📝 Paper Summary
Predictive Maintenance
Machine Health Monitoring
FaultFormer adapts transformer models to bearing fault classification using Fourier-based tokenization and masked self-supervised pretraining to enable generalization to new faults and machinery with scarce data.
Core Problem
Deep learning models for bearing fault detection typically require large amounts of labeled data and fail to generalize when deployed on new machinery or unseen fault types.
Why it matters:
- Unplanned machine downtime costs Fortune Global 500 companies 1.5 trillion dollars annually due to reactive maintenance strategies
- Current deep learning approaches (CNNs, RNNs) lack generalizability, requiring expensive data collection and retraining for every new machine or fault condition
- Labeling mechanical data is difficult and expensive due to the need for real-world failure experiments
Concrete Example:
A model trained to detect inner race faults on one motor setup often fails to identify outer race faults or faults on a completely different machine because it overfits to the specific vibration characteristics of the training environment.
Key Novelty
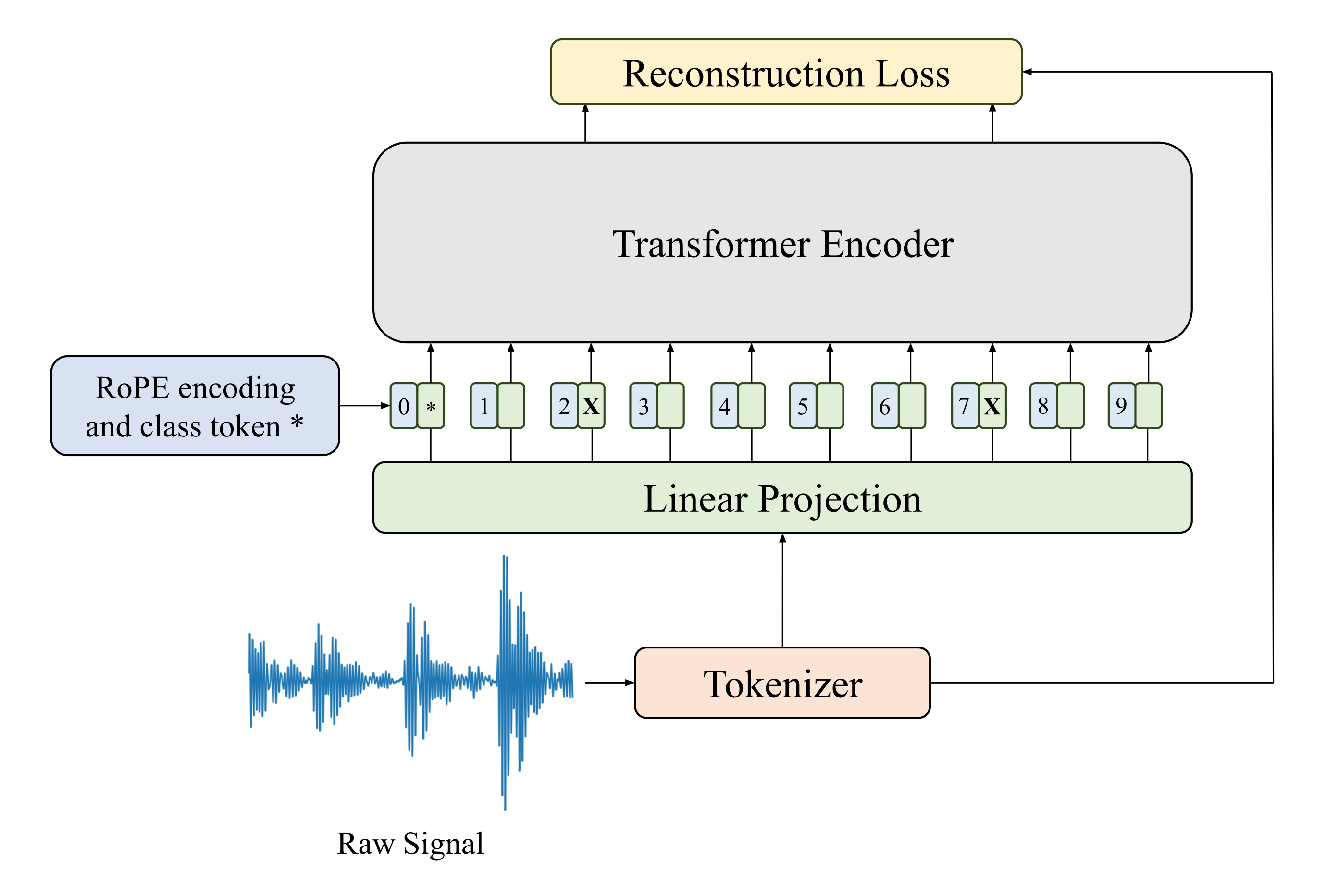
Masked Pretraining for Vibration Signals (FaultFormer)
- Treats vibration signals like language tokens by converting them into Fourier modes, allowing a transformer to learn global signal context
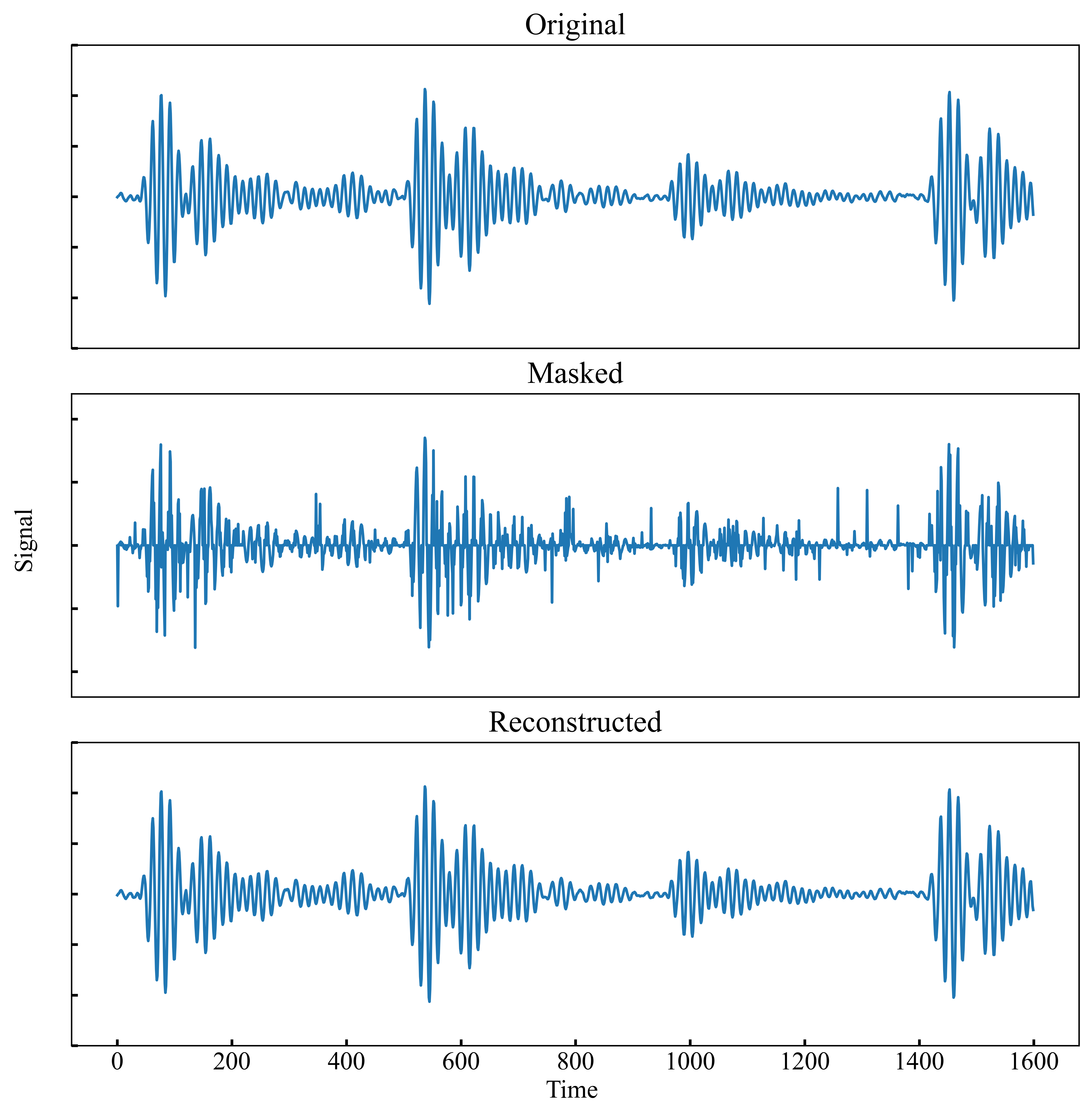
- Uses a 'masked autoencoder' approach where random parts of the vibration signal are hidden, and the model must reconstruct them, learning robust features without labels
- Fine-tunes this pretrained 'understanding' of vibration physics to quickly adapt to new datasets or fault types with very few labeled examples
Architecture
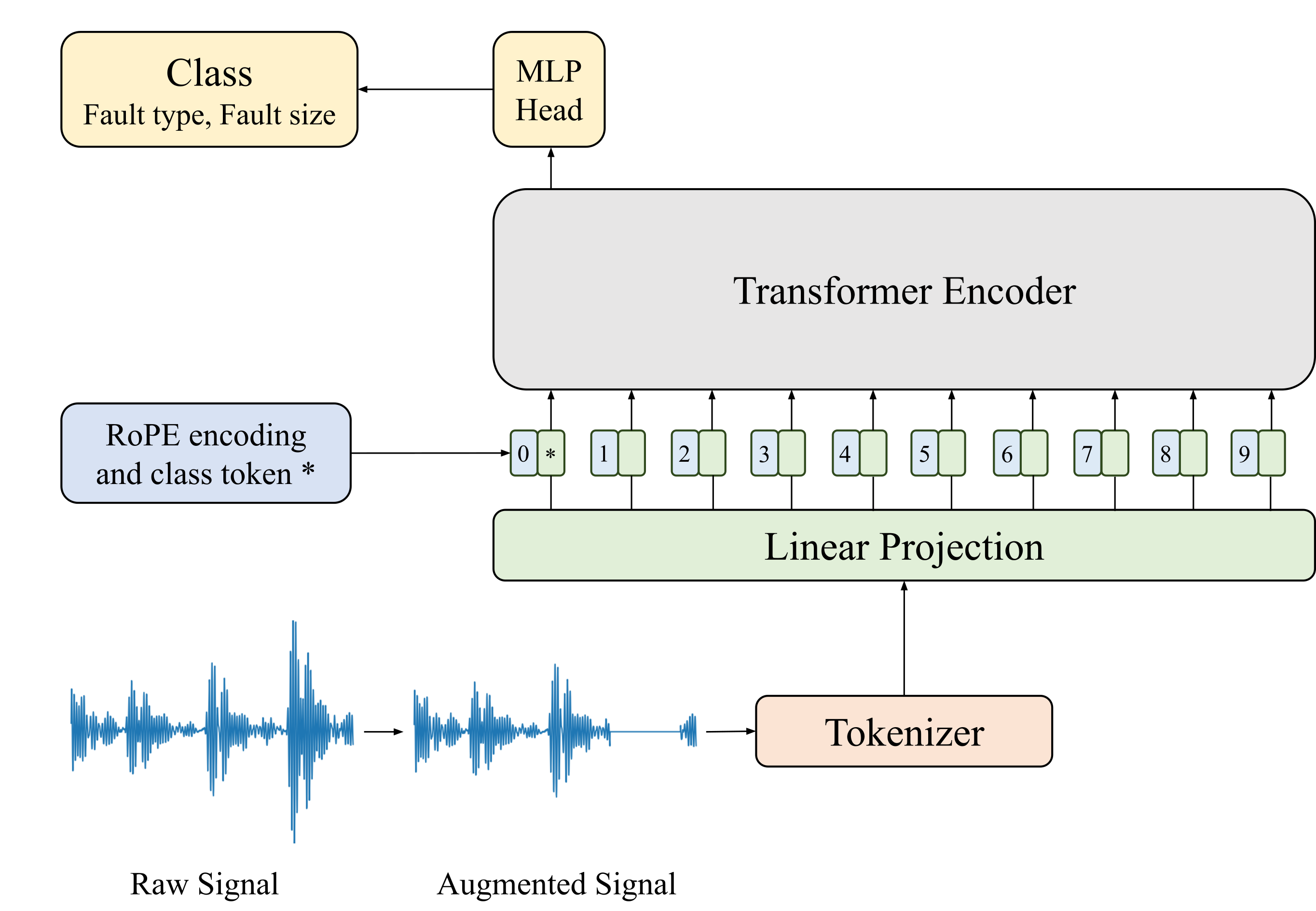
Overview of the FaultFormer architecture including the pretraining (masked reconstruction) and fine-tuning (classification) pipelines.
Evaluation Highlights
- Outperforms CNN/LSTM baselines by ~3-4% accuracy in low-data regimes (100 training samples) on the CWRU dataset
- Achieves >90% accuracy on the Paderborn dataset after only 2 epochs of fine-tuning when pretrained on CWRU data, which is 5x faster than training a CNN from scratch
- Demonstrates effective transfer learning: pretraining on 'healthy/inner/outer/ball' faults allows accurate classification of unseen fault sizes
Breakthrough Assessment
7/10
Strong application of established NLP techniques (masked pretraining, transformers) to a new domain (vibration analysis). Demonstrates significant practical value in few-shot and cross-domain generalization.