples). If a model is pretrained on dataset A (e.g., ECG) and finetuned on dataset B (e.g., traffic), performance usually drops because standard contrastive losses push the learned clusters of A and B far apart, preventing positive transfer.
Key Novelty
XIT (XD-MixUp + SICC + Temporal Contrasting)
- Uses 'XD-MixUp' (Cross-Dataset MixUp) to interpolate between time series from different datasets/clusters, creating bridge samples in the latent space.
- Introduces 'SICC' (Soft Interpolation Contextual Contrasting) loss, which aligns the representation of interpolated samples proportionally to their mixing coefficient, rather than treating them as hard negatives.
- Combines these with temporal contrasting to ensure the model learns both specific temporal dynamics and a shared, generalized latent structure across diverse domains.
Architecture
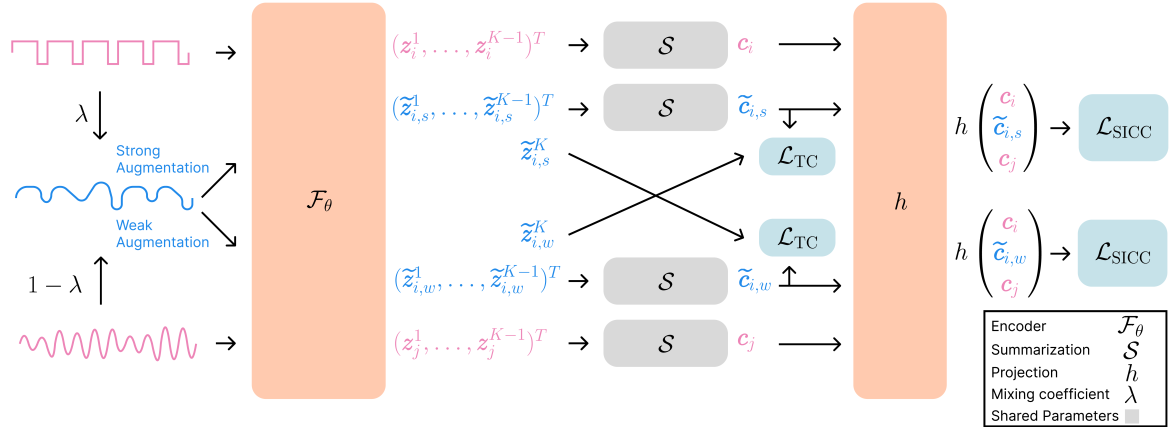
The XIT pretraining architecture. It illustrates the XD-MixUp process, augmentation, encoding, and the calculation of the two losses (TC and SICC).
Evaluation Highlights
- Outperforms supervised training and other self-supervised methods (SimCLR, TS-TCC) when pretrained on 75 datasets and finetuned on small target datasets.
- Disproves the common belief that multi-dataset pretraining does not work for time series by successfully combining up to 75 UCR datasets.
- Demonstrates effective transfer learning even in low-data regimes where target datasets have very few labeled samples.
Breakthrough Assessment
8/10
Challenge fundamental assumption in time series learning (that multi-dataset pretraining fails) and propose a working solution. Methodological novelty is high (SICC loss), though evaluation is currently limited to UCR archive.